numpy合并不同维度矩阵_机器学习Web应用:如何使用NumPy?
大多数数据在我们拿到时,其形式很不实用,无法直接用机器学习算法处理。如上一个例子所见(上一节) ,数据中有些元素可能缺失,或某些列不是数值型,因此无法直接用机器学习技术处理。因而,机器学习专家通常花费大量时间清洗和准备数据,转换数据的形式,以便进一步分析或做可视化处理。本节教你用NumPy和pandas库,用Python语言创建、准备和处理数据。matplotlib小节,将介绍Python绘图基础知识。NumPy教程结合Python shell进行讲解,但是代码的IPython notebook版和纯Python脚本版,都已放到作者GitHub主页chapter_1文件夹。pandas和matplotlib两个库的讲解则用IPython notebook。
1.2.1 NumPy的用法
Numerical Python或NumPy是Python的一个开源扩展包,是数据分析和高性能科学计算的基础模块。该库问世后,用Python处理大规模、多维数组和矩阵不再是梦想。对于常用数值计算,它提供预先编译好的函数。更进一步来讲,它提供一个巨大的数学函数库来支持数组运算。
该库提供以下功能
用于向量算术运算的快速、多维数组;
对数据中所有数组进行快速运算的标准数学函数;
线性代数运算;
排序、去重( unique )和集合运算;
统计和聚合数据。
比起Python的标准运算, NumPy的主要优势在于数组运算速度快。例如,用传统的求和方法,求10000000个元素的和:

与Numpy函数对比:

两种方法所用时间分别为2.1142539978和0.0807049274445。
1.数组创建
数组对象是NumPy库提供的主要功能。数组相当于Python的列表(list ) ,但数组所有元素的数值类型相同(通常为浮点型或整型)。借助array函数,可用列表定义一个数组对象,需为array函数传入两个参数:即将被转换为数组的列表、新生成的数组的类型:

反之,可用如下代码将数组转换为列表:


若想用现有数组,创建一个新的数组对象,则要用copy函数:

此外,还可以用同一个值填充数组,覆盖掉之前的值,得到一个元素全部相同的数组,例如:

还可以用np的子模块random随机选取元素创建数组。例如,将要创建的数组的长度作为permutation函数的参数传入,该函数返回一个由整数组成的随机序列:
另一种数组创建方法是用normal函数从一个正态分布中抽取一列数字:
参数0为正态分布的均值, 1为标准差,5表示抽取5个数字创建数组。若使用均匀分布, random函数将返回0到1之间(不包含0和1)的数字:
NumPy还提供几个创建二维数组(矩阵)的函数。例如, identity函数创建单位矩阵,其维度用参数来指定:

Eye函数返回第k条对角线上元素为1的矩阵。

创建新数组(1或2维)最常用的函数是zeros和ones ,它们按照指定的维度创建数组,并分别用0或1填充。示例如下:

而zeros_like和ones_like函数,创建的是跟现有数组元素的类型[7]和维度都相同的数组:

另外一种创建二维数组的方法是,用vstack函数(垂直方向合并)合并一维数组:

二维数组也可以用random子模块按照某种分布进行创建。例如,随机从0到1的均匀分布中选取数字作为数组元素,创建一个2x3型数组,方法如下:

另一种经常用来创建数组的分布是多元正态分布:

列表[10,0]是均值向量,[[3,1],[1,4]]是协方差矩阵,5是要抽取的元素数量。
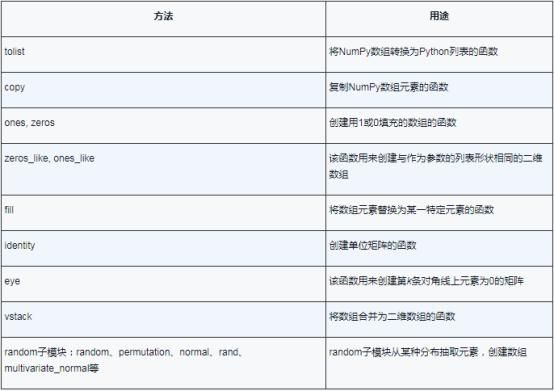
表1.1
2. 数组操作
访问列表元素、切片以及其他python列表的所有常见操作,均能以相同或相似的方式作用于数组:

数组包含的不同元素也可以获取到,用unique函数即可:
数组元素的排序也可以用sort函数,数组的索引用argsort函数获取:

用shuffle函数也可以调整数组元素,使其随机排列:

Numpy数组类似,也有一个内置函数array_equal,用来比较两个数组是否相等[8]:
然而,多维数组与列表操作不同。事实上,多维列表各维度用逗号分隔的形式依次指定(而列表用方括号[9])。例如,二维列表(矩阵)元素访问方法如下:

对数组的各维进行切片操作使用英文冒号,冒号前后为位于起始位置的元素的索引:

仅用冒号:,不用数字,表示冒号所在轴上的所有元素都在切片范围之内:

Flatten函数可将多维数组变为一堆数组:

我们还可以查看数组对象,获取相关信息。用shape属性,可得到数组的大小:
该例中,arr是一个2行3列的矩阵。Dtype属性返回数组元素的类型:
数值类型float64用来存储双精度(8字节)实数(类似于Python的标准foat类型)。其他数据类型有int64, int32和字符串。数组的数据类型可以转换。例如:

Len函数返回数组第一维的长度:

关键字in,类似于它在python for循环中的用法,可用来判断数组是否包含某个元素:

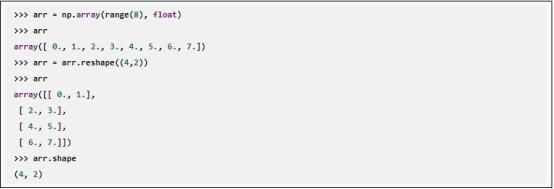
Reshape函数可调整数组的维度,例如8行1列的矩阵可调整为4行2列的矩阵:
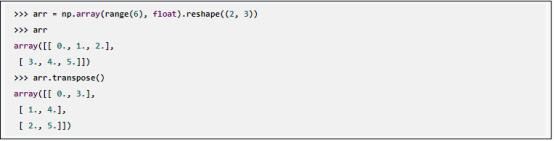
此外,还支持矩阵的转置运算;也就是说,用transpose函数可互换两个维度,创建一个新数组:
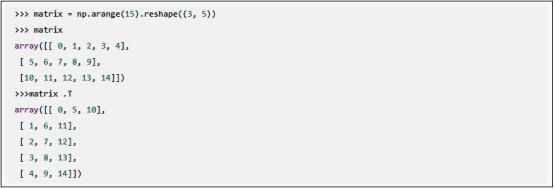
数组还可以用T属性实现转置:
另一种调整数组元素位置的方法是,用newaxis函数增加维度:
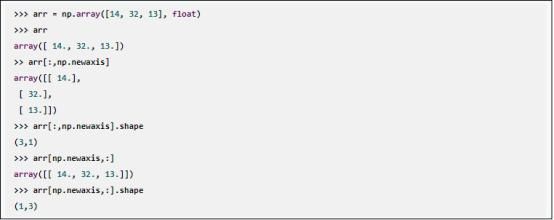
上述例子,两个新数组都是二维的。由newaxis生成的第二个数组长度为1。
NumPy数组的连接操作用concatenate函数,句法形式取决于数组的维度。多个一维数组可相继连接,将要连接的多个数组置于元组中作为参数传入即可:

多维数组必须指定沿哪条轴连接。否则,Numpy默认沿第一条轴连接:

将大量数据保存为二进制文件而不用原格式存储,这样的情况很常见。NumPy的tostring函数可将数组转化为二进制字符串。当然,这个过程是可逆的, fromstring函数可将二进制字符串还原为数组。例如:

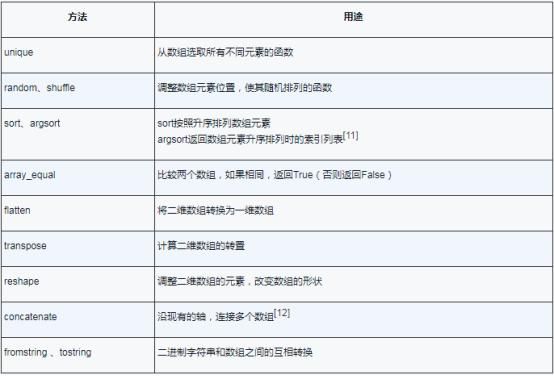
表1.2
3. 数组运算
NumPy数组显然支持常见的数学运算。例如:
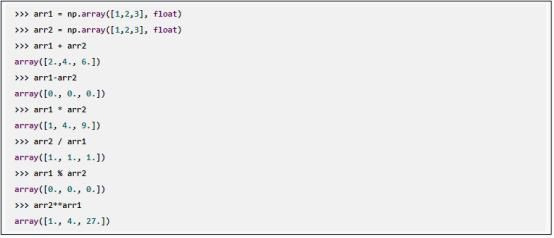
既然上述运算都作用于元素级别,这就要求参与运算的数组大小相同。如果该条件不能满足,就会返回错误:

上述错误信息的意思是无法对对象进行广播(broadcast ) ,因为大小不同的数组参与运算的唯一方法叫作广播。广播的意思是数组维度不同时,维度少的数组将多次重复自身,直到它跟另外一个数组维度相同。看下面的示例:
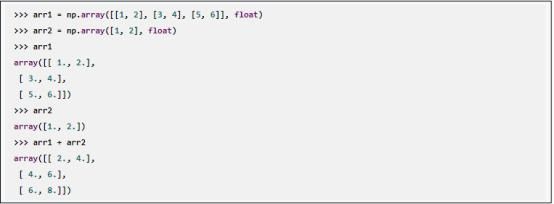
arr2被广播成大小跟arr1相同的二维数组。因而,对于arr1的每一维, arr2都重复自身一次,相当于arr2变换为下面这个数组后再参加运算:
如要明确指定数组的广播方式,可用newaxis常量:

跟python列表不同的是,数组支持按条件查询,用布尔数组过滤元素就是一个典型的例子:

可以用多个布尔表示式获取数组的子集:

我们可以根据索引选取元素,用目标元素的索引构造一个数据类型为整型的数组,然后,将索引数组放到目标数组的后面,并用方括号括起来。例如:

上述第3行代码,表示按照arr2指定的索引顺序,从数组arr1中选取相应的元素,也就是选取arr1的第0、第1、第1、第3、第1、第1和第1个元素。用列表存储目标元素的索引,可以达到同样的选取效果:

多维数组的选取操作,需要使用多个一维度的索引数组,每个维度对应一个索引数组。索引数组放到Python列表中,再将Python列表置于多维数组后面的方括号之中。
第1个种子数组( selection array )存储矩阵元素的行号,第2个种子数组存储列号。例如:

arr2的元素为arr1元素的行号,而arr3的元素则为arr1元素的列号,因此从arr1选取的第1个元素为位于第1行、第1例的13。
take函数支持以索引数组为参数,从调用它的数组选取元素,效果等同于上面的方括号选择法:

用axis参数指定维度,task函数可从调用它的多维数组、沿指定维度选取一部分元素:
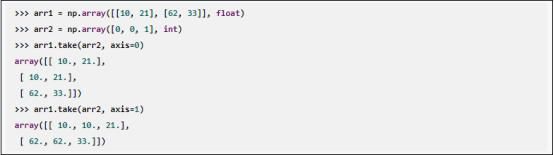
put函数为take函数的逆操作,它有两个参数:将元素放到什么位置(索引列表)、被投放的元素来自哪个数组。put函数将一个数组的元素放到调用该函数的另一个数组的指定位置:

本节最后,我们想提醒你注意,二维数组的乘法运算也是元素级的(但矩阵乘法不是):


表1.3
4.线性代数运算
矩阵之间最常用的运算是,矩阵与其转置矩阵的内积XTX,计算内积,用np.dot函数 :
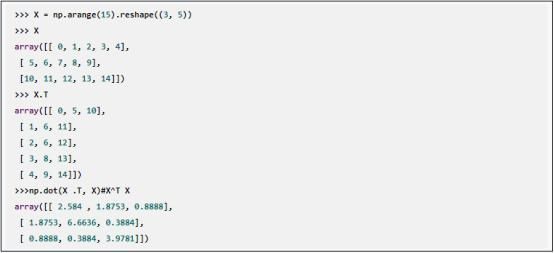
有几个函数可直接计算数组(矩阵或向量)不同类型的积(内积、外积、向量积)。
一维数组(向量)的内积与点积相同:

NumPy的linalg模块,实现了矩阵的多种线性代数运算。例如,计算矩阵的行列式的值:

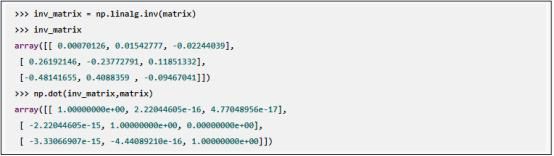
Inv函数生成矩阵的逆矩阵:
矩阵的特征值(eigenvalues)和特征向量(eigenvectors)计算方法很简单:


表1.4
5.统计和数学函数
NumPy提供一组计算数组元素统计信息的函数。聚合型运算,比如求和、均值、中位数和标准差,可通过访问数组的相应属性得到。例如,随机选取元素(服从某正态分布) ,创建一个数组,我们可以用以下两种方法计算数组元素的均值:

所有这一类函数见表1.5。

表1.5
本文节选自《机器学习Web应用》

这是一本结合Python语言讲述Web下机器学习的图书,本书内容全面,既能够让读者熟悉最基本的机器学习的相关概念,也能够了解Web下数据挖掘的工具和技术,除此之外,书中还会介绍与Django框架有关的知识以及数据库管理等内容,帮助读者掌握聚类和分类技术并用Python实现它们。