【目标跟踪】--deepsort
DeepSORT是SORT多目标跟踪算法的改进版本,设计了一种新的关联方式,提高了对长时间遮挡的对象追踪的准确率,减少了Id频繁切换的现象。
一、多目标追踪的主要步骤
获取原始视频帧
利用目标检测器对视频帧中的目标进行检测
将检测到的目标的框中的特征提取出来,该特征包括表观特征(方便特征对比避免ID switch)和运动特征(运动特征方便卡尔曼滤波对其进行预测)
计算前后两帧目标之前的匹配程度(利用匈牙利算法和级联匹配),为每个追踪到的目标分配ID。
二、sort流程
具体实现:
轨迹处理和状态估计:
我们的跟踪场景定义在八维状态空间(u, v, γ, h,˙x,˙y,˙γ,˙h)上,其中,(u, v)是检测框中心点坐标、γ是长宽比、h为检测框高度,以及它们在图像坐标中的各自速度。然后使用匀速模型和线性观测模型卡尔曼滤波预测更新,其观测变量为 (u, v, γ, h)。
对于每个轨迹k,从上次首次匹配的时刻ak计算匹配的帧数,卡尔曼预测期间匹配到了就增加计数,如果轨迹与新的预测相关联时,重置为0。同时设置一个生命周期的阈值Amax,超过这个时间还没有匹配,就认为离开该追踪对象离开了场景,从轨迹中删除(通俗来讲,就是超过Amax的长时间没匹配的对象认为它已经出了追踪区域)。
由于每个新检测的对象都可能成为一条新的轨迹,但如果直接把他们归为一条轨迹,那么错检和误检的情况就会频繁出现。DeepSORT是这么做的:新的检测结果首先被标为'tentative',然后观察接下来的若干帧(一般为3帧),如果接下来的连续3帧都成功匹配上,标记为'confirmed',也就是确认是一条新的轨迹。否则标记为'deleted',不再认为其可以构成轨迹。
匹配的度量方式
马氏距离
SORT算法是使用匈牙利算法对卡尔曼预测的状态和新检测结果匹配,DeepSORT把外观和运动的信息也整合到了匹配策略中。
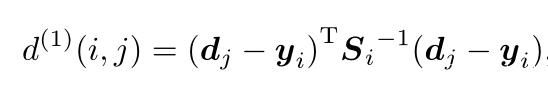
作者提出了马氏距离度量,其中用dj表示第j个检测框信息 (u, v,γ, h),Si是轨迹卡尔曼滤波器预测得到的在当前时刻观测空间的协方差矩阵。yi 是轨迹在当前时刻的预测观测量。上述整个式子表示,第j个预测结果与第i条轨迹的匹配度。
使用马氏距离的好处是,这种匹配方式考虑了状态估计的不确定度。可以利用卡方分布95%的分位作为阈值,用来排除不可能的关联。如果第i个轨迹和第j个预测之间的关联是可接受的,则其计算结果为1,如下所示。
![]()
使用余弦距离衡量差异
对于每个检测框dj,计算外观描述符rj,其中||rj||=1, 此外,对于每个轨迹k,利用一个gallary(类似滑动窗口)存放最近的100个外观描述符。最后,度量了在中第i个轨迹和第j个探测之间的最小余弦距离,如下所示:
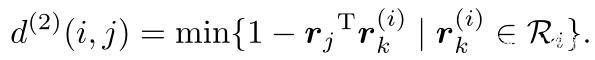
同样,作者也为该度量设置了一个限制,即如果第i个轨迹和第j个预测之间的关联是可接受的,则其计算结果为1。这里的阈值不同于马氏距离,需要在单独的训练数据集上找到合适的阈值。
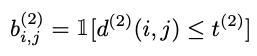
总的匹配指标
上述来给你个匹配指标是互为补充的。具体来说,马氏距离提供了目标的可能位置信息,对短期预测有用;余弦距离更多考虑的是预测信息和轨迹信息的外观特征,当跟踪对象位移较少时,对恢复长期遮挡后的id特别有用,因此作者的做法是把二者加权相加:
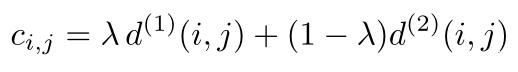
其中,阈值设置为:
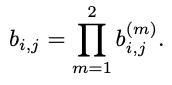
通过控制超参λ可以控制二者的占比。作者通过实验发现,当λ=0时,可以有效应对相机拍摄时位移的情况。才该项设置下,相当于只使用了外观特征信息。
匹配级联
不同于传统的思路,作者没有把整个问题看作全局优化的问题,而是使用级联的策略优化一系列子问题。考虑到当一个物体被遮挡较长一段时间,卡尔曼滤波预测增加了与物体位置相关的不确定性,会导致连续预测的概率弥散,换句话说,当有连续的预测不更新时,分布的方差会变大,也就意味着离均值欧氏距离远的点可能和之前分布中离得较近的点获得同样的马氏距离值,这么做显然是有问题的。所以作者引入了级联匹配,优先考虑更常见的对象

如上图,输入轨迹T,检测指标D,和生命周期Amax。我们计算关联代价矩阵C和其阈值B。然后在生命周期内做n次迭代,解决轨迹的分配问题: 选择了在最近n帧中没有与检测相关的轨迹Tn,然后求解了Tn和未匹配的U轨迹之间的线性分配,然后我们更新匹配和未匹配的集合,循环以上步骤直至结束。需要注意的是,这种策略优先考虑生命周期较小的轨迹,即最近出现的轨迹。在最后阶段,作者使用之前SORT算法中的IOU关联去匹配n=1的unconfirmed和unmatched的轨迹。这可以增加因为外观突变或者部分遮挡情况下的鲁棒性。
深度外观描述符
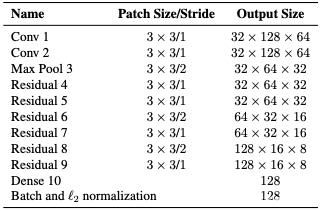
作者使用了CNN网络在一个大规模的数据集上进行一个offline的训练,以用来提取目标的特征信息。作者采用了残差网络的结构,有两个卷积层,六个残差块,经全连接层得到维度128的特征。最后,使用l2标准化把特征投影到单位超球体,这样就可以兼容余弦度量。
sort工作流程如下图所示:
Detections是通过目标检测到的框框。Tracks是轨迹信息。
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
三、Deepsort算法流程
由于sort算法还是比较粗糙的追踪算法,当物体发生遮挡的时候,特别容易丢失自己的ID。而Deepsort算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
Deepsort算法的工作流程如下图所示:
整个算法的工作流程如下:
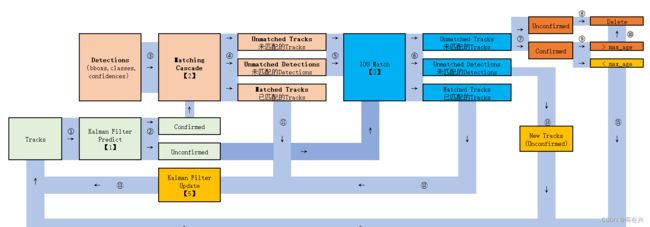
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。