PyTorch 实现MobileNet_v2在CIFAR10上图像分类
目录
一、前言
二、网络结构
三、参数量
四、代码
(一)model
(二)train
(三)Test
五、训练结果
六、完整代码
一、前言
MobileNet_v2是在MobileNet_v1基础上改进的。一方面解决了MobileNet_v1中不包含残差结构,另一方面解决了MobileNet_v1中大多数的dw卷积会不起作用。
MobileNet_v2提出了一种倒残差结构(Inverted Residuals)。传统的残差结构是先降维后升维,并且均采用了非线性激活函数。倒残差结构与之相反,先通过1*1卷积升维,在高维空间利用dw卷积后再降维,同时降维卷积后采用的是线性激活函数(原论文中详细论述了对低维度信息使用relu激活函数会造成信息丢失)。
二、网络结构

expand_rate是升维的参数因子(即channel扩大到原来的几倍) ,当该因子为1时候,即没有升维,此时bottleneck结构中是没有第一部分1*1卷积操作的;此外,只有当输入尺寸与输出尺寸完全相同时候才有残差结构(通常第二次重复之后的bottleneck结构中会有该部分)
三、参数量
当宽度缩放因子 为1时候,参数量大约有220万左右:
为1时候,参数量大约有220万左右:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
ReLU6-3 [-1, 32, 112, 112] 0
baseConv-4 [-1, 32, 112, 112] 0
Identity-5 [-1, 32, 112, 112] 0
Conv2d-6 [-1, 32, 112, 112] 288
BatchNorm2d-7 [-1, 32, 112, 112] 64
ReLU6-8 [-1, 32, 112, 112] 0
baseConv-9 [-1, 32, 112, 112] 0
Conv2d-10 [-1, 16, 112, 112] 512
BatchNorm2d-11 [-1, 16, 112, 112] 32
Identity-12 [-1, 16, 112, 112] 0
baseConv-13 [-1, 16, 112, 112] 0
residual-14 [-1, 16, 112, 112] 0
Conv2d-15 [-1, 96, 56, 56] 1,536
BatchNorm2d-16 [-1, 96, 56, 56] 192
ReLU6-17 [-1, 96, 56, 56] 0
baseConv-18 [-1, 96, 56, 56] 0
Conv2d-19 [-1, 96, 28, 28] 864
BatchNorm2d-20 [-1, 96, 28, 28] 192
ReLU6-21 [-1, 96, 28, 28] 0
baseConv-22 [-1, 96, 28, 28] 0
Conv2d-23 [-1, 24, 28, 28] 2,304
BatchNorm2d-24 [-1, 24, 28, 28] 48
Identity-25 [-1, 24, 28, 28] 0
baseConv-26 [-1, 24, 28, 28] 0
residual-27 [-1, 24, 28, 28] 0
Conv2d-28 [-1, 144, 28, 28] 3,456
BatchNorm2d-29 [-1, 144, 28, 28] 288
ReLU6-30 [-1, 144, 28, 28] 0
baseConv-31 [-1, 144, 28, 28] 0
Conv2d-32 [-1, 144, 28, 28] 1,296
BatchNorm2d-33 [-1, 144, 28, 28] 288
ReLU6-34 [-1, 144, 28, 28] 0
baseConv-35 [-1, 144, 28, 28] 0
Conv2d-36 [-1, 24, 28, 28] 3,456
BatchNorm2d-37 [-1, 24, 28, 28] 48
Identity-38 [-1, 24, 28, 28] 0
baseConv-39 [-1, 24, 28, 28] 0
residual-40 [-1, 24, 28, 28] 0
Conv2d-41 [-1, 144, 14, 14] 3,456
BatchNorm2d-42 [-1, 144, 14, 14] 288
ReLU6-43 [-1, 144, 14, 14] 0
baseConv-44 [-1, 144, 14, 14] 0
Conv2d-45 [-1, 144, 7, 7] 1,296
BatchNorm2d-46 [-1, 144, 7, 7] 288
ReLU6-47 [-1, 144, 7, 7] 0
baseConv-48 [-1, 144, 7, 7] 0
Conv2d-49 [-1, 32, 7, 7] 4,608
BatchNorm2d-50 [-1, 32, 7, 7] 64
Identity-51 [-1, 32, 7, 7] 0
baseConv-52 [-1, 32, 7, 7] 0
residual-53 [-1, 32, 7, 7] 0
Conv2d-54 [-1, 192, 7, 7] 6,144
BatchNorm2d-55 [-1, 192, 7, 7] 384
ReLU6-56 [-1, 192, 7, 7] 0
baseConv-57 [-1, 192, 7, 7] 0
Conv2d-58 [-1, 192, 7, 7] 1,728
BatchNorm2d-59 [-1, 192, 7, 7] 384
ReLU6-60 [-1, 192, 7, 7] 0
baseConv-61 [-1, 192, 7, 7] 0
Conv2d-62 [-1, 32, 7, 7] 6,144
BatchNorm2d-63 [-1, 32, 7, 7] 64
Identity-64 [-1, 32, 7, 7] 0
baseConv-65 [-1, 32, 7, 7] 0
residual-66 [-1, 32, 7, 7] 0
Conv2d-67 [-1, 192, 7, 7] 6,144
BatchNorm2d-68 [-1, 192, 7, 7] 384
ReLU6-69 [-1, 192, 7, 7] 0
baseConv-70 [-1, 192, 7, 7] 0
Conv2d-71 [-1, 192, 7, 7] 1,728
BatchNorm2d-72 [-1, 192, 7, 7] 384
ReLU6-73 [-1, 192, 7, 7] 0
baseConv-74 [-1, 192, 7, 7] 0
Conv2d-75 [-1, 32, 7, 7] 6,144
BatchNorm2d-76 [-1, 32, 7, 7] 64
Identity-77 [-1, 32, 7, 7] 0
baseConv-78 [-1, 32, 7, 7] 0
residual-79 [-1, 32, 7, 7] 0
Conv2d-80 [-1, 192, 4, 4] 6,144
BatchNorm2d-81 [-1, 192, 4, 4] 384
ReLU6-82 [-1, 192, 4, 4] 0
baseConv-83 [-1, 192, 4, 4] 0
Conv2d-84 [-1, 192, 2, 2] 1,728
BatchNorm2d-85 [-1, 192, 2, 2] 384
ReLU6-86 [-1, 192, 2, 2] 0
baseConv-87 [-1, 192, 2, 2] 0
Conv2d-88 [-1, 64, 2, 2] 12,288
BatchNorm2d-89 [-1, 64, 2, 2] 128
Identity-90 [-1, 64, 2, 2] 0
baseConv-91 [-1, 64, 2, 2] 0
residual-92 [-1, 64, 2, 2] 0
Conv2d-93 [-1, 384, 2, 2] 24,576
BatchNorm2d-94 [-1, 384, 2, 2] 768
ReLU6-95 [-1, 384, 2, 2] 0
baseConv-96 [-1, 384, 2, 2] 0
Conv2d-97 [-1, 384, 2, 2] 3,456
BatchNorm2d-98 [-1, 384, 2, 2] 768
ReLU6-99 [-1, 384, 2, 2] 0
baseConv-100 [-1, 384, 2, 2] 0
Conv2d-101 [-1, 64, 2, 2] 24,576
BatchNorm2d-102 [-1, 64, 2, 2] 128
Identity-103 [-1, 64, 2, 2] 0
baseConv-104 [-1, 64, 2, 2] 0
residual-105 [-1, 64, 2, 2] 0
Conv2d-106 [-1, 384, 2, 2] 24,576
BatchNorm2d-107 [-1, 384, 2, 2] 768
ReLU6-108 [-1, 384, 2, 2] 0
baseConv-109 [-1, 384, 2, 2] 0
Conv2d-110 [-1, 384, 2, 2] 3,456
BatchNorm2d-111 [-1, 384, 2, 2] 768
ReLU6-112 [-1, 384, 2, 2] 0
baseConv-113 [-1, 384, 2, 2] 0
Conv2d-114 [-1, 64, 2, 2] 24,576
BatchNorm2d-115 [-1, 64, 2, 2] 128
Identity-116 [-1, 64, 2, 2] 0
baseConv-117 [-1, 64, 2, 2] 0
residual-118 [-1, 64, 2, 2] 0
Conv2d-119 [-1, 384, 2, 2] 24,576
BatchNorm2d-120 [-1, 384, 2, 2] 768
ReLU6-121 [-1, 384, 2, 2] 0
baseConv-122 [-1, 384, 2, 2] 0
Conv2d-123 [-1, 384, 2, 2] 3,456
BatchNorm2d-124 [-1, 384, 2, 2] 768
ReLU6-125 [-1, 384, 2, 2] 0
baseConv-126 [-1, 384, 2, 2] 0
Conv2d-127 [-1, 64, 2, 2] 24,576
BatchNorm2d-128 [-1, 64, 2, 2] 128
Identity-129 [-1, 64, 2, 2] 0
baseConv-130 [-1, 64, 2, 2] 0
residual-131 [-1, 64, 2, 2] 0
Conv2d-132 [-1, 384, 2, 2] 24,576
BatchNorm2d-133 [-1, 384, 2, 2] 768
ReLU6-134 [-1, 384, 2, 2] 0
baseConv-135 [-1, 384, 2, 2] 0
Conv2d-136 [-1, 384, 2, 2] 3,456
BatchNorm2d-137 [-1, 384, 2, 2] 768
ReLU6-138 [-1, 384, 2, 2] 0
baseConv-139 [-1, 384, 2, 2] 0
Conv2d-140 [-1, 96, 2, 2] 36,864
BatchNorm2d-141 [-1, 96, 2, 2] 192
Identity-142 [-1, 96, 2, 2] 0
baseConv-143 [-1, 96, 2, 2] 0
residual-144 [-1, 96, 2, 2] 0
Conv2d-145 [-1, 576, 2, 2] 55,296
BatchNorm2d-146 [-1, 576, 2, 2] 1,152
ReLU6-147 [-1, 576, 2, 2] 0
baseConv-148 [-1, 576, 2, 2] 0
Conv2d-149 [-1, 576, 2, 2] 5,184
BatchNorm2d-150 [-1, 576, 2, 2] 1,152
ReLU6-151 [-1, 576, 2, 2] 0
baseConv-152 [-1, 576, 2, 2] 0
Conv2d-153 [-1, 96, 2, 2] 55,296
BatchNorm2d-154 [-1, 96, 2, 2] 192
Identity-155 [-1, 96, 2, 2] 0
baseConv-156 [-1, 96, 2, 2] 0
residual-157 [-1, 96, 2, 2] 0
Conv2d-158 [-1, 576, 2, 2] 55,296
BatchNorm2d-159 [-1, 576, 2, 2] 1,152
ReLU6-160 [-1, 576, 2, 2] 0
baseConv-161 [-1, 576, 2, 2] 0
Conv2d-162 [-1, 576, 2, 2] 5,184
BatchNorm2d-163 [-1, 576, 2, 2] 1,152
ReLU6-164 [-1, 576, 2, 2] 0
baseConv-165 [-1, 576, 2, 2] 0
Conv2d-166 [-1, 96, 2, 2] 55,296
BatchNorm2d-167 [-1, 96, 2, 2] 192
Identity-168 [-1, 96, 2, 2] 0
baseConv-169 [-1, 96, 2, 2] 0
residual-170 [-1, 96, 2, 2] 0
Conv2d-171 [-1, 576, 1, 1] 55,296
BatchNorm2d-172 [-1, 576, 1, 1] 1,152
ReLU6-173 [-1, 576, 1, 1] 0
baseConv-174 [-1, 576, 1, 1] 0
Conv2d-175 [-1, 576, 1, 1] 5,184
BatchNorm2d-176 [-1, 576, 1, 1] 1,152
ReLU6-177 [-1, 576, 1, 1] 0
baseConv-178 [-1, 576, 1, 1] 0
Conv2d-179 [-1, 160, 1, 1] 92,160
BatchNorm2d-180 [-1, 160, 1, 1] 320
Identity-181 [-1, 160, 1, 1] 0
baseConv-182 [-1, 160, 1, 1] 0
residual-183 [-1, 160, 1, 1] 0
Conv2d-184 [-1, 960, 1, 1] 153,600
BatchNorm2d-185 [-1, 960, 1, 1] 1,920
ReLU6-186 [-1, 960, 1, 1] 0
baseConv-187 [-1, 960, 1, 1] 0
Conv2d-188 [-1, 960, 1, 1] 8,640
BatchNorm2d-189 [-1, 960, 1, 1] 1,920
ReLU6-190 [-1, 960, 1, 1] 0
baseConv-191 [-1, 960, 1, 1] 0
Conv2d-192 [-1, 160, 1, 1] 153,600
BatchNorm2d-193 [-1, 160, 1, 1] 320
Identity-194 [-1, 160, 1, 1] 0
baseConv-195 [-1, 160, 1, 1] 0
residual-196 [-1, 160, 1, 1] 0
Conv2d-197 [-1, 960, 1, 1] 153,600
BatchNorm2d-198 [-1, 960, 1, 1] 1,920
ReLU6-199 [-1, 960, 1, 1] 0
baseConv-200 [-1, 960, 1, 1] 0
Conv2d-201 [-1, 960, 1, 1] 8,640
BatchNorm2d-202 [-1, 960, 1, 1] 1,920
ReLU6-203 [-1, 960, 1, 1] 0
baseConv-204 [-1, 960, 1, 1] 0
Conv2d-205 [-1, 160, 1, 1] 153,600
BatchNorm2d-206 [-1, 160, 1, 1] 320
Identity-207 [-1, 160, 1, 1] 0
baseConv-208 [-1, 160, 1, 1] 0
residual-209 [-1, 160, 1, 1] 0
Conv2d-210 [-1, 960, 1, 1] 153,600
BatchNorm2d-211 [-1, 960, 1, 1] 1,920
ReLU6-212 [-1, 960, 1, 1] 0
baseConv-213 [-1, 960, 1, 1] 0
Conv2d-214 [-1, 960, 1, 1] 8,640
BatchNorm2d-215 [-1, 960, 1, 1] 1,920
ReLU6-216 [-1, 960, 1, 1] 0
baseConv-217 [-1, 960, 1, 1] 0
Conv2d-218 [-1, 320, 1, 1] 307,200
BatchNorm2d-219 [-1, 320, 1, 1] 640
Identity-220 [-1, 320, 1, 1] 0
baseConv-221 [-1, 320, 1, 1] 0
residual-222 [-1, 320, 1, 1] 0
Conv2d-223 [-1, 1280, 1, 1] 409,600
BatchNorm2d-224 [-1, 1280, 1, 1] 2,560
ReLU6-225 [-1, 1280, 1, 1] 0
baseConv-226 [-1, 1280, 1, 1] 0
AdaptiveAvgPool2d-227 [-1, 1280, 1, 1] 0
Dropout-228 [-1, 1280] 0
Linear-229 [-1, 10] 12,810
================================================================
Total params: 2,236,682
Trainable params: 2,236,682
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 58.59
Params size (MB): 8.53
Estimated Total Size (MB): 67.70
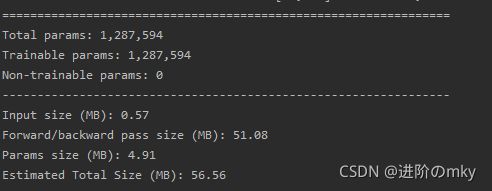
---------------------------------------------------------------- 当为0.75时候,参数量大约有120万左右:
四、代码
(一)model
import torch.nn as nn
from collections import OrderedDict
from torchsummary import summary
#把channel变为8的整数倍
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
#定义基本的ConvBN+Relu
class baseConv(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,groups=1,stride=1):
super(baseConv, self).__init__()
pad=kernel_size//2
relu=nn.ReLU6(inplace=True)
if kernel_size==1 and in_channels>out_channels:
relu=nn.Identity()
self.baseConv=nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,padding=pad,groups=groups,bias=False),
nn.BatchNorm2d(out_channels),
relu
)
def forward(self,x):
out=self.baseConv(x)
return out
#定义残差结构
class residual(nn.Module):
def __init__(self,in_channels,expand_rate,out_channels,stride): #输入和输出channel都要调整到8的整数倍
super(residual, self).__init__()
expand_channel=int(expand_rate*in_channels) #升维后的channel
conv1=baseConv(in_channels, expand_channel, 1, stride=stride)
if expand_rate==1:
#此时没有1*1卷积升维
conv1=nn.Identity()
#channel1
self.block1=nn.Sequential(
conv1,
baseConv(expand_channel,expand_channel,3,groups=expand_channel,stride=stride),
baseConv(expand_channel,out_channels,1)
)
if stride==1 and in_channels==out_channels:
self.has_res=True
else:
self.has_res=False
def forward(self,x):
if self.has_res:
return self.block1(x)+x
else:
return self.block1(x)
#定义mobilenetv2
class MobileNet_v2(nn.Module):
def __init__(self,theta=1,num_classes=10,init_weight=True):
super(MobileNet_v2, self).__init__()
#[inchannel,t,out_channel,stride]
net_config=[[32,1,16,1],
[16,6,24,2],
[24,6,32,2],
[32,6,64,2],
[64,6,96,1],
[96,6,160,2],
[160,6,320,1]]
repeat_num=[1,2,3,4,3,3,1]
module_dic=OrderedDict()
module_dic.update({'first_Conv':baseConv(3,_make_divisible(theta*32),3,stride=2)})
for idx,num in enumerate(repeat_num):
parse=net_config[idx]
for i in range(num):
module_dic.update({'bottleneck{}_{}'.format(idx,i+1):residual(_make_divisible(parse[0]*theta),parse[1],_make_divisible(parse[2]*theta),parse[3])})
parse[0]=parse[2]
parse[-1]=1
module_dic.update({'follow_Conv':baseConv(_make_divisible(theta*parse[-2]),_make_divisible(1280*theta),1)})
module_dic.update({'avg_pool':nn.AdaptiveAvgPool2d(1)})
self.module=nn.Sequential(module_dic)
self.linear=nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(_make_divisible(theta*1280),num_classes)
)
#初始化权重
if init_weight:
self.init_weight()
def init_weight(self):
for w in self.modules():
if isinstance(w, nn.Conv2d):
nn.init.kaiming_normal_(w.weight, mode='fan_out')
if w.bias is not None:
nn.init.zeros_(w.bias)
elif isinstance(w, nn.BatchNorm2d):
nn.init.ones_(w.weight)
nn.init.zeros_(w.bias)
elif isinstance(w, nn.Linear):
nn.init.normal_(w.weight, 0, 0.01)
nn.init.zeros_(w.bias)
def forward(self,x):
out=self.module(x)
out=out.view(out.size(0),-1)
out=self.linear(out)
return out
if __name__ == '__main__':
device='cuda'
net=MobileNet_v2(theta=0.75).to(device)
summary(net,(3,224,224))(二)train
from model import MobileNet_v2
import argparse
import torchvision
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import os
import torch.optim as optim
import torch.nn as nn
from utils import *
def train(opt):
device='cuda' if torch.cuda.is_available() else 'cpu'
print('using {} to train'.format(device))
#数据预处理
transform=transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])
#下载数据集
train_datasets=torchvision.datasets.CIFAR10('data',train=True,transform=transform,download=True)
val_datasets=torchvision.datasets.CIFAR10('data',train=False,transform=transform,download=True)
#加载数据集
train_dataloader=DataLoader(train_datasets,batch_size=opt.batch,shuffle=True,num_workers=opt.numworkers,pin_memory=True)
val_dataloader=DataLoader(val_datasets,batch_size=opt.batch,shuffle=False,num_workers=opt.numworkers,pin_memory=True)
if not os.path.exists(opt.savepath):
os.mkdir(opt.savepath)
#实例化网络
net=MobileNet_v2(theta=1,num_classes=opt.classNum).to(device)
#是否冻结权重
if opt.freeze:
for name,params in net.named_parameters():
if 'follow_Conv' not in name and 'linear' not in name:
params.requires_grad_(False)
else:
params.requires_grad_(True)
#定义优化器和损失函数
optimizer=optim.SGD([p for p in net.parameters() if p.requires_grad],lr=0.01,momentum=0.9,weight_decay=5e-4,nesterov=True)
loss=nn.CrossEntropyLoss()
lr_schedule=optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.5,patience=200,min_lr=1e-6)
start_epoch=0
#加载权重
if opt.weights.endswith('.pt') or opt.weights.endswith('.pth'):
ckpt=torch.load(opt.weights)
if opt.weights=='weights/mobilenet_v2-b0353104.pth':
weights={}
#官方预训练权重
module_lst = [i for i in net.state_dict()]
for idx, (k, v) in enumerate(ckpt.items()):
if net.state_dict()[module_lst[idx]].numel() == v.numel():
weights[module_lst[idx]] = v
net.load_state_dict(weights, strict=False)
else:
#我们自己训练的权重
net.load_state_dict(ckpt['model']) #加载权重
start_epoch=ckpt['epoch']+1
optim_pares=ckpt['optim']
optimizer.load_state_dict(optim_pares)
#开始训练
for epoch in range(start_epoch,opt.epoches):
#训练
mean_loss=train_one_epoch(net,optimizer,loss,lr_schedule,epoch,train_dataloader,device,opt.printf,opt.batch)
writer.add_scalar('train_loss',mean_loss,epoch)
#验证
val_accuracy=val(val_dataloader,net,device,epoch)
writer.add_scalar('val_acc',val_accuracy,epoch)
#保存模型
par_save_path=os.path.join(opt.savepath,'mobilenet_v2_{}.pth'.format(epoch))
save_params={
'model':net.state_dict(),
'epoch':epoch,
'optim':optimizer.state_dict()
}
torch.save(save_params,par_save_path)
if __name__ == '__main__':
parse=argparse.ArgumentParser()
parse.add_argument('--epoches',type=int,default=30,help='train epoches')
parse.add_argument('--batch',type=int,default=128,help='batch size')
parse.add_argument('--freeze',type=bool,default=False,help='freeze some weights')
parse.add_argument('--weights',type=str,default='weights/mobilenet_v2-b0353104.pth',help='last weight path')
parse.add_argument('--numworkers', type=int, default=4)
parse.add_argument('--savepath',type=str,default='weights',help='model savepath')
parse.add_argument('--printf',type=int,default=50,help='print training info after 50 batch')
parse.add_argument('--classNum',type=int,default=10,help='classes num')
opt=parse.parse_args()
print(opt)
writer=SummaryWriter('runs')
train(opt)import time
import torch
def train_one_epoch(model,optimizer,loss,lr_schedule,epoch,dataloader,device,printf,batch):
start=time.time()
all_loss=0
all_accNum=0
model.train()
for idx,(img,labels) in enumerate(dataloader):
img=img.to(device)
labels=labels.to(device)
out=model(img)
los=loss(out,labels)
optimizer.zero_grad()
los.backward()
optimizer.step()
all_loss+=los.item()
cur_acc=(out.data.max(dim=1)[1]==labels).sum()
all_accNum+=cur_acc
#每prinft输出一次训练效果
if (idx%printf)==0:
print('epoch:{} training:[{}/{}] loss:{:.6f} accuracy:{:.6f}% lr:{}'.format(epoch,idx,len(dataloader),los.item(),cur_acc*100/len(labels),optimizer.param_groups[0]['lr']))
lr_schedule.step(los.item())
end=time.time()
#训练完一次,输出平均损失以及平均准确率
all_loss/=len(dataloader)
acc=all_accNum*100/(len(dataloader)*batch)
print('epoch:{} time:{:.2f} seconds training_loss:{:.6f} training_accuracy:{:.6f}%'.format(epoch,end-start,all_loss,acc))
return all_loss
@torch.no_grad()
def val(dataloader,model,device,epoch):
start=time.time()
model.eval()
all_acc=0
for idx,(img,labels) in enumerate(dataloader):
img=img.to(device)
labels=labels.to(device)
out=model(img)
cur_accNum=(out.data.max(dim=1)[1]==labels).sum()/len(labels)
all_acc+=cur_accNum
end=time.time()
print('epoch:{} val_time:{:.2f} seconds val_accuracy:{:.6f}%'.format(epoch,end-start,all_acc*100/len(dataloader)))
return all_acc/len(dataloader)(三)Test
import torch
from PIL import Image
import torchvision.transforms as transforms
from model import MobileNet_v2
import argparse
def test(opt):
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
device='cuda' if torch.cuda.is_available() else 'cpu'
net=MobileNet_v2().to(device)
models=torch.load(opt.weights)
net.load_state_dict(models['model'])
img=Image.open(opt.picpath)
img=transform(img)
img=img[None].to(device)
with torch.no_grad():
net.eval()
out=net(img).data.max(dim=1)[1]
print('test result: {}'.format(opt.classes[out.item()]))
if __name__ == '__main__':
parse=argparse.ArgumentParser()
classes=['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
parse.add_argument('--weights',type=str,default='weights/mobilenet_v2_9.pth',help='weight path')
parse.add_argument('--picpath', type=str, default='test/test.jpeg', help='weight path')
parse.add_argument('--classes', type=list, default=classes, help='weight path')
opt=parse.parse_args()
test(opt)五、训练结果
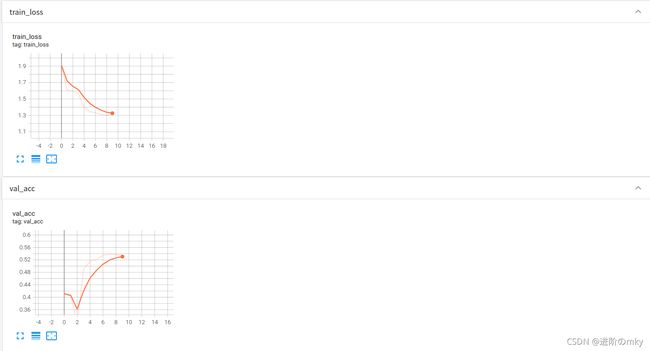
这里我迭代了10个epoch,准确率达到了53%左右;
可视化训练损失以及验证集准确率(在终端输入tensorboard --logdir=runs):
六、完整代码
代码地址:链接:百度网盘 请输入提取码 提取码:utey \
权重下载地址:https://download.pytorch.org/models/mobilenet_v2-b0353104.pth