Dynamic Zoom-in Network for Fast Object Detection in Large Images 阅读笔记
Dynamic Zoom-in Network for Fast Object Detection in Large Images 阅读笔记
- 摘要
- 1.介绍
- 2. 相关工作
- 3. Dynamic zoom-in network
-
- 3.1. Problem formulation
- 3.2. Zoom-in accuracy gain regression network
- 3.3. Zoom in Q function learning network
- 4. Experiments
-
- 4.1. Baseline methods
- 4.2. Variants of our framework
- 4.3. Evaluation metric
- 4.4. Implementation details
- 4.5. Qualitative results
- 4.6. Quantitative evaluation
摘要
我们引入了一个通用框架, 它降低了物体检测的计算成本, 同时保留了不同大小的物体在高分辨率图像中出现的情况的准确性。检测过程中以coarse-to-fine的方式进行,首先对图像的down-sampled版本,然后在一系列较高分辨率区域上,识别出哪些可能提高检测精度。在强化学习的基础上, 我们的方法包括一个模型 (R-net), 使用粗检测结果来预测在更高分辨率下分析一个区域的潜在精度增益, 另一个模型 (Q-net), 继续选择区域zoom-in.在Caltech Pedestrians数据集上的实验表明,我们的方法将处理像素的数量减少了50%以上,而不会降低检测精度。我们的方法的优点在从YFCC100M数据集收集的高分辨率测试集中变得更加突出,其中我们的方法保持高检测性能,同时将处理像素的数量减少约70%,并且检测时间减少超过50%。
1.介绍
最近的卷积神经网络(CNN)检测器应用于具有相对低分辨率的图像,例如VOC2007 / 2012(约500400)[10,11]和MS COCO(约600400)[19]。在如此低的分辨率下,卷积的计算成本很低。然而,日常设备的分辨率已经快速超过标准计算机视觉数据集。例如,4K智能手机的相机分辨率为2,1603,840像素,单反相机可以达到6,0004,000像素。将最先进的CNN检测器直接应用于那些高分辨率图像需要大量的处理时间。另外,卷积输出映射对于当前GPU的存储器来说太大。在主动机器人场景中出现了相关问题,其中机器人必须机械地平移,倾斜和缩放以获取和处理所有相关像素以支持控制机器人所需的视觉任务。在这种情况下,将视觉检测器应用于尽可能少的平移,倾斜和缩放设置捕获的图像非常重要。
先前的工作通过简化网络架构[12,30,7,18]来解决其中一些问题,以加速检测并减少GPU内存消耗。但是,这些模型是针对特定网络结构量身定制的,可能无法很好地概括为新架构。更普遍的方向是将检测器视为一个黑匣子,明智地应用该检测器来优化精度和效率。例如,可以将图像划分为满足存储器约束的子图像并将CNN应用于每个子图像。然而,这种解决方案在计算上仍然是繁重的。通过在下采样图像上运行现有检测器,还可以加速检测过程并降低存储器需求。但是,小的对象可能变得太小而无法在下采样图像中检测到。对象提议方法是大多数CNN探测器的基础,将昂贵的分析限制在可能包含感兴趣对象的区域[9,27,33,32]。然而,在大图像中实现对小物体的召回率所需的对象建议的数量非常高,这导致巨大的计算成本。
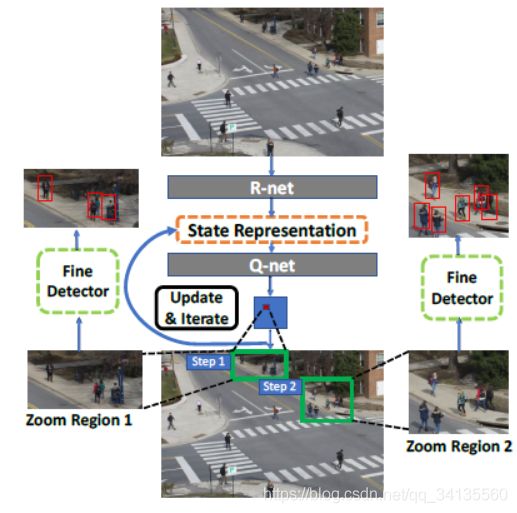
我们的方法如图1所示。我们通过首先对图像的down-sampled版本执行粗略检测,然后依次选择以更高分辨率分析的有希望提高监测的区域来加速对象检测。我们采用强化学习在检测精度和计算成本方面对long-term reward进行建模,并动态选择一系列区域以便以更高的分辨率进行分析。我们的方法包括两个网络::zoom-in accuracy gain regression network(R-net)自动学习粗略和精细检测之间的相关性,并预测Zoom in区域的准确度增益; zoom-in Q function network 学习通过分析R-net的输出和先前分析的区域的历史来依次选择最佳缩放定位和缩放比例。
实验证明,在检测精度可以忽略不计的情况下,我们的方法在Caltech行人检测数据集[10]上,处理的像素减少了50%以上,平均检测时间减少了25%,从YFCC100M [16]收集的高分辨率数据集中,处理的像素减少了约70%,平均检测时间减少了50%以上,这些数据集具有不同大小的行人。我们还将我们的方法与最近的SSD[24,20]进行了比较,以显示我们在处理大型图像时的优势。
2. 相关工作
CNN检测:有效分析高分辨率图像的一种方法是改进底层检测器。 Girshick [16]通过分享proposal之间的卷积特征来加速基于CNN的区域proposal[17]。 Ren等人提出了 Faster R-CNN [33],这是一种完全端到端的pipeline,共享proposal生成和物体检测之间的特征,提高了准确性和计算效率。最近,single-shot detectors[27,31,32]在实时性能方面受到了很多关注。这些方法删除proposal生成阶段并将检测制定为回归问题。虽然这些检测器在PASCAL VOC [12,13]和MS COCO [26]数据集上表现良好,这些数据集通常在分辨率相对较低的图像中包含较大的物体,但它们不能在具有可变大小物体的大图像上进行概括。另外,由于大量的卷积操作,其处理成本随着图像大小而急剧增加。
Sequential search:处理大图像尺寸的另一种策略是避免处理整个图像,而是顺序地研究小区域。
然而,大多数现有工作集中在挖掘信息区域以提高检测准确性而不考虑计算成本。 Lu等人[28]通过适应性地关注可能包含物体的子区域来改善定位。Alexe等人[1]根据已经看到的提高检测准确性的顺序调查定位。然而,所提出的方法引入了大的开销,导致检测时间很长(每个图像的每个物体类别大约5s)。 张等人 [31]通过惩罚初始对象提议的不准确位置来提高检测准确度,这为检测时间带来了超过15%的开销。
Sequential search过程还可以利用来自源的上下文提示,例如场景分割。现有的方法已经为各种物体定位任务探索了这个想法[8,37,30]。这样的线索也可以被纳入我们的框架内(例如,作为预测zoom-inreward的输入)。但是,我们专注于仅使用粗略检测作为Sequential search的指导,并为将来的工作留下额外的上下文信息。其他以前的工作[25]采用了coarse-to-fine的策略来加速检测,但这项工作并没有顺序选择有前途的区域。
Reinforcement learning (RL): RL a 是学习Sequential search策略的流行机制,因为它允许模型考虑一系列操作而不是单个操作的效果。Ba等人使用RL在[3]中训练基于attention的模型以依次选择最相关的区域用于物体识别,并且Jie等人[20]选择区域以top-down的搜索方式进行定位。但是,这些方法需要大量的选择步骤,并可能导致运行时间过长。 Caicedo等人 [7]为物体定位设计了一个主动检测模型,该模型利用Deep Q Networks(DQN)[29]学习一个long-term reward函数,以便顺序转换初始边界框直到它收敛到一个物体。然而,正如文献[7]报道的那样,在典型的Pascal VOC image上,box transformation需要大约1.5s的检测时间,这比最近的检测器慢得多[33,27,32]。另外,[7]没有明确考虑选择成本。尽管RL隐含地迫使算法采取最小步数,但我们需要明确惩罚成本,因为每一步都会产生高成本。例如,如果我们不惩罚成本,算法将倾向于zoom-in整个图像。现有工作已经提出了将RL应用于RL in cost sensitive settings的方法[18,22]。我们遵循[18]的方法,将reward函数看作精度和成本的线性组合。
3. Dynamic zoom-in network
我们的工作采用了coarse-to-fine的策略,在低分辨率下应用粗检测器,并使用该检测器的输出来指导深度搜索高分辨率物体。直觉是,虽然粗检测器不如精细检测器那样准确,但它将识别需要进一步分析的图像区域,仅在有希望的区域中产生高分辨率检测的成本。我们利用两个主要组成部分:1)学习粗略和精细探测器之间统计关系的机制,以便我们可以在得到粗略探测器输出的情况下,预测哪些区域需要zoom-in;2)在给定粗检测器输出和已经由精细检测器分析的区域的情况下,选择以高分辨率分析的区域序列的机制。
我们的流程如图2所示。我们学习了一种策略,该策略模拟了以有限的成本最大化整体检测精度的长期目标。
。
3.1. Problem formulation
我们的工作被制定为马尔可夫决策过程(MDP)[4]。在每个步骤中,系统观察当前的状态,评估采取不同行动的潜在成本和回报,并选择具有最大long-term cost-aware 回报的行动。
Action: 我们的算法顺序的分析每个区域zoom-in成高分辨率的回报。在这种情况下,action对选择要以高分辨率分析的区域。每个action a, 由元组(x,y,w,h)表示,(x,y)表示的是位置,(w,h)指定区域的大小。在每一步,算法对潜在的action评分(一个矩形列表区域)(采取这些action潜在的长期回报)(即把这些区域用于高分辨率分析的回报)。
**State:**信息表示的两种编码种类:
1)尚待分析的区域的预测准确度增益;
2)已经以高分辨率分析的区域的历史(同一区域不应多次放大)。
我们设计了一个zoom-in accuracy gain regression network(R-net)学习信息精度增益图(AG图)作为可以成功学习zoom in Q函数的状态表示。AG map的长宽尺寸跟原始输入图像一样大。AG map每个像素的值是如果输入图像中对应位置的像素被放大区域包括,则可以提高检测精度的估计值。结果,AG map提供用于选择不同action对检测准确度增益。在采取动作之后,与AG map中的所选区域相对应的值相应地减小,因此AG map可以动态地记录动作历史。
Cost-aware reward function:(具有成本意识的奖励函数)状态表示对在每个图像子区域上放大的预测精度增益进行编码。为了在计算有限的情况下保持高精度,我们为action定义了Cost-aware reward function。给定一个state S,一个action a,Cost-aware reward function同时考虑成本增加和准确性改进为每个action(放大区域)打分。根据【15】,我们定义奖励函数
R(s,a)为:

其中(x,y)表示点(x,y)在action a选择的区域内,变量b表示action a 选择的区域内包含的像素的总数,B是整个图像像素的总数。第一项(见方程3)衡量检测精度的提升。第二项表示放大成本。精度和计算之间的权衡取决于参数 λ \lambda λ。在训练期间,Q-net使用此奖励函数来计算采取行动的直接奖励,并通过Q-learning来学习长期奖励函数[28]。
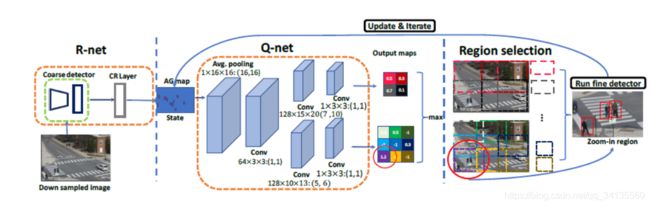
图2:给定一个down-sampled图像作为输入,R-net生成一个initial accuracy gain(AG)映射,指示不同区域(初始状态)的潜在zoom-in精度增益。迭代地在AG图上应用Q-net来选择区域。一旦选择了一个区域,AG映射将被更新以反映action的历史。对于Q-net,使用两条并行pipelines,每条pipeline输出一个动作reward映射,对应于选择具有特定大小的zoom-in区域。映射的价值表示action以低成本提高准确性的可能性。来自所有映射的action reward被认为是在每次迭代中选择最佳zoom-in区域。符号128×15×20:(7,10)表示128个大小为15×20的卷积核,高度/宽度为7/10的步长。输出映射中的每个网格单元都被赋予一种独特的颜色,并且在图像上绘制相同颜色的边界框以表示相应的缩放区域大小和定位。
3.2. Zoom-in accuracy gain regression network
The zoom-in accuracy gain regression network (R-net)基于粗略检测结果预测放大特定区域的准确度增益。R-net在成对的粗略和精细检测上进行训练,以便它可以观察它们如何相互关联以获得合适的精度增益。为此,我们将两个预先训练好的Faster-RCNN [25]探测器应用于一组训练图像,并获得两组图像检测结果:1)在下采样图像中用低分辨率的检测 { ( d i l , p i l , f i l ) } \lbrace(d^l_{i},p^l_{i},f^l_{i})\rbrace {(dil,pil,fil)},在每张图像的原始版本用高分辨率的检测 { ( d j h , p j h ) } \lbrace(d^h_{j},p^h_{j})\rbrace {(djh,pjh)},其中d是监测的bounding box,p是为目标的概率,是从Faster R-CNN网络的fc7层获得的高维特征向量。我们使用上标h和l来表示原始(高分辨率)和下采样(低分辨率)图像。我们使用上标i和h来表示原始(高分辨率)和下采样(低分辨率)图像。对于模型来了解高分辨率检测是否改善了整体结果,在训练时给定一组粗略检测,我们引入了match layer匹配层,该匹配层将两个检测器产生的检测结果相关联。在这一层中,我们将粗略和精细检测proposal配对,并在它们之间生成一组对应关系。下采样图像中的proposals i 和原始图像中的proposal j 被定义为相关,如果他们有足够大重叠,即IOU { ( d i l , d j h ) } \lbrace(d^l_{i},d^h_{j})\rbrace {(dil,djh)}>0.5。
给定一组相关关系 { ( d k l , p k l , p k h , f k l ) } \lbrace(d^l_{k},p^l_{k},p^h_{k},f^l_{k})\rbrace {(dkl,pkl,pkh,fkl)}我们估计粗略检测proposal的放大精度增益。检测器只能处理一系列尺寸的物体,因此将检测器应用于原始图像并不总能产生最佳精度。例如,如果检测器在大多数较小的物体上进行训练,则可以在较低分辨率下以较高的准确度检测较大的物体。因此,我们使用 ∣ g k − p k l ∣ − ∣ g k − p k h ∣ \vert g_{k}-p^l_{k}\vert-\vert g_{k}-p^h_{k} \vert ∣gk−pkl∣−∣gk−pkh∣度量来衡量哪个检测(粗略或精细)更接近于ground truth。其中 g k ∈ { 0 , 1 } g_{k}\in \lbrace 0,1\rbrace gk∈{0,1}。当高分辨率的而检测结果 p k h p^h_{k} pkh比低分辨率的检测结果 p k l p^l_{k} pkl更接近ground truth时。该函数表明此proposal值得放大。否则,检测下采样图像可能会产生更高的准确度,因此我们应该避免放大此proposal。我们使用Correlation Regression相关回归(CR)层来估计proposal k的放大准确度增益:

其中 Φ \Phi Φ代表回归函数,W表示参数,该层的输出是估计的准确度增益。CR层包含两个完全连接的层,其中第一层具有1,024个单元,第二层仅具有一个输出单元。根据每个proposal的学习精度增益,可以生成AG图。我们假设proposal边界框内的每个像素对其准确度增益具有相同的贡献。因此,AG图生成为:
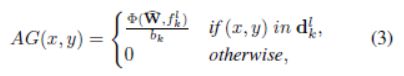
其中(x,y)in d k l d^l_{k} dkl表示点(x,y)在 d k l d^l_{k} dkl边界框中。 b k b_{k} bk表示 d k l d^l_{k} dkl中像素点的个数。 W ^ \widehat{W} W 表示CR层的参数。AG图用作状态表示,它自然包含粗检测质量的信息。放大并对区域执行检测后,放大区域内的所有值都将设置为0,以防止将来放大同一区域。
3.3. Zoom in Q function learning network
R-net提供图像的哪个区域可能最具信息量,用来指导下一步的检测。由于R-net嵌入在顺序过程中,我们使用强化学习来训练第二个网络Q-net,以学习长期放大奖励功能。在每个步骤中,系统通过考虑即时(等式1)和未来奖励来采取行动。我们在Q学习框架中阐述我们的问题,该框架通过学习Q函数来近似于行为的长期奖励函数。我们在Q学习框架中阐述我们的问题,该框架通过学习Q函数来近似于action的长期奖励函数。基于Bellman方程,Q优化方程程 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)服从一个重要的定义。在给定当前状态的情况下,采取action的最佳奖励等于其直接奖励与此行动触发的下一个状态的折扣最优奖励的组合(4)。
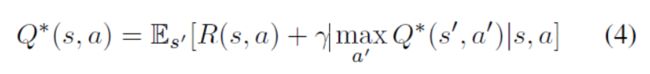
其中s是state,a 是 action。根据【21】我们通过最小化第i次迭代的损失函数来学习候选动作的Q函数。

其 θ i \theta_{i} θi表示Q网络的参数。 θ i − \theta^-_{i} θi−表示在第i次迭代中,计算未来reward所需的参数。
等式5意味着如果为action - state 对提供直接奖励R(s; a),则可以迭代地学习最佳long-term。由于R(s,a)是一个cost-aware reward,所以Q-net可以在action集中直接学出cost-aware reward函数。
在实践中, θ i − = θ i − C \theta^-_{i}=\theta_{i-C} θi−=θi−C,其中C是恒定的参数 λ \lambda λ是未来奖励折扣因子。我们根据经验选择C=10和 λ = 0.5 \lambda=0.5 λ=0.5。我们同样使用了 ϵ \epsilon ϵ-greedy策略来训练来平衡exploration and exploitation。 ϵ \epsilon ϵ的设置同【5】一样。
Q-net的结构在图2中所示。输入是当前状态表示(当前AG图具有与输入图像相同的宽度和高度),如果输入图像中该位置的像素包括在缩放区域中,则AG图中的每个像素衡量预测的精度增益。输出是一组map,并且地图的每个值衡量在该状态下采取相应action(在具有指定大小的位置处选择缩放区域)的长期奖励。为了允许Q-net选择具有不同尺寸的放大区域,我们使用多个管道,每个管道输出对应于特定尺寸的放大区域的map。这些管道共享从状态表示中提取的相同特征。在训练阶段,来自所有map的action被连接起来以产生统一的action集,并通过最小化损失函数(5)来端对端地训练,以便所有action价值相互竞争.
放大选定区域后,我们在该区域上获得粗略和精细检测。我们只是在每个放大区域中用精细的检测替换粗略检测。
**Window selection refinement:**Q-net的输出可以直接用作放大窗口。但是,由于稀疏采样候选缩放窗口,因此可以稍微调整窗口以增加预期的奖励。Refine模块将Q-net输出作为粗略选择,并将窗口局部移动到更好的位置,由精度增益图得到:
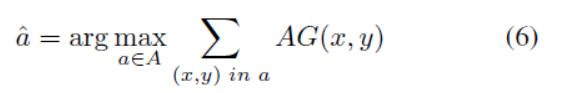
a ^ \widehat{a} a 选择微调的窗口,A=( x q ± u x x_{q}\pm u_{x} xq±ux, y q ± u y y_{q}\pm u_{y} yq±uy,w,h)对应于由参数 μ \mu μ控制的局部细化区域.其中( x q , y q , w , h x_{q},y_{q},w,h xq,yq,w,h)代表Q—net输出的窗口。我们在图3中展示了细化的定性示例。

图3:使用和不使用区域细化的定性比较。红色框表示缩放区域,步骤编号表示选择缩放窗口的顺序。在细化之前,由于采样网格,窗口可能会将人减少一半,从而导致检测性能不佳。细化在本地调整窗口的位置,并产生更好的结果。
4. Experiments
我们在加州理工学院行人检测数据集(CPD)[8]和从YFCC100M [16]收集的Web行人数据集(WP)上进行实验。
**Caltech Pedestrian Detection (CPD):**这个数据集包含25万个标签框,其中包含35万个边框,注释了大约23000个独特的行人。根据不同的注释类型有不同的设置,即总体而言,近尺度,中等尺度,无遮挡,部分遮挡和合理[8]。在测试集中,我们使用Reasonable设置(行人至少50像素高,没有或部分遮挡)。我们从训练集中稀疏地采样图像(每30帧)。训练集中4,321个图像,测试集中有4,088个图像。在训练和测试期间,我们将原始图像的大小调整为最短的600像素。我们所有的模型组件都在此培训集上进行了培训。
**Web Pedestrian (WP) dataset:**CPD数据集中的图像分辨率很低(640*480)。为了更好地展示我们的方法,我们从YFCC100M [16]数据集中收集了100个具有更高分辨率的测试图像。通过搜索关键词“Pedestrian”,“Campus”和“Plaza”来收集图像。图4中示出了一个例子。行人具有不同的尺寸并且在图像中密集地分布。对于此数据集,我们注释所有行人至少16像素宽度和小于50%的遮挡。原始图像在最长侧调整为2,000像素,以适合我们的GPU内存。
4.1. Baseline methods
我们将与以下baseline算法进行比较:
Fine-detection-all: 这个baseline 将精细检测器应用于原始图像(高)分辨率。该方法导致高检测精度和高计算成本。所有其他方法都旨在以较少的计算来维持该检测精度。
Coarse-detection-all: 这个baseline 将粗检测器应用于下采样图像而不进行缩放。
GS+Rnet: 给定R-net生成的初始状态表示,我们使用贪婪搜索策略(GS)每次基于当前状态密集搜索最佳窗口,而不考虑长期奖励。
ER+Qnet: 检测器输出的熵(对象与无对象)是另一种测量粗略检测质量的方法。[2]使用熵来衡量分类任务的区域质量。较高的熵意味着较低的粗略检测质量。因此,如果我们忽略精细和粗略检测之间的相关性,则区域的精度增益也可以计算为

其中 p i l p^l_{i} pil是粗略监测的得分,为了公平比较,我们修复了管道的所有参数,除了用其熵替换proposal的R-net输出。
SSD and YOLOv2: 我们还将我们的方法与SSD [20]和YOLOv2 [24]进行了比较,以表明在我们的场景中将最先进的高效探测器应用于整个图像是不够的。
4.2. Variants of our framework
我们使用Qnet-CNN来表示使用完全卷积网络开发的Q-net(见图2)。为了分析不同组件对性能增益的贡献,我们评估了我们框架的三种变体: Q ∗ n e t Q^*net Q∗net ,Qnet-FC和Rnet 。
Q ∗ Q^* Q∗net : 这种方法使用Q-net进行细化以在局部调整由Q-net选择的zoom-in window。
**Qnet-FC:**QNET-FC。 [7]之后,我们为Q-net开发了两个完全连接(FC)层的变体。对于Qnet-FC,状态表示被调整为长度为1,200的向量作为输入。第一层有128个单元,第二层有34个单元(9 + 25)。每个输出单位表示图像上的采样窗口。我们在CPD数据集上统一采样25个尺寸为320×240的窗口和9个尺寸为214×160的窗口。由于无法更改Qnet-FC的输出数量,因此将Qnet-FC应用于WP数据集时,窗口大小会成比例地增加。
Rne t ∗ t^* t∗: 这是使用reward函数学习的R-net,其没有明确编码成本(方程式1中的λ= 0)。
4.3. Evaluation metric
与Finedetection-all策略进行比较时,我们使用三个指标:AP百分比(Aperc),处理的像素数百分比(Pperc)和平均检测时间百分(Tperc)。 与精细检测全部策略策略相比,Aperc量化了我们获得的mAP百分比。Pperc和Tperc将计算成本表示为精细检测全部基线策略的百分比。
4.4. Implementation details
我们将原始图像下采样两倍,以形成我们所有实验的下采样图像,并仅处理原始分辨率的放大区域。对于Q-net,我们在空间上对具有两种不同窗口(320 240 and 214 * 160)大小的放大候选区域进行采样。对于HW的窗口大小,我们使用水平步幅 S x S_{x} Sx = W/2,垂直步幅 S y S_{y} Sy = H/2像素统一采样窗口;当AG图的所有值的总和小于0:01时,Q-net停止采取行动。
我们使用[8]中的训练集在精细和粗略分辨率上训练两个更Faster R-CNN探测器,然后将它们用作黑盒的粗略和精细探测器。YOLOv2和SSD使用与作者发布的官方代码中的默认参数设置相同的训练集进行训练。所有实验均使用K-80 GPU进行。
4.5. Qualitative results
定性比较显示了细化对所选放大区域的影响,如图3所示。我们观察到,细化显着减少了行人仅在所选窗口中部分出现的情况。由于Q-net的稀疏窗口采样,任何窗口候选可能不会覆盖最佳区域,尤其是当窗口大小与图像大小相比相对较小时。
我们展示了我们的方法(Q-net * -CNN + Rnet)和图4中的贪婪策略(GS + Rnet)之间的比较。GS倾向于在图像的相同部分上选择重复缩放。虽然Q-net可能在短期内选择次优窗口,但从长远来看,它会带来更好的整体性能。如图4的第一个例子所示,这有助于Q-net以较少的缩放终止。
图5显示了R-net和ER的定性比较。第一行中的示例是不需要放大的检测,因为粗略检测足够好。R-net对这些区域的准确度增益要低得多。另一方面,R-net在第二行输出更高的增益,其中包括需要以更高分辨率进行分析的区域。第三行包含在更高分辨率下得到更差结果的示例。正如我们之前提到的,熵不能确定放大是否有帮助,而R-net会为这些情况产生负增益并避免在这些区域放大。

图4:使用Q-net和使用贪婪策略(GS)之间的定性比较,该策略选择每个步骤中具有最高预测准确度增益的区域。红色边界框表示放大窗口,步骤编号表示窗口选择的顺序。Q-net选择在近期内看起来次优的区域,但在长期内导致更好的缩放序列,这导致更少的步骤,如第一行所示。

图5:加州理工学院行人测试集中R-net和ER的定性比较。第一行数字表示红色方框是行人的概率。C表示粗略检测,F表示精细检测。红色字体表示R-net的准确度增益,蓝色表示ER。正值和负值归一化为[0,1]和[-1,0]。与ER相比,对于粗略检测足够好/优于精细检测的区域,R-net给出较低的正分数(第1行)/负分数(第3行)它为区域(第2行)产生更高的分数,其中精细检测比粗略检测要好得多。
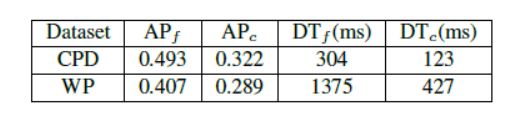
表1:粗略检测全部(带下标c)v.s. CPD和WP数据集上的Finedetection-all(带有下标f)。DT表示每个图像的平均检测时间。
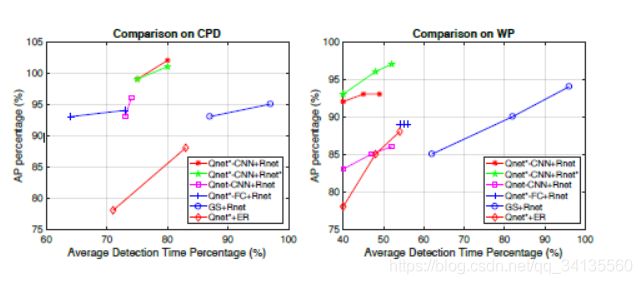
放大两个/三个区域后,CPD / WP数据集的检测时间和精度比较。
4.6. Quantitative evaluation
表1显示了CPD和WP数据集上的Fine-detection-all和Coarsedetection-all策略的每个图像的平均精度(AP)和平均检测时间。coarse baseline分别在CPD和WP上仅保持约65%和71%的AP,这表明天真的下采样方法显着降低了检测准确度。
CPD和WP数据集的比较结果如表2所示.Q-net * -CNN + R-net将处理后的像素减少50%以上,具有与Fine-detection-all策略相当(甚至更好)的检测精度。在CPD数据集上将Coarse-detection-all的检测精度提高了约35%。在WP数据集上,最佳变体(Q-net * -CNN + R-net *))将处理后的像素减少了60%以上,同时保持了Fine-detection-all的97%检测精度。表2显示我们框架的变体在大多数情况下优于GS + Rnet和Qnet + ER,这表明Qnet和Rnet优于GS和ER。Q-net优于GS,因为贪婪策略分别考虑单个的action,而Q-net利用RL框架来最大化长期奖励。
在相同的成本预算下,Qnet * -CNN + Rnet总是比Qnet * -CNN + ER产生更好的检测精度,这表明使用R-net学习准确度增益优于使用手工制作的熵。这可能是由于两个原因:1)熵仅测量粗探测器的置信度,而我们的R-net基于置信度和外观估计与高分辨率探测器的相关性;2)根据方程2中的回归目标函数,我们的R-net还测量放大过程是否会提高检测精度。这避免了在精细检测无法改进(或甚至可能降级)的区域上浪费资源。
我们从图6中观察到,我们的方法(Qnet * -CNN + Rnet和Qnet * -CNN + Rnet *)将检测时间缩短了50%,同时保持了WP数据集的高精度。在CPD数据集上,它们可以将检测时间缩短25%而不会显着降低精度。由于CPD图像相对较小,因此检测时间不能像WP数据集那样减少; 然而,值得注意的是,即使在这种情况下,我们的方法也有帮助。
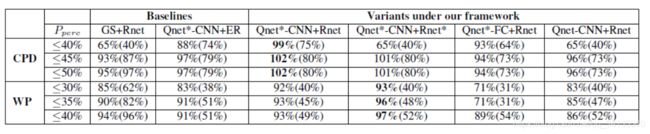
表2:在固定的处理像素百分比范围(Pperc)下,CPD和WP数据集上Aperc的检测精度比较。粗体字表示最佳结果。数字显示为Aperc(Tperc) - Tperc包含在括号中,用于参考运行时间。Note that 25% Pperc overhead is incurred simply by analyzing the downsampled image (this overhead is included in the table) and percentages are relative to Fine-detection-all baseline (an Aperc of 80% means that an approach reached 80% of the AP reached by the baseline).
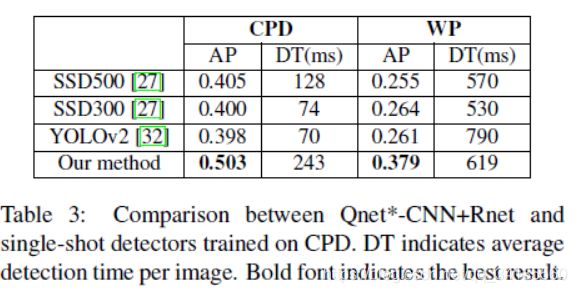
表3显示了YOLO / SSD与我们的方法之间的准确度/成本比较。 实验表明了以下结论:1)尽管速度很快,但这些单次探测器在物体上发生的物体在很大范围内都能达到更低的AP; 2)随着图像尺寸的增加,YOLO / SSD处理时间显着增加,同时,我们的方法在相当的检测时间内实现了更高的精度; 3)由于重度卷积操作,SSD在大图像上消耗比其他检测器更多的GPU内存。 我们必须将WP的图像大小调整为800*800以适应GPU内存。请注意,可以通过修剪网络或使用更多数据进行训练来改善YOLO / SSD的结果,但这不在本文的讨论范围内。