不看后悔!新手小白必看的保姆级教程!一篇文章学会数据仓库!
一、什么是数据仓库?
1.1 数据仓库概述:
数据仓库是决策支持系统(dss)和联机分析应用数据源的结构化数据环境。数据仓库致力于研究和解决从数据库中获取信息的问题。
1.2 数据仓库特征:
面向主题、集成性、稳定性和时变性,用于支持管理决策。
1.3 数据仓库意义:
对企业的所有数据进行汇总,致力于为企业各个部门提供统一的、规范的数据出口。
1.4 数据仓库目标:
实现集成、稳定、反应历史变化有组织有结构的存储数据的集合。
1.5 数据库与数据仓库的区别:
数据库(Database):则是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库。数据库是长期储存在计算机内、有组织的、可共享的数据集合。
1.6 OLTP和OLAP:
操作型处理:又名联机事务处理OLTP(On-Line Transaction Processing),也可以称面向交易的处理系统,是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数量等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理:又名联机分析处理OLAP(On-Line Analytical Processing),一般针对某些主题的历史数据进行分析,支持管理决策。
二者的异同如表1所示:
表 1:OLTP与OLAP的异同
| 操作型处理 |
分析型处理 |
| 细节的 |
综合的或提炼的 |
| 实体-关系(ER)模型 |
星型或雪花模型 |
| 存取瞬间数据 |
存储历史数据,不包含最近的数据 |
| 可更新的 |
只读,只追加 |
| 一次操作一个单元 |
一次操作一个集合 |
| 性能要求高,响应时间短 |
性能要求宽松 |
| 面向事务 |
面向分析 |
| 一次操作数据量小 |
一次操作数据量大 |
| 支持日常操作 |
支持决策需求 |
| 数据量小 |
数据量大 |
| 客户订单、库存水平和银行账户等 |
客户收益分析、市场细分等 |
二、星型模式、雪花模式和星座模式
2.1 星型模式
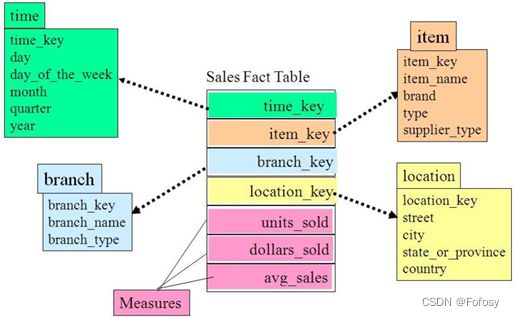
星型模式是维度模型中最简单的形式,也是数据仓库以及数据集市开发中使用最广泛的形式。星型模式由事实表和维度表组成,一个星型模式中可以有一个或多个事实表,每个
事实表引用任意数量的维度表。星型模式的物理模型像一颗星星的形状,中心是一个事实表, 围绕在事实表周围的维度表表示星星的放射状分支,这就是星型模式这个名字的由来。
星型模式将业务流程分为事实和维度。事实包含业务的度量,是定量的数据,如销售价格、销售数量、距离、速度、重量等是事实。维度是对事实数据属性的描述,如日期、产品、客户、地理位置等是维度。一个含有很多维度表的星型模式有时被称为蜈蚣模式,显然这个名字也是因其形状而得来的。蜈蚣模式的维度往往只有很少的几个属性,这样可以简化对维度表的维护,但查询数据时会有更多的表连接,严重时会使模型难于使用,因此在设计中应该尽量避免蜈蚣模式。
2.2 雪花模式
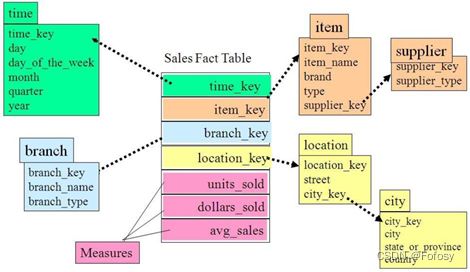
雪花模式是一种多维模型中表的逻辑布局,其实体关系图有类似于雪花的形状,因此得名。
与星型模式相同,雪花模式也是由事实表和维度表所组成。所谓的“雪花化”就是将行星模型中的维度表进行规范化处理。当所有的维度表完成规范化后,就形成了以事实表为
中心的雪花型结构,即雪花模式。将维度表进行规范化的具体做法是,把低基数的属性从维度表中移除并形成单独的表。基数指的是一个字段中不同值的个数,如主键列具有唯一值, 所以有最高的基数,而像性别这样的列基数就很低。
在雪花模式中,一个维度被规范化成多个关联的表,而在星型模式中,每个维度由一个单一的维度表所表示。一个规范化的维度对应一组具有层次关系的维度表,而事实表作为雪花模式里的字表,存在具有层次关系的多个父表
2.3 星座模式

数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可
以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
三、数据仓库分层理论
3.1 CIF层次结构
CIF 层次架构(信息工厂)通过分层将不同的建模方案引入到不同的层次中,CIF 将数据仓库分为四层,如图所示:
| 维度建模 | DM |
| 维度建模 | DWS |
| 维度建模ER | DWD |
| ER | ODS |
ODS(Operational Data Store):操作数据存储层,往往是业务数据库表格的一对一映射,将业务数据库中的表格在 ODS 重新建立,数据完全一致;
DWD(Data Warehouse Detail):数据明细层,在 DWD 进行数据的清洗、脱敏、统一化等操作,DWD 层的数据是干净并且具有良好一致性的数据;mapreduce
DWS(Data Warehouse Service):服务数据层(公共汇总层),在 DWS 层进行轻度汇总,粒度比明细数据稍粗,为 DM 层中的不同主题提供公用的汇总数据,目的是避免重复计算。往往在 DWS 层建立宽表。
DM(Data Market):数据集市层,DM 层针对不同的主题进行统计报表的生成;在 DM 完成报表或者指标的统计,DM 层已经不包含明细数据,是粗粒度的汇总数据,因此 DM 层会被当成 BI 或者 OLAP 的底层模型。
四、数据仓库维度建模
4.1 维度表设计
4.1.1 代理键
维度表中必须有一个能够唯一标识一行记录的列(最好是原子性的列,不要是组合键), 通过该列维护维度表与事实表之间的关系,一般在维度表中业务主键符合条件可以当作维度主键。
但是,数据仓库是整个公司数据的整合,这会涉及到多个数据源有相同维度,那么就会出现以下两个问题:
- 当整合多个数据源的维度时,不同数据源的业务主键重复怎么办?
- 涉及维度拉链表时,同一主体多条记录,业务键重复怎么办?
表2:财务部门维度表
| ID | name | note |
| 1 | Chen | Fine |
| 2 | Zhang | Fine |
表3:研发部门维度表
| ID | name | note |
| 1 | Li | R&D |
| 2 | Zhou | R&D |
如上图所示,业务键重复,我们可以引入代理键,如下表所示:
表4:引入代理键
| GID | ID | name | note |
| 1 | 1 | Chen | Fine |
| 2 | 2 | Zhang | Fine |
| 3 | 1 | Li | Risk |
| 4 | 2 | Zhou | Risk |
把多个系统的数据复合在一起,同时再维护一个代理键,而且代理键在这个维度表里是唯一标识一条记录的,类似于业务系统的业务键。
代理键是由数据仓库处理过程中产生的、与业务本身无关的、唯一标识维度表中一条记录并充当维度表主键的列,也是描述维度表与事实表关系的纽带。
在设计有代理键的维度表中,事实表中的关联键是代理键而不是原有的业务主键,即
业务关系是靠代理键维护,这样有效避免源系统变化对数仓数据对影响。
4.1.2 稳定维度
部分维度表的维度是在维度表产生后,属性是稳定的、无变化的。比如时间维度、区 域维度等,针对这种维度,设计维度表的时候,仅需要完整的数据,不需要天的快照数据, 因为当前数据状态就是历史数据状态。
4.1.3 缓慢渐变维
维度数据会随着时间发生变化,变化速度比较缓慢,这种维度数据通常称作缓慢渐变维,例如电商平台的用户维度表,用户可能会随着时间推移改变收件地址,因此用户维度表
中的收件地址就是一个缓慢变化维。由于数据仓库需要追溯历史变化,尤其是一些重要的数据,所以历史状态也需要采取一定的措施进行保存,保存历史状态的方式有以下三种:
- 每天保存当前数据的全量快照数据(每天一个新增分区),该方案适合数据量较小
(根据公司具体的配置而定)的维度,使用简单的方式保存历史状态。
- 在维表中添加关键属性值的历史字段,仅保留上一个的状态值。可能同时有多个属性都非常重要,而且只能追溯上一个数据,不是所有的历史数据,这种范式应用场景较少。
- 拉链表:当维度数据发生变化时,将旧数据置为失效,将更改后的数据当作新的记录插入到维度表中,并开始生效,这样能够记录数据在某种粒度上的变化历史。
4.1.4 拉链表详解
将数据的变更当做流水记录下来 ,旧的设为失效,新的设为生效,如果粒度为天,那么就可以得到一天的最终状态作为最终状态。
表5:拉链表
| ID | name | addr | start_date | end_date |
| 1 | Zhou | dept2 | 2018-05-01 | 2018-06-09 |
| 1 | Zhou | dept3 | 2018-06-10 | 2018-06-14 |
| 1 | Zhou | dept1 | 2018-06-15 | 2018-12-31 |
表 5 中每条记录都有一个 End_date,当有新的数据产生时,在旧数据的 End_date 字段中插入日期,然后新插入一条数据,新数据的 End_date 字段中是一个永久有效的值,如果再发生更新,上一次更新数据的 End_date 字段设置为当前日期,然后再次插入新数据, 新数据的 End_date 字段中设置一个永久有效的值。
如果想知道某个员工在 5 月 22 号时在哪个部门,那么可以通过如下 SQL:
Select * from user where start_date<= 2018-05-22 and end_date>= 2018-05-22
根据拉链表的结构,如果对维度表做拉链,那么一个维度实体必然存在多条记录,也就是一个主键 ID 对应多条数据,此时维度表的原子性主键也就没有意义了。
维度表做拉链后会失去原子性主键,那么拉链维度表如何和事实表进行关联呢? 此时就要用到代理键,也就是在事实表和维度表中同时添加代理键,如下图所示:
表6:用户详情拉链表
| UID | ID | name | addr | start_date | end_date |
| 1 | 1 | Zhou | dept2 | 2018-05-01 | 2018-06-09 |
| 2 | 1 | Zhou | dept3 | 2018-06-10 | 2018-06-14 |
| 3 | 1 | Zhou | dept1 | 2018-06-15 | 2018-12-31 |
表7:订单表
| OID | ID->UID | Tim_ID | amount |
| 1 | 1 | 5 | 998 |
| 2 | 1 | 9 | 1000 |
| 3 | 2 | 10 | 1499 |
完成代理键的添加后,在之后的统计中,按照代理键进行聚合即可。
事实表来源于业务事务表,代理键和业务本身没有关系,那么怎么在新增数据时在事实表中装载代理键?
当事实表中有新增数据时,新增数据中记录了维度表中原有的原子性主键,可以根据原有的主键匹配维度表中的数据,然后根据新增数据的时间范围找到匹配的代理键,然后在事实表的新增数据中加入代理键。
代理键是维度建模中极力推荐的方式,它的应用能有效的隔离源端变化带来的数仓结构不稳定问题,同时也能够提高数据检索性能。
但是代理键维护代价非常高,尤其是数据装载过程中,对事实表带来了较大的影响, 在基于 hive 的数据仓库建设影响更加严重,比如代理键的生成、事实表中关联键的装载、不支持非等值关联等问题,带来 ETL 过程更加复杂。
因此,在大数据体系下,谨慎使用代理键,同时对于缓慢渐变维场景,可以考虑用空间换取时间,每天保留维表全量快照,但这样会带来存储成本,根据实际情况衡量。
4.2 事实表设计
4.2.1事实表设计
1.增量存储
当事实表数据无状态变化时,采用增量存储,即每周期仅处理增量部分的数据,纯增量采集。
2.全量快照
状态有变化,但每天保存当前的快照数据,对于数据量在可控范围内的情况可以采用。保存策略:
(1)如果存储空间和成本可接受,完整存储,确保能够追溯到历史每天数据状态;
(2)存储空间有限,考虑移动历史快照数据到冷盘,需要使用的时候可恢复;
(3)数据历史状态数据无太大价值,可以考虑部分删除,比如近保留每月最后一天的快照数据
3.拉链
数据量大,但缓慢变化,需要跟踪历史状态,和缓慢渐变维类似。
如果变化非常快,拉链表的数据量会大于快照表数倍,一天变一次,那么一周就保存了
7 份数据,可以考虑把已经失效的数据转移到其他的存储介质或者冷盘上,或者定期(一个月)进行删除。
4.2.2明细事实表
事实表有粒度大小之分,基于数据仓库层次架构,明细事实表一般存在于 DWD 层,该层事实表设计不进行聚合、汇总动作,仅做数据规范化、数据降维动作,同时数据保持业务事务粒度,确保数据信息无丢失。
DWD 层与业务强相关,DWD 层的表就是业务表经过一系列规范化、降维之后的表。
1. 数据降维
为了提高模型易用性,将常规维度表中的常用的属性数据冗余到相应的事实表中,从而在使用的时候避免维表关联的方式,既为数据降维。
2. 独立维度的选择
并不是你业务中遇到的每一个实体都要成为一个独立的维度,具体哪些维度可以合并, 要根据实际的业务场景来确定,比如对于出行行业,司机一定是一个独立维度,而汽车这个实体就没有必要称为独立的维度(除非要分析订单的取消与汽车品牌的关系),因此可以汽车信息和司机信息进行合并。
3. 事实表不一定有事实
一般将事实表中包含两部分信息:维度、度量,度量即为事实,但有些特殊情况下, 事实表中无度量信息,只是记录一个实际业务动作。
4. 明细事实表设计方案
设计事实表的主要依据是业务过程,之前说过,每一个业务动作事件,都可以作为一个事实,那么在一个订单处理过程中,会有多个动作,这个过程中的事实表怎么设计呢?
方案一:单事件事实表
对于每一个业务动作事件,设计一个事实表,仅记录该事件的事实以及状态。(一个业务流程多个单事件事实表)
方案二:流程事实表
对于一个业务流程主体,设计一个事实表,跟踪整个流程的事实以及状态流转。
单事件事实表和流程事实表的特点:
单事件事实表:
- 更方便跟踪业务流程细节数据,针对特殊的业务分析场景比较方便和灵活,数据处理上也更加灵活;
- 不方便的地方就是数仓中需要管理太多的事实表,同时跟踪业务流转不够直观;
流程事实表:
- 能够更直观的跟踪业务流转和当前状态,流程事实集中,方便大部分的通用分析应用场景,由于和业务侧的数据模型设计思路一致,也是目前最常用的事实表设计;但是细节数据跟踪不到位,特殊场景的分析不够灵活;
两种表的设计区别在于对业务流程的拆分思路不同,具体选择事实表的构建思路,需要根据实际的业务确定,一般建议两者结合
4.2.3聚合事实表
相对于明细事实表,聚合事实表通常是在明细事实表的基础上,按照一定的粒度粗细进行的汇总、聚合操作,它的粒度较明细数据粒度粗,同时伴随着细节信息的丢失。
在数仓层次结构中,聚合事实表通常位于 DWS 层,一般作为通用汇总数据存在,也可以是更高粒度的指标数据。
聚合事实表的数据来源可以是两种明细事实表中的任意一种。
- 日粒度
- 周期性累积(周,月,年)
- 历史累积(累计订单量、累计金额)
4.2.3.1 可累加事实与不可加事实
1.可累加事实
可累加事实是在一定的粒度范围内,可累加的事实度量,比如:订单金额、订单数。
2.不可累加事实
不可累加事实是在更高粒度上不可累加的事实,比如通过率、转化率等。
通常情况下,比率这种不可累积的事实,建议拆分存储,比如通过率拆分为通过数、申请数,由细粒度数据去重计算而得到的事实,正常存储,但是更粗粒度累积是不可直接使用。
4.2.3.2 聚合事实表分类
1. 公共维度层/通用汇总层
封装底层计算逻辑,做通用汇总,避免上层直接访问下层明细数据。
应对大部分可预期的、常规的数据需求,通常针对模式相对稳定的分析、BI 指标计算、特征提取等场景,封装部分业务处理、计算逻辑,尽量避免用户直接使用底层明细数据,该层用到的数据范围比较广泛。
通用汇总层需要满足 80%~90%的场景,对数据进行轻度汇总,避面直接访问明细层, 假设明细层有 1 亿条数据,这一层可能只有 1 千万条。
2. 日粒度
主要应对模式稳定的分析、BI 日报、特征提取场景,同时日粒度也为后续累积计算提供粗粒度的底层,数据范围一般为上一日的数据。
对可累加指标进行粗粒度的统计,周、月等粒度的统计可以在日粒度基础上计算,假设明细层 1 亿条数据,这一层可能只有 1 百万条。
3. 周期性累积
主要应对明确的周期性分析、BI 周期性报表,数据范围一般在某周期(周、月等)内的。底层数据可以来自于公共维度层-通用汇总,也可以来自于日粒度。
4. 历史累积
顾名思义,历史以来某一特定数据的累积,通常在用户画像、经营分析、特征提取方面场景较多,设计数据范围比较广泛,通常是计算耗时较长的一部分,比如某门店累积营业额、某用户累积利润贡献、用户首次下单时间(非可度量、描述性)。