RNN lstm
文章目录
- 什么是RNN
-
- RNN工作原理图解
- 多种RNN形态
- RNN的公式原理
- pytorch RNN 样例
- RNN实践
- lstm 案例
-
- 踩坑 module ‘torchtext.data‘ has no attribute ‘Field
- 踩坑 en_core_web_sm
- 相关教程
什么是RNN
阅读ytb视频莫烦: 什么是循环神经网络 RNN (深度学习)? What is Recurrent Neural Networks (deep learning)?。
RNN工作原理图解
RNN是怎样工作的?假如在t时刻,神经网络输入x(t),神经网络会计算状态s(t),并输出y(t)。

到t+1时刻,输入为x(t+1),神经网络会根据s(t)和s(t+1)来输出y(t+1)。

多种RNN形态
RNN经过适当组合,有不同的输入和输出形式,从而能解决不同领域的问题。比如输入一张图片,输出描述它的一段话。

或者输入一段中文,输出一段英文。

RNN的公式原理
传统RNN的实现主要是下图中的红框部分。
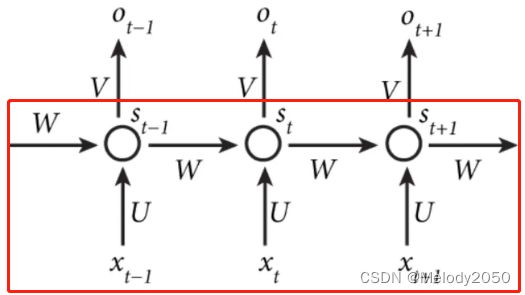
用公式表达如下:

其中 o t o_t ot并不是最重要的部分,而输出 s 1 , s 2 , . . . , s t s_1, s_2, ..., s_t s1,s2,...,st是关键。
pytorch RNN 样例
根据pytorch官方文档,torch.nn.RNN.html可知,RNN计算隐藏层的方式如下,相当于分别对上个隐藏层输出 h t − 1 h_{t-1} ht−1与 x t x_t xt作线性转换,相加后经过激活层tanh或relu。

我们结合代码案例,对这个API做简化版的解释
import torch
from torch import nn
rnn = nn.RNN(10, 20)
input = torch.randn(5, 3, 10)
h0 = torch.randn(1, 3, 20)
output, hn = rnn(input, h0)
# torch.Size([5, 3, 20])
# torch.Size([1, 3, 20])
# tensor(True)
print(output.shape)
print(hn.shape)
print(torch.all(output[-1] == hn))
构造函数的参数简化版解释如下:
- input_size – The number of expected features in the input x
- hidden_size – The number of features in the hidden state h
所以 nn.RNN(10, 20):的意思是,输入的每个单词长度为10,输出的每个向量长度为20。另外,batch_first 参数默认为False,它会影响输入的维度顺序,当为False时,输入维度是(seq, batch, feature),为True时是(batch, seq, feature)。
输入的参数简化版解释如下:
输入: input, h_0
- input:
batch_first默认为False时,维度为(seq, batch, feature) - h_0: 在本例默认其它参数情况下,维度为(1, batch, feature)
所以,代码块中的input和h0变量分别代表各个时刻t的输入,以及初始的隐藏层状态。
输出的参数简化版解释如下:
输出: output, h_n
- output: 在其它参数默认时,维度为(sequence, batch, H o u t H_{out} Hout)。它代表每个时刻t的隐藏层输出 h 1 , h 2 , . . . , h T h_1, h_2, ..., h_T h1,h2,...,hT。
- h_n: 在其它参数默认时,维度为(1, batch, H o u t H_{out} Hout),它代表最后时刻T的隐藏层输出 h t h_t ht。
所以,代码块中output的维度是[5,3,20],其中batch是3,序列长度为5(有5个单词)。 而hn的维度是[1,3,20],每个batch都取了 h T h_T hT。同时,print(torch.all(output[-1] == hn))输出为True说明hn就是output[-1],hn是最后时刻T的隐藏层输出。
总结而言,我们将一个batch为3,每句话有5个单词,每个单词向量长度为10的tensor输入到rnn。它将输出batch为3,每句话有5个单词,每个单词向量长度为20的变量output,其中hn是和output[-1]等价。在下图中标注了每个变量对应图中的部分。

RNN实践
pytorch教程SEQUENCE MODELS AND LONG SHORT-TERM MEMORY NETWORKS 的模型代码很清晰,架构完整,但是缺乏训练数据集,training_data变量的数据很匮乏。
https://towardsdatascience.com/lstm-text-classification-using-pytorch-2c6c657f8fc0
训练集在 https://www.kaggle.com/datasets/nopdev/real-and-fake-news-dataset
自定义Dataset的用法,可学习知识点pytorch dataset
lstm 案例
参考swarnabha/pytorch-text-classification-torchtext-lstm,讲了一个用LSTM训练kaggle数据集的案例。
第一步,使用scikit-learn的工具方法切分pandas dataframe形式的数据集
# split data into train and validation
train_df, valid_df = train_test_split(train)
print(train_df.head())
print(valid_df.head())
第二步,设置tokenize策略
TEXT = data.Field(tokenize = 'spacy', include_lengths = True)
LABEL = data.LabelField(dtype = torch.float)
利用Field,将Pandas dataframe包装成torchtext dataset
fields = [('text',TEXT), ('label',LABEL)]
train_ds, val_ds = DataFrameDataset.splits(fields, train_df=train_df, val_df=valid_df)
第三步,构建词库,对单词作one-hot编码。
TEXT.build_vocab(train_ds,
max_size = MAX_VOCAB_SIZE,
vectors = 'glove.6B.200d',
unk_init = torch.Tensor.zero_)
LABEL.build_vocab(train_ds)
第四步,切分数据集
train_iterator, valid_iterator = data.BucketIterator.splits(
(train_ds, val_ds),
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)
最后,循环读取批次,将embedding送入lstm网络。
for epoch in range(num_epochs):
train_loss, train_acc = train(model, train_iterator)
踩坑 module ‘torchtext.data‘ has no attribute ‘Field
由于版本兼容性问题,运行代码可能遇到错误AttributeError: module ‘torchtext.data‘ has no attribute ‘Field‘,也可以参考attributeerror-module-torchtext-data-has-no-attribute-field。使用torchtext 0.10(可能会安装旧版的pytorch,所以用conda开个新环境,凑合着用吧),然后from torchtext import data改成from torchtext.legacy import data。
阅读torchtext的版本更新与api变迁可以得知APi变迁。
- 在0.8版本以前,是
from torchtext import data。 - 在0.9到0.12版本之间,是
from torchtext.legacy import data。 - 在0.12版本之后,该data库已经删除,如果坚持要用,需要参考新版API教程。
总之,要复用教程的API,最好用torchtext 0.9或0.10。pytorch-sentiment-analysis列出了一些基于该版本API的教程,可以参考它的第一个教程运行下。
踩坑 en_core_web_sm
如果运行遇到以下问题,说明需要下载en_core_web_sm并安装。
Can’t find model ‘en_core_web_sm’. It doesn’t seem to be a Python package or a valid path to a data directory.
参考NLP Spacy中en_core_web_sm安装问题,及最新版下载地址,到github的release界面搜索"en_core_web_sm",找最新版的压缩包下载并用pip install 安装。
笔者下载的是3.4.1版本。如果下载2.5.2,可能会出现cannot read config之类的错误。笔者不知道怎么解决。
相关教程
bentrevett/pytorch-sentiment-analysis的教程1提到了Field是如何帮助构建vocab的,以及如何对句子的单词作清洗工作(为了减少要训练的embedding的数,保留最高频率的单词)。