Albumentations概述:用于图像增强的开源库
原生PyTorch和TensorFlow增强器有一个很大的缺点——它们不能同时增强图像及其掩码、边界框或关键点位置。所以有两种选择——要么自己编写函数,要么使用第三方库。我两个都试过了,第二个选择更好.
为什么是Albumentations?
Albumentations是我尝试的第一个库,我坚持使用它,因为:
它是开源的,
简单
快速
拥有60多种不同的增强
有案例
而且,最重要的是,可以同时增强图像及其掩码,边界框或关键点位置。
还有两个类似的库——imgauge和Augmentor。不幸的是,我无法提供任何比较,因为我还没有尝试过。到目前为止,Albumentations的数量已经足够了。
简短教程
在这个简短的教程中,我将演示如何为分割和对象检测任务增强图像—只需几行代码即可轻松完成。
如果你想学习本教程:
安装Albumentations。我真的建议你检查一下是否有最新的版本,因为旧的版本可能有问题。我使用的是“1.0.0”版本,它运行良好。
下载下面带有标签的测试图像。这只是来自COCO数据集的随机图像。我对它做了一些修改,并以Albumentations要求的格式存储了它。
在这里下载:https://notrocketscience.blog/wp-content/uploads/2021/07/image_data.pickle.zip。
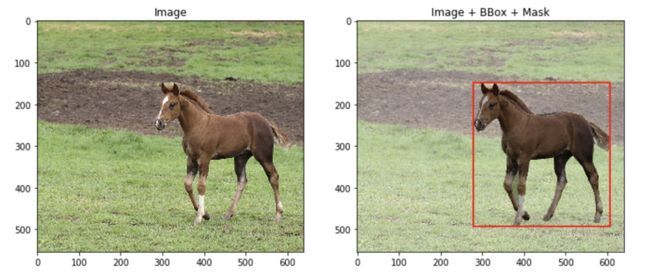
让我们加载图像、其二进制像素分割掩码和边界框。边界框定义为4元素列表-[x_min,y_min,width,height]。
import pickle
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
# 加载数据
with open("image_data.pickle", "rb") as handle:
image_data = pickle.load(handle)
image = image_data["image"]
mask = image_data["mask"]
bbox = image_data["bbox_coco"]
# 可视化数据
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
ax[0].imshow(image)
ax[0].set_title("Image")
ax[1].imshow(image)
bbox_rect = patches.Rectangle(
bbox[:2], bbox[2], bbox[3], linewidth=2, edgecolor="r", facecolor="none"
)
ax[1].add_patch(bbox_rect)
ax[1].imshow(mask, alpha=0.3, cmap="gray_r")
ax[1].set_title("Image + BBox + Mask")
plt.show()加载并可视化图像后,你应获得以下信息:
现在我们可以从Albumentations开始。这里的转换定义非常类似于PyTorch和TensorFlow(Keras API):
通过使用Compose对象组合多个增强来定义转换。
每个增强都有参数“p”,即要应用的概率,另外还有增广特定的参数,如RandomCrop的“width”和“height”。
使用定义的变换作为函数来增强图像及其掩码。此函数返回一个带有键--“image”和“mask”的字典。
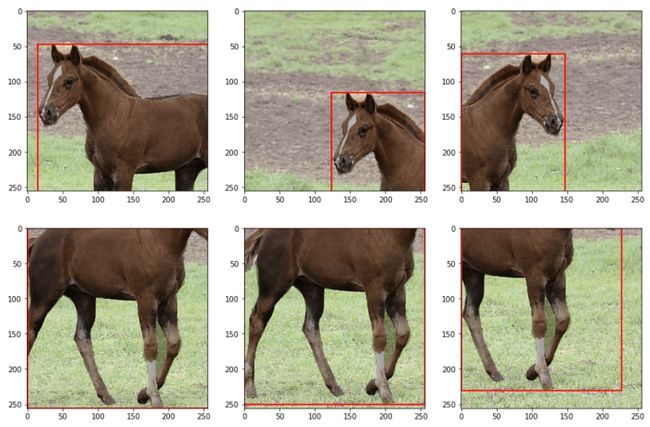
下面是关于如何使用随机256×256裁剪(始终)和水平翻转(仅在50%的情况下)增强图像(及其掩码)的代码。
import albumentations as A
# 定义增强
transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
])
# 增强和可视化图像
fig, ax = plt.subplots(2, 3, figsize=(15, 10))
for i in range(6):
transformed = transform(image=image, mask=mask)
ax[i // 3, i % 3].imshow(transformed["image"])
ax[i // 3, i % 3].imshow(transformed["mask"], alpha=0.3, cmap="gray_r")
plt.show()因此,你应该得到这样的东西。你的增强图像将不同,因为Albumentations会产生随机变换。有关掩码增强的详细教程,请参阅原始文档:https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/。
用于对象检测的边界框增强。它类似于分段掩码的增强,但是:
此外,定义“bbox_params”,其中指定边界框的格式和边界框类的参数
coco是指coco数据集格式的边界框-[x_min,y_min,width,height]。参数'bbox_classes'稍后将用于传递边界框的类。transform接受边界框作为列表列表。此外,即使图像中只有一个边界框,也需要边界框类(作为列表)。
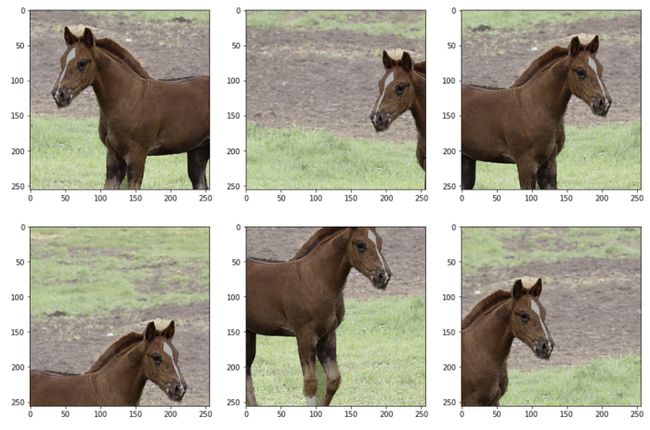
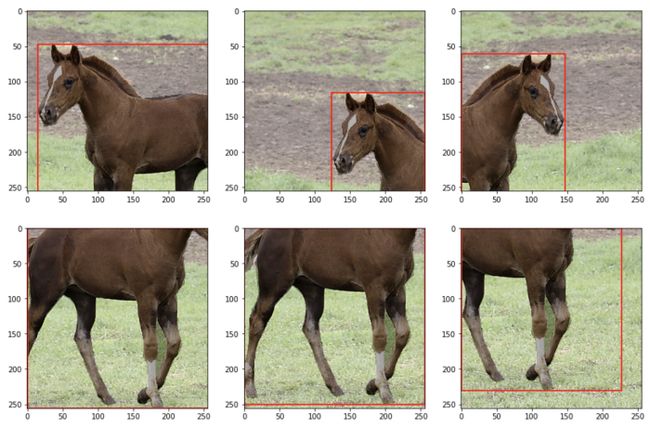
下面是同时对图像及其边界框进行随机裁剪和水平裁剪的代码。
# 定义增强
transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
], bbox_params=A.BboxParams(format='coco', label_fields=["bbox_classes"]))
# 扩充和可视化
bboxes = [bbox]
bbox_classes = ["horse"]
fig, ax = plt.subplots(2, 3, figsize=(15, 10))
for i in range(6):
transformed = transform(
image=image,
bboxes=bboxes,
bbox_classes=bbox_classes
)
ax[i // 3, i % 3].imshow(transformed["image"])
trans_bbox = transformed["bboxes"][0]
bbox_rect = patches.Rectangle(
trans_bbox[:2],
trans_bbox[2],
trans_bbox[3],
linewidth=2,
edgecolor="r",
facecolor="none",
)
ax[i // 3, i % 3].add_patch(bbox_rect)
plt.show()下面是结果。如果你需要一些特定的边界框扩展,请参阅原始文档:https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/。
同时增强多个目标。除了允许同时增加多个掩码或多个边界框外,Albumentations还具有同时增加不同类型标签的功能,例如,掩码和边界框。
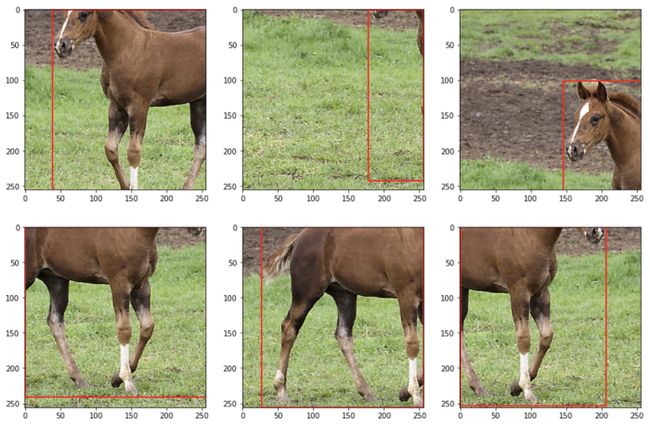
调用“transform”时,只需将你拥有的一切都给它:
# 定义增强
transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
], bbox_params=A.BboxParams(format='coco', label_fields=["bbox_classes"]))
# 增强和可视化
bboxes = [bbox]
bbox_classes = ["horse"]
fig, ax = plt.subplots(2, 3, figsize=(15, 10))
for i in range(6):
transformed = transform(
image=image,
mask=mask,
bboxes=bboxes,
bbox_classes=bbox_classes
)
ax[i // 3, i % 3].imshow(transformed["image"])
trans_bbox = transformed["bboxes"][0]
bbox_rect = patches.Rectangle(
trans_bbox[:2],
trans_bbox[2],
trans_bbox[3],
linewidth=2,
edgecolor="r",
facecolor="none",
)
ax[i // 3, i % 3].add_patch(bbox_rect)
ax[i // 3, i % 3].imshow(transformed["mask"], alpha=0.3, cmap="gray_r")
plt.show()你的结果将如下图所示。这里有更详细的文档:https://albumentations.ai/docs/getting_started/simultaneous_augmentation/。
Albumentations有更多的功能可用,如关键点的增强和自动增强。它包括大约60种不同的增强类型
最有可能的情况是,你将使用Albumentations作为PyTorch或TensorFlow训练管道的一部分,因此,我将简要介绍如何做到这一点。
PyTorch。创建自定义数据集时,请在__init__函数中定义Albumentations transform,并在__getitem__函数中调用它。PyTorch模型要求输入数据为张量,因此在定义“transform”(Albumentations教程中的一个技巧)时,请确保添加“ToTensorV2”作为最后一步。
from torch.utils.data import Dataset
from albumentations.pytorch import ToTensorV2
class CustomDataset(Dataset):
def __init__(self, images, masks):
self.images = images # 假设这是一个numpy图像列表
self.masks = masks # 假设这是一个numpy掩码列表
self.transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
ToTensorV2,
])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
"""返回单个样本"""
image = self.images[idx]
mask = self.masks[idx]
transformed = self.transform(image=image, mask=mask)
transformed_image = transformed["image"]
transformed_mask = transformed["mask"]
return transformed_image, transformed_maskTensorFlow(KerasAPI)还允许创建自定义数据集,类似于PyTorch。因此,在__init__函数中定义Albumentations转换,并在__getitem__函数中调用它。很简单,不是吗?
from tensorflow import keras
class CustomDataset(keras.utils.Sequence):
def __init__(self, images, masks):
self.images = images
self.masks = masks
self.batch_size = 1
self.img_size = (256, 256)
self.transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
])
def __len__(self):
return len(self.images) // self.batch_size
def __getitem__(self, idx):
"""返回样本batch"""
i = idx * self.batch_size
batch_images = self.images[i : i + self.batch_size]
batch_masks = self.masks[i : i + self.batch_size]
batch_images_stacked = np.zeros(
(self.batch_size,) + self.img_size + (3,), dtype="uint8"
)
batch_masks_stacked = np.zeros(
(self.batch_size,) + self.img_size, dtype="float32"
)
for i in range(len(batch_images)):
transformed = self.transform(
image=batch_images[i],
mask=batch_masks[i]
)
batch_images_stacked[i] = transformed["image"]
batch_masks_stacked[i] = transformed["mask"]
return batch_images_stacked, batch_masks_stacked希望本教程鼓励你下次在处理分割、对象检测或关键点定位任务时尝试Albumentations。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
