Java学习正则表达式初见
今天小编学习了正则表达式,在我看来,正则表达式是一个让人又爱又恨的东西,学会的人如果用的得心应手的话,那便会如虎添翼,用的不好,起码看得懂的人也能正常使用,如果学不会的人则会有很多不便之处!
正则
正则表达式是用来描述具有一定特征的字符串的特殊字符串。
入门示例

作用
平常用不到,但用到的话则可以用来验证、查找、替换、分割。
验证工具
正则表达式验证工具 RegexBuddy 小编已经上传,需要的人可以自行下载哦~
字符集
默认情况下区分大小写。
普通字符
非特殊含义以外的字符,如 a b 中国 上海 北京 。 普通字符精确匹配。
元字符与转义

字符类
自定义
由 [ ] 方括号组成,只匹配一个, 需要注意以下四个:
^ : 如果在第一个位置,表示取反的含义。
- :表示一个区间即范围
] : 最近一个位置为:结束 ,如果要表示普通的 ] 请加 \
\ \ : 转义
. 在字符类中不是代表任意的字符, 如果需要表示原有的含义,挪动位置或者加 \
默认标准字符类
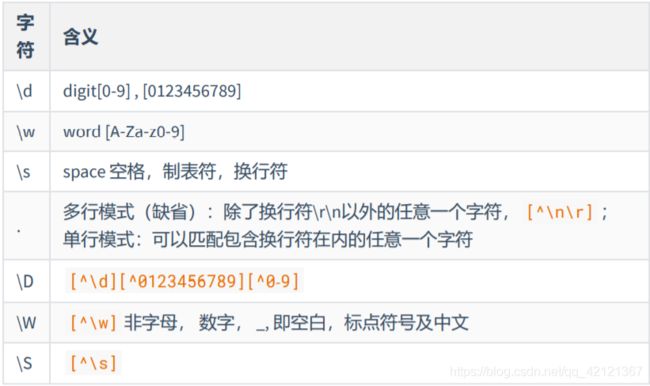
举例
h[ea]llo –>hello hallo
h(e|a)llo ->hello hallo
[\-\\abc] -> - \ a b c
\d\s ->一个数字和一个空白
[\d\s] –> 数字 或 空白
量词
匹配的过程中,需要指定次数

举例
co*ke –> 不限个数的 O
co+ke –>至少一个 O
co?ke ->1 个或零个 O
co{0}ke ->0 个 O
co{5,}ke –>5 次及以上
co{5,8}ke –> 至少 5 次,最多 8 次
[1-9]\d{3} –>大于等于 1000 小于等于 9999 的数
[1-9]\d{2,4} –>大于等于 100 小于等于 99999 的数
1[34578]\d{9} -> 匹配手机号
<[a-zA-Z]+/d?> ->网页标签
<[a-zA-Z][a-zA-Z0-9]*> ->网页标签
贪婪模式
在匹配次数不定时如 *, {n,}, + 匹配字符越多越好,默认模式即贪婪模式
- *贪婪模式 greedy(匹配字符越多越好,可回溯) ?
- ?懒惰模式 lazy reluctant (匹配字符越少越好,可回溯)
- + 独占模式 possessive(匹配字符越多越好,不可回溯) 用的较少
举例
.*o –>贪婪模式
.{2,}o–>贪婪模式
.{2,}?o –>懒惰模式
.{2,}+o –>独占模式,不可回溯 没有匹配到内容。
<.+?> ->找出标签 不要标签内的内容。不是<.+>
<[^>]+> ->找出标签 不要标签内的内容。不是 <.+>
阻止贪婪有两种方式
1、 量词后面使用 ?
2、 使用取反
边界
边界不占用宽度,只是一个界限 ^ :开始 \b :单词边界 \B :非单词边界 $ :结束
^ :多行模式代表每行头 单行模式代表整个字符串的开始
$ : 多行模式代表每行尾 单行模式代表字符串的结尾
\b : 匹配前面或后面的不是\w
\B : 匹配前面或后面的是\w
选择符与分组
| ->优先级低 ,满足匹配则停止,不会查找更优的方案。
分组 ()
匹配 ab c -> ab|c
匹配 ab ac -> a(b|c)
只匹配 get -> \bget\b
匹配 get 和 getValue -> getvalue|get get(value)?
获取 and or -> \band\b|\bor\b \b(and|or)\b
反向引用:
\ 内部默认缓存,从第一个左括号计算,编号为 1 开始。 必须认识组编号,为 ( 的位置
(")test\1 –> “第 1 个左括号中
((")test)\2 –> “第 2 个左括号中
((("))test2)\3 –> “第 3 个左括号中
["'](.*?)["'] -> 错误的 找出合法的字符串"" 或''
(["'])([^"']+)\1 ->找出合法的字符串"" 或''
非捕获组: (?:xxx) :
不缓存组
(["'])(?:[^"']+)\1 ->不缓存第二组,不能引用第二组
(?:["'])(?:[^"']+)\1 –>所有的组都没有缓存,不能再引用了。
模式修改符
(?ism )*****(?-ism)
i : insensitive 使正则表达式对大小写不敏感;
(重点) s : singleline 开启“单行模式”,即点号“.”匹配新行符;
m : multiline 开启“多行模式”,即“^”和“$”匹配新行符的前面和后面的位置
(?i)select(?-i) -> 不区分大小写。
零宽断言
前瞻(Lookahead) 后顾(Lookbehind)
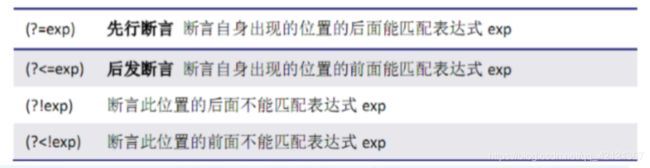
(\w+)(?<=ing) -->匹配 singing testing 整个单词 -> 后顾
(\w+)(?=ing) -->匹配 sing test ->前瞻
常用类
java.util.regex Pattern Matcher String 一般在查找、替换、分割、组的使用
Pattern
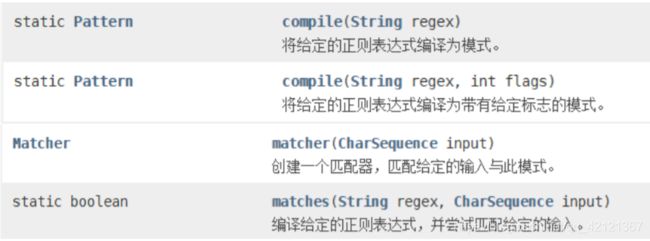
Matcher

Java通过验证字符串是否匹配你制定的规则,经常用到正则表达式,直接上代码:
//Q密码
String str = "Qqwewq123456.";
//字符+符号
String reg = "(\\w)+(\\W)";
//声明比较规则
Pattern pattern=Pattern.compile(reg);
//声明比较器,放入字符串
Matcher matcher=pattern.matcher(str);
//是否匹配
System.out.println(matcher.matches());
System.out.println(matcher.find());
System.out.println(matcher.groupCount());
System.out.println(matcher.toString());字符串与正则

字符串中拥有 matches() 方法,效果和上面差不多,上代码:
String str ="and";
//完全匹配
boolean flag =str.matches("\\b(and|or)\\b");
System.out.println(flag);
str="\"happy\" and \"regex\" \"baidu\" or \"google\"";
//替换所有
str =str.replaceAll("\\b(and|or)\\b", "-->");
System.out.println(str);
//分割
str="\"happy\" and \"regex\" \"baidu\" or \"google\"";
//切割
String[] arr=str.split("\\b(and|or)\\b");
for(String temp:arr){
System.out.println(temp);
}
arr=str.split("m");
//没有对应的,返回本身
for(String temp:arr){
System.out.println(temp);
}
//. -->任意字符
str ="192.168.1.234";
arr=str.split("\\.");
//注意转义
for(String temp:arr){
System.out.println(temp);
}总结:正则表达式虽然不是Java的一部分,但在每个语言中都起到了非常重要的作用,使用好正则表达式,可以达到奇效!
业精于勤,荒于嬉;行成于思,毁于随。