win11使用anaconda安装pytorch-gpu版本 并训练LeNet网络 Cifar10数据集
电脑为华硕天选三,Rtx3070显卡,win11系统
1.创建anaconda虚拟环境
使用“conda create -n your_env_name python=X.X”命令创建python版本为X.X、名字为your_env_name的虚拟环境
conda create -n pytorch_gpu_1
2.进入虚拟环境,并配置国内镜像源
激活虚拟环境:
activate pytorch_gpu_1
附:conda安装以及 CUDA Toolkit安装可以参考:
https://blog.csdn.net/weixin_43798572/article/details/123122477
conda以及 CUDA Toolkit安装好以后,进行下一步
3.安装指定版本的pytorch gpu指定版本,安装安装命令如下:

pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
此处安装使用pip安装,速度较快 实测2个多g的文件 三分钟以内装好!
4.验证是否安装成功
在你的anaconda prompt中激活你的虚拟环境,输入python,并输入以下命令:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
输出True,并无报错则安装成功!
使用pycharm配置anaconda环境(较为简单,不会的可以自行百度),使用cifar10数据集并训练LeNet网络
5.运行官方demo:
5.1创建model.py文件,并创建lenet模型
#create LeNet
import torch.nn as nn
import torch.nn.functional as F
#[batch,channel,height,width
#经卷积后的矩阵尺寸大小计算公式:N=(W-F+2P)/S + 1 w:输入图片大小 F:卷积核大小 S:步长 P:padding的像素数p
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) #输入图片通道数 卷积核个数 卷积核大小
self.pool1 = nn.MaxPool2d(2,2) #池化核大小 步距
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(32*5*5, 120) #全连接层 输入参数个数 输出参数个数
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self,x):
x = F.relu(self.conv1(x)) #input(3,32,32) output(16,28,28)
x = self.pool1(x) # output(16,14,14) 池化层只影响宽和高 不影响深度
x = F.relu(self.conv2(x)) # output(32,10,10)
x = self.pool2(x) # output(32,5,5)
x = x.view(-1,32*5*5) #view函数类似于numpy中的resize函数, -1表示将矩阵转为向量
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
5.2:创建train.py文件,编写以下代码,使用gpu训练模型
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
import numpy as np
import time
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入50000张训练图片
trainset = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录
train=True, # 表示是数据集中的训练集
download=True, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
#加载训练集,实际过程需要分批次(batch)训练
trainloader = torch.utils.data.DataLoader(trainset, # 导入的训练集
batch_size=32, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
#10000张测试图片
testset = torchvision.datasets.CIFAR10(root='./data',train=False,download=False,transform=transform)
testloader = torch.utils.data.DataLoader(testset,batch_size=10000,shuffle=False,num_workers=0)
# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(testloader)
test_image, test_label = test_data_iter.next()
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
#图片展示
# test_loader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=0)
# test_data_iter = iter(test_loader)
# test_image, test_label = test_data_iter.next()
# def imshow(img):
# img = img / 2 + 0.5
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1,2,0)))
# plt.show()
# print(' '.join('%5s' % classes[test_label[j]] for j in range(4)))
# imshow(torchvision.utils.make_grid(test_image))
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # add
print(device) # add
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#print(device)
net = LeNet() # 定义训练的网络模型
net.to(device)
loss_function = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器(训练参数,学习率)#device = torch.device("cuda") #使用gpu训练
for epoch in range(5): # 一个epoch即对整个训练集进行一次训练
running_loss = 0.0
time_start = time.perf_counter()
for step, data in enumerate(trainloader, start=0): # 遍历训练集,step从0开始计算
inputs, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
# forward + backward + optimize
outputs = net(inputs.to(device)) # 正向传播
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
# 打印耗时、损失、准确率等数据
running_loss += loss.item()
if step % 1000 == 999: # print every 1000 mini-batches,每1000步打印一次
with torch.no_grad(): # 在以下步骤中(验证过程中)不用计算每个节点的损失梯度,防止内存占用
outputs = net(test_image.to(device)) # 测试集传入网络(test_batch_size=10000),output维度为[10000,10]
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
accuracy = (predict_y == test_label.to(device)).sum().item() / test_label.to(device).size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % # 打印epoch,step,loss,accuracy
(epoch + 1, step + 1, running_loss / 500, accuracy))
print('%f s' % (time.perf_counter() - time_start)) # 打印耗时
running_loss = 0.0
print('Finished Training')
# 保存训练得到的参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
对比分析:
gpu训练过程 性能监控以及耗时:
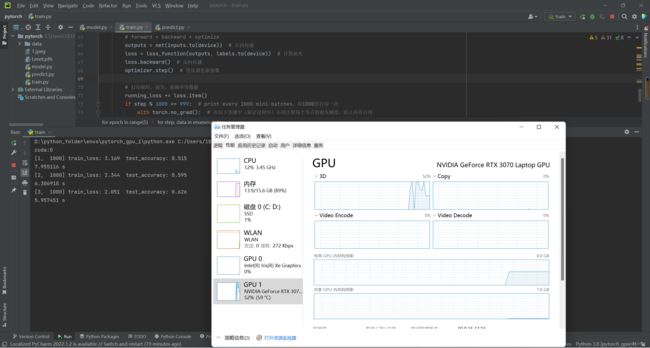
cpu训练代码:
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
import numpy as np
import time
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入50000张训练图片
trainset = torchvision.datasets.CIFAR10(root='./data', # 数据集存放目录
train=True, # 表示是数据集中的训练集
download=False, # 第一次运行时为True,下载数据集,下载完成后改为False
transform=transform) # 预处理过程
# 加载训练集,实际过程需要分批次(batch)训练
trainloader = torch.utils.data.DataLoader(trainset, # 导入的训练集
batch_size=32, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
# 10000张测试图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=10000, shuffle=False, num_workers=0)
# 获取测试集中的图像和标签,用于accuracy计算
test_data_iter = iter(testloader)
test_image, test_label = test_data_iter.next()
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 图片展示
# test_loader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=0)
# test_data_iter = iter(test_loader)
# test_image, test_label = test_data_iter.next()
# def imshow(img):
# img = img / 2 + 0.5
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1,2,0)))
# plt.show()
# print(' '.join('%5s' % classes[test_label[j]] for j in range(4)))
# imshow(torchvision.utils.make_grid(test_image))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # add
#print(device) # add
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# print(device)
net = LeNet() # 定义训练的网络模型
#net.to(device)
loss_function = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器(训练参数,学习率)#device = torch.device("cuda") #使用gpu训练
for epoch in range(5): # 一个epoch即对整个训练集进行一次训练
running_loss = 0.0
time_start = time.perf_counter()
for step, data in enumerate(trainloader, start=0): # 遍历训练集,step从0开始计算
inputs, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
# forward + backward + optimize
outputs = net(inputs) # 正向传播
loss = loss_function(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
# 打印耗时、损失、准确率等数据
running_loss += loss.item()
if step % 1000 == 999: # print every 1000 mini-batches,每1000步打印一次
with torch.no_grad(): # 在以下步骤中(验证过程中)不用计算每个节点的损失梯度,防止内存占用
outputs = net(test_image) # 测试集传入网络(test_batch_size=10000),output维度为[10000,10]
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
accuracy = (predict_y == test_label).sum().item() / test_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % # 打印epoch,step,loss,accuracy
(epoch + 1, step + 1, running_loss / 500, accuracy))
print('%f s' % (time.perf_counter() - time_start)) # 打印耗时
running_loss = 0.0
print('Finished Training')
# 保存训练得到的参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
cpu训练过程 性能监控以及耗时:

5.3 创建predict.py文件,导入训练好的模型参数,并使用模型进行预测:
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
transform = transforms.Compose(
[transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('1.jpeg')
im = transform(im)
im = torch.unsqueeze(im,dim=0)
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs,dim=1)[1].data.numpy()
print(classes[int(predict)])
希望自己可以坚持创作!!!