【深度学习】基于STL10数据集构建 图像去噪自编码网络 的实验
文章目录
- 前言
- 一、STL10数据集观察
- 二、噪声数据添加(噪声数据集生成)
-
- 1.自定义噪声生成函数
- 2.噪声图像展示
- 三、数据切分,转换,加载
- 四、自编码器网络搭建
- 五、训练
- 六、预测
- 七、小重点:如果要调用GPU,必须在哪些位置加to(device)(.cuda()也行)
- 八、小重点:tqdm进度条使用
- 九、代码bug调试总结
-
- 1.OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized问题
- 2.页面文件太小
- 3.RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the
- 4.RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
- 5.RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
- 6.can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
前言
本文主要参考孙玉林,余国本老师的《pytorch深度学习入门与实践》一书,跟着书上的代码学习相关原理理论,这本书真的写的非常好,让我明白了很多最基础的原理。本篇文章也是基于此书的笔记,加上了一些我自己的理解。
同时,书上的代码运行主要也是在CPU上运行的,所以我在这里换成了GPU运行,这样速度更快一些。
同时,我对书中的代码进行一些修改和探讨。
一、STL10数据集观察
首先书中提到要使用STL10数据集,通过以下命令进行下载:
import torch
from torchvision.datasets import STL10
data=STL10('data',download=True)
下载完成后data文件夹中数据如下:

压缩包数据为2.45GB,解压后为2.9GB。指的一提的是,这里所有bin都是二进制文件。二进制文件具体该如何操作我也不太清楚,(并且很多数据集文件类型都不太一样,有些是btype,有些又是二进制文件,到底它们分别应该如何操作后面找个时间好好把这些内容搞清楚咯)。
但是肯定的是,这里的bin文件必须要转为图像数据,在本书中也是定义了一个读取函数,用来进行数据转换。
下载的数据一共包括三部分,带标签的训练集,测试集,以及无标签的数据,大小都是96*96。按照本书的安排,我们只会使用到train_X.bin里的内容。
书里,定义的二进制文件转为图像文件的函数如下:
def read_image(path):
with open(path,'rb') as f:
data1=np.fromfile(f,dtype=np.uint8)
images=np.reshape(data1,(-1,3,96,96))
images=np.transpose(images,(0,3,2,1))
return images/255.0
说实话我对python的文件操作还真不是特别懂,所以在看这段代码时显得有些力不从心。(甚至有些烦躁)
(1)首先rb是对二进制文件进行读操作
(2)其次是np.reshape操作(这个操作其实和torch.view()貌似有点点相像)
(3)然后是np.transpose操作,更改维度通道
最关键的是,为什么对bin文件,它要先用np.fromfile这个操作呢?:
我们点开np.fromfile这个函数:
后面查找了资料知道,np.fromfile函数是从文本或者二进制文件中读取并构造一个数组。我们来看看它构造的数组长啥子样子的:
import numpy as np
data_path='E:/图像处理课题/自编码器去噪网络/data/stl10_binary/train_X.bin'
with open(data_path,'rb') as f:
data1 = np.fromfile(f, dtype=np.uint8)
print(type(data1))
print(data1.shape)

138240000,有点奇怪,像是一个一维数组。
紧接着我们看看接下来的操作,reshape重组数组的形状为(-1, 3, 96, 96)。
这个就很好理解了,相当于是把这个数据砍成n个3* 96 * 96的数据,这个3 * 96 *96就是一个三通道的照片,n=5000.(5000×3×96×96=138240000):

后面这个维度变换说实话我也没看懂,本来b,c,h,w这个顺寻就是对的,为什么这里要把通道维度和高维度交换呢?这里我就先不管了,最后除了255,将像素值归一化到0-1之间(uint8的像素值范围值是0-255)
在完成二进制文件数据的转换之后,我们来看看数据包里面的图片都长啥子样子:
import torch
import numpy as np
from torchvision.datasets import STL10
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
data=STL10('data',download=False)
def read_image(path):
with open(path,'rb') as f:
data1=np.fromfile(f,dtype=np.uint8)
images=np.reshape(data1,(-1,3,96,96))
images=np.transpose(images,(0,3,2,1))
return images/255.0
data_path='E:/图像处理课题/自编码器去噪网络/data/stl10_binary/train_X.bin'
images=read_image(data_path) #最后输出的5000张图片
print(type(images)) #格式为结果图片:
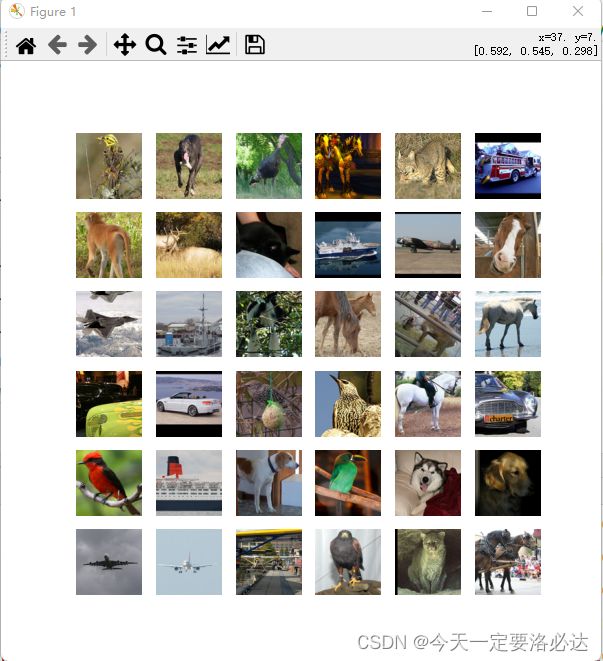
当然我们之前也提到了,我们用的照片只有5000张,并且这里plt.subplot也仅仅展示了36张,我们也可以调整参数,展示更多,且范围不一样的图片,例如下所示:
plt.figure(figsize=(9,9))
for i in range(81):
plt.subplot(9,9,i+1)
plt.imshow(images[i+1000])
plt.axis('off')
plt.show()
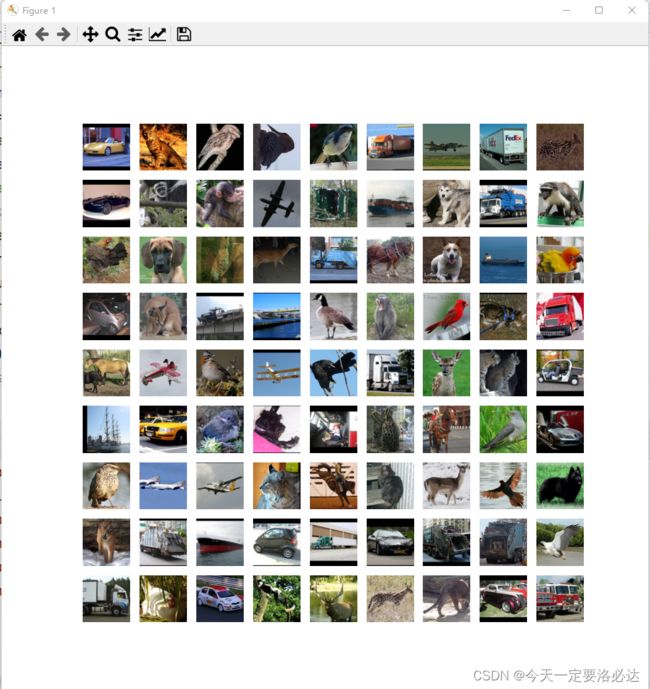
这里展示了第1001到1081共81张照片。
二、噪声数据添加(噪声数据集生成)
目前来说,初始的(无污染的)数据集我们已经拿到,这时候我们还缺输入数据集(噪声数据集)。噪声数据集和无污染数据集(去噪数据集)合在一起,才能构成最终的数据集。
1.自定义噪声生成函数
在书中,给出了具体的噪声生成函数
def gaussian_noise(images,sigma):
sigma2=sigma**2/(255**2)
images_noise=np.zeros_like(images)
for i in range(images.shape[0]):#images.shape[0]指原始数据集的数量,一共是5000张
image=images[i]
noise_im=random_noise(image,mode="gaussian",var=sigma2,clip=True)
images_noise[i]=noise_im
return images_noise
其实核心语句就那么一条:noise_im=random_noise(image,mode=“gaussian”,var=sigma2,clip=True)。使用的random_noise来生成噪声,当然出了高斯噪声,还有其他种类的噪声。
关于这条语句的具体使用方法,我也专门写了一篇博客介绍:random_noise
2.噪声图像展示

三、数据切分,转换,加载
整体流程走下来就是:
step1.设置好X和Y(主要是交换维度,使得能够适应pytorch)
step2.X和Y切分为训练集和测试集
step3.ndarray数据形式转为张量形式
step4.X和Y合体(注意本题的Y是我们自己构造的,所以这里有一个合体的步骤,像mnist这种就不用)
step5.经典数据加载器,无需多言
## 数据准备为Pytorch可用的形式
## 转化为[样本,通道,高,宽]的数据形式
data_Y = np.transpose(images, (0, 3, 2, 1))
data_X = np.transpose(images_noise, (0, 3, 2, 1))
## 将数据集切分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(data_X,data_Y,test_size = 0.2,random_state = 123)
## 将图像数据转化为向量数据
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)
X_val = torch.tensor(X_val, dtype=torch.float32)
y_val = torch.tensor(y_val, dtype=torch.float32)
## 将X和Y转化为数据集合
train_data = Data.TensorDataset(X_train,y_train)
val_data = Data.TensorDataset(X_val,y_val)
train_loader = Data.DataLoader(
dataset = train_data, ## 使用的数据集
batch_size=8, # 批处理样本大小
shuffle = True, # 每次迭代前打乱数据
num_workers = 0, # 使用4个进程
)
## 定义一个数据加载器
val_loader = Data.DataLoader(
dataset = val_data, ## 使用的数据集
batch_size=8, # 批处理样本大小
shuffle = True, # 每次迭代前打乱数据
num_workers = 0, # 使用4个进程
)
四、自编码器网络搭建
书上用到的网络叫做基于卷积的降噪自编码器网络,关于自编码器网络,后续我也会自己出一个总结。
博客地址先放出来:
网络结构代码如下所示,就不具体赘述了,直接看代码就行(书上直接誊抄的):
96 * 96 变为 24 * 24,,最后再恢复为96 * 96
class DenoiseAutoEncoder(nn.Module):
def __init__(self):
super(DenoiseAutoEncoder, self).__init__()
## 定义Encoder
self.Encoder = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64,
kernel_size=3, stride=1, padding=1), # [,64,96,96]
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, 1, 1), # [,64,96,96]
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, 1, 1), # [,64,96,96]
nn.ReLU(),
nn.MaxPool2d(2, 2), # [,64,48,48]
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, 3, 1, 1), # [,128,48,48]
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 128, 3, 1, 1), # [,128,48,48]
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 256, 3, 1, 1), # [,256,48,48]
nn.ReLU(),
nn.MaxPool2d(2, 2), # [,256,24,24]
nn.BatchNorm2d(256),
)
## 定义Decoder
self.Decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, 3, 1, 1), # [,128,24,24]
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 128, 3, 2, 1, 1), # [,128,48,48]
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 3, 1, 1), # [,64,48,48]
nn.ReLU(),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 32, 3, 1, 1), # [,32,48,48]
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32, 32, 3, 1, 1), # [,32,48,48]
nn.ConvTranspose2d(32, 16, 3, 2, 1, 1), # [,16,96,96]
nn.ReLU(),
nn.BatchNorm2d(16),
nn.ConvTranspose2d(16, 3, 3, 1, 1), # [,3,96,96]
nn.Sigmoid(),
)
## 定义网络的向前传播路径
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return encoder, decoder
当然,我对 nn.BatchNorm2d(64),这个概念还不是很理解,后续也要出个博客总结一下。
五、训练
训练过程依然是比较经典的过程,两个for循环,对于epoch和batch:
相比于书上的代码 ,我还加上tqdm进度条
# 定义优化器
LR = 0.0003
optimizer = torch.optim.Adam(DAEmodel.parameters(), lr=LR)
loss_func = nn.MSELoss() # 损失函数
# 记录训练过程的指标
history1 = hl.History()
# 使用Canvas进行可视化
canvas1 = hl.Canvas()
train_num = 0
val_num = 0
## 对模型进行迭代训练,对所有的数据训练EPOCH轮
for epoch in range(10):
train_loss_epoch = 0
val_loss_epoch = 0
## 对训练数据的迭代器进行迭代计算
loop1 = tqdm(enumerate(train_loader), total=len(train_loader) - 1)
for step, (b_x, b_y) in loop1:
b_x=b_x.to(device) #数据传到显卡上
b_y = b_y.to(device)
DAEmodel.train()
## 使用每个batch进行训练模型
_, output = DAEmodel(b_x) # CNN在训练batch上的输出
loss = loss_func(output, b_y) # 平方根误差
optimizer.zero_grad() # 每个迭代步的梯度初始化为0
loss.backward() # 损失的后向传播,计算梯度
optimizer.step() # 使用梯度进行优化
train_loss_epoch += loss.item() * b_x.size(0)
train_num = train_num + b_x.size(0)
train_loss = train_loss_epoch / train_num
loop1.set_description(f'Epoch [{epoch}/{10 - 1}]')
loop1.set_postfix(train_loss = train_loss_epoch / train_num)
loop2 = tqdm(enumerate(val_loader), total=len(val_loader) - 1)
## 使用每个batch进行验证模型
for step, (b_x, b_y) in loop2:
b_x = b_x.to(device) # 数据传到显卡上
b_y = b_y.to(device)
DAEmodel.eval()
_, output = DAEmodel(b_x) # CNN在训练batch上的输出
loss = loss_func(output, b_y) # 平方根误差
val_loss_epoch += loss.item() * b_x.size(0)
val_num = val_num + b_x.size(0)
## 计算一个epoch的损失
val_loss = val_loss_epoch / val_num
loop2.set_description(f'Epoch [{epoch}/{10 - 1}]')
loop2.set_postfix(val_loss = val_loss_epoch / val_num)
## 保存每个epoch上的输出loss
history1.log(epoch, train_loss=train_loss,
val_loss=val_loss)
# 可视网络训练的过程
with canvas1:
canvas1.draw_plot([history1["train_loss"], history1["val_loss"]])
torch.save(DAEmodel,"E:/图像处理课题/自编码器去噪网络/DAEmodel_1.pkl")
训练进度条如下所示:

六、预测
本来是想单独写一个py文件进行预测,同时和训练过程分离开,结果没想到一直有问题(执行那段代码的时候,它直接跳转去之前的训练文件了)
代码就先直接抄了,后面有空了再来慢慢改
imageindex = 10
im = X_val[imageindex,...]
im = im.unsqueeze(0)
imnose = np.transpose(im.data.cpu().numpy(),(0,3,2,1))
imnose = imnose[0,...]
## 去噪
DAEmodel.eval()
im=im.to(device)
_,output = DAEmodel(im)
imde = np.transpose(output.data.cpu().numpy(),(0,3,2,1))
imde = imde[0,...]
## 输出
im = y_val[imageindex,...]
imor = im.unsqueeze(0)
imor = np.transpose(imor.data.cpu().numpy(),(0,3,2,1))
imor = imor[0,...]
## 计算去噪后的PSNR
print("加噪后的PSNR:",compare_psnr(imor,imnose),"dB")
print("去噪后的PSNR:",compare_psnr(imor,imde),"dB")
## 将图像可视化
plt.figure(figsize=(12,4))
plt.subplot(1,3,1)
plt.imshow(imor)
plt.axis("off")
plt.title("Origin image")
plt.subplot(1,3,2)
plt.imshow(imnose)
plt.axis("off")
plt.title("Noise image $\sigma$=30")
plt.subplot(1,3,3)
plt.imshow(imde)
plt.axis("off")
plt.title("Deoise image")
plt.show()
结果:

七、小重点:如果要调用GPU,必须在哪些位置加to(device)(.cuda()也行)
仅仅以本题为例
1.首先声明设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #调用cpu或者cuda
2.网络实例化时
DAEmodel = DenoiseAutoEncoder().to(device)
3.对每一个batch进行训练时候的X,y数据(有噪图,无噪图),也需要导入到显卡中
。。。。。。。。。
loop1 = tqdm(enumerate(train_loader), total=len(train_loader) - 1)
for step, (b_x, b_y) in loop1:
b_x=b_x.to(device) #数据传到显卡上
b_y = b_y.to(device)
DAEmodel.train()
。。。。。。。。。。。
。。。。。。。。。
loop2 = tqdm(enumerate(val_loader), total=len(val_loader) - 1)
## 使用每个batch进行验证模型
for step, (b_x, b_y) in loop2:
b_x = b_x.to(device) # 数据传到显卡上
b_y = b_y.to(device)
DAEmodel.eval()
。。。。。。。。。。。
八、小重点:tqdm进度条使用
tdqm主要是在对每一个batch进行训练时使用的
原本应该张这个样子
for step, (b_x,b_y) in enumerate(train_loader):
改进后长这样:
loop1 = tqdm(enumerate(train_loader), total=len(train_loader) - 1)
for step, (b_x, b_y) in loop1:
。。。。。。。。。。。。。。。。
loop1.set_description(f'Epoch [{epoch}/{10 - 1}]')
loop1.set_postfix(train_loss = train_loss_epoch / train_num)
同理,对验证集也是这样
loop2 = tqdm(enumerate(val_loader), total=len(val_loader) - 1)
## 使用每个batch进行验证模型
for step, (b_x, b_y) in loop2:
。。。。。
loop2.set_description(f'Epoch [{epoch}/{10 - 1}]')
loop2.set_postfix(val_loss = val_loss_epoch / val_num)
九、代码bug调试总结
1.OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized问题
这个问题遇到很多次了,一般我直接加两条语句就解决了:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
2.页面文件太小
报错时代码如下:
train_loader = Data.DataLoader(
dataset = train_data, ## 使用的数据集
batch_size=8, # 批处理样本大小
shuffle = True, # 每次迭代前打乱数据
num_workers = 4, # 使用4个进程
)
报错界面如下所示:
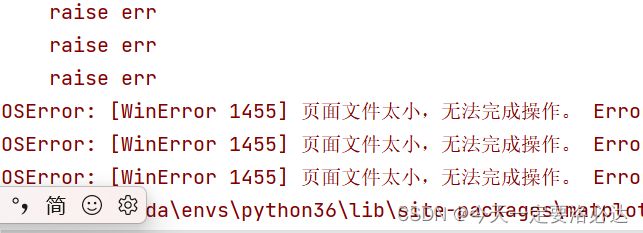
这个问题还是比较经典的,就是内存不足的问题:
一般来说,我就把num_workers变成0就不会出现这样的问题
3.RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the
解决方法如4一样
4.RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
和3一样,这种报错,多半就是数据,网络等配置没有放在同一个地方(必须都在CPU上,或者都在GPU上)。
这个报错的原因多半就是哪里漏写了to(device)
5.RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
这种报错主要原因是因为batch_size设置过大了(但是我报错那次设的是16,这都大???),改小点就可以了
6.can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
这个问题的产生原因是:之前网络训练时候,数据转换为了Tensor张量,并且全部放到了GPU上进行训练,所以这会要在CPU上使用numpy形式进行预测的时候,需要把设备转移到CPU上来。解决方法也很简单,以下为例:
原本报错的代码:
imde = np.transpose(output.data.numpy(),(0,3,2,1))
修改后不报错的代码:
imde = np.transpose(output.data.cpu().numpy(),(0,3,2,1))