【自然语言处理】TextRank算法
TextRank算法
TextRank算法基于PageRank,用于为文本生成关键字和摘要。其论文是:
Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
先从PageRank讲起
首先介绍原理与概念
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法(其原理在本文在下面), 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:

其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
举个例子:
上图表示了三张网页之间的链接关系,直觉上网页A最重要。可以得到下面的表:
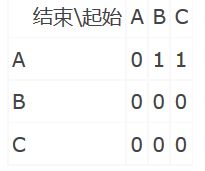
横栏代表其实的节点,纵栏代表结束的节点。若两个节点间有链接关系,对应的值为1。根据公式,需要将每一竖栏归一化(每个元素/元素之和),归一化的结果是:

上面的结果构成矩阵M。我们用matlab迭代100次看看最后每个网页的重要性:
M = [0 1 1
0 0 0
0 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end运行结果(省略部分
97---
0.4050
0.1500
0.1500
98---
0.4050
0.1500
0.1500
99---
0.4050
0.1500
0.1500
100---
0.4050
0.1500
0.1500
最终A的PR值为0.4050,B和C的PR值为0.1500
如果把上面的有向边看作无向的(其实就是双向的),那么:
M = [0 1 1
0.5 0 0
0.5 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end运行结果(省略部分):
.....
98
1.4595
0.7703
0.7703
99
1.4595
0.7703
0.7703
100
1.4595
0.7703
0.7703
依然能判断出A、B、C的重要性。
使用TextRank提取关键字
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中是保留后的候选关键词。
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
原理思路整理:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
我取出了百度百科关于“程序员”的定义作为测试用例,很明显,这段定义的关键字应当是“程序员”并且“程序员”的得分应当最高。
首先对这句话分词,这里可以借助各种分词项目,比如HanLP分词,得出分词结果:
[程序员/n, (, 英文/nz, programmer/en, ), 是/v, 从事/v, 程序/n, 开发/v, 、/w, 维护/v, 的/uj, 专业/n, 人员/n, 。/w, 一般/a, 将/d, 程序员/n, 分为/v, 程序/n, 设计/vn, 人员/n, 和/c, 程序/n, 编码/n, 人员/n, ,/w, 但/c, 两者/r, 的/uj, 界限/n, 并/c, 不/d, 非常/d, 清楚/a, ,/w, 特别/d, 是/v, 在/p, 中国/ns, 。/w, 软件/n, 从业/b, 人员/n, 分为/v, 初级/b, 程序员/n, 、/w, 高级/a, 程序员/n, 、/w, 系统/n, 分析员/n, 和/c, 项目/n, 经理/n, 四/m, 大/a, 类/q, 。/w]
然后去掉里面的停用词,这里我去掉了标点符号、常用词、以及“名词、动词、形容词、副词之外的词”。得出实际有用的词语:
[程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理]
之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词:
{开发=[专业, 程序员, 维护, 英文, 程序, 人员],
软件=[程序员, 分为, 界限, 高级, 中国, 特别, 人员],
程序员=[开发, 软件, 分析员, 维护, 系统, 项目, 经理, 分为, 英文, 程序, 专业, 设计, 高级, 人员, 中国],
分析员=[程序员, 系统, 项目, 经理, 高级],
维护=[专业, 开发, 程序员, 分为, 英文, 程序, 人员],
系统=[程序员, 分析员, 项目, 经理, 分为, 高级],
项目=[程序员, 分析员, 系统, 经理, 高级],
经理=[程序员, 分析员, 系统, 项目],
分为=[专业, 软件, 设计, 程序员, 维护, 系统, 高级, 程序, 中国, 特别, 人员],
英文=[专业, 开发, 程序员, 维护, 程序],
程序=[专业, 开发, 设计, 程序员, 编码, 维护, 界限, 分为, 英文, 特别, 人员],
特别=[软件, 编码, 分为, 界限, 程序, 中国, 人员],
专业=[开发, 程序员, 维护, 分为, 英文, 程序, 人员],
设计=[程序员, 编码, 分为, 程序, 人员],
编码=[设计, 界限, 程序, 中国, 特别, 人员],
界限=[软件, 编码, 程序, 中国, 特别, 人员],
高级=[程序员, 软件, 分析员, 系统, 项目, 分为, 人员],
中国=[程序员, 软件, 编码, 分为, 界限, 特别, 人员],
人员=[开发, 程序员, 软件, 维护, 分为, 程序, 特别, 专业, 设计, 编码, 界限, 高级, 中国]}TextRank的打分思想依然是从PageRank的迭代思想衍生过来的,如下公式所示:
等式左边表示一个句子的权重(WS是weight_sum的缩写),右侧的求和表示每个相邻句子对本句子的贡献程度。与提取关键字的时候不同,一般认为全部句子都是相邻的,不再提取窗口。
求和的分母wji表示两个句子的相似程度,分母又是一个weight_sum,而WS(Vj)代表上次迭代j的权重。整个公式是一个迭代的过程。
相似程度的计算
而相似程度wji的计算,推荐使用BM25
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法.pdf
测试用例
文字:
算法可大致分为基本算法、数据结构的算法、数论算法、计算几何的算法、图的算法、动态规划以及数值分析、加密算法、排序算法、检索算法、随机化算法、并行算法、厄米变形模型、随机森林算法。
算法可以宽泛的分为三类,
一,有限的确定性算法,这类算法在有限的一段时间内终止。他们可能要花很长时间来执行指定的任务,但仍将在一定的时间内终止。这类算法得出的结果常取决于输入值。
二,有限的非确定算法,这类算法在有限的时间内终止。然而,对于一个(或一些)给定的数值,算法的结果并不是唯一的或确定的。
三,无限的算法,是那些由于没有定义终止定义条件,或定义的条件无法由输入的数据满足而不终止运行的算法。通常,无限算法的产生是由于未能确定的定义终止条件。
断句
算法可大致分为基本算法、数据结构的算法、数论算法、计算几何的算法、图的算法、动态规划以及数值分析、加密算法、排序算法、检索算法、随机化算法、并行算法、厄米变形模型、随机森林算法
算法可以宽泛的分为三类
一
有限的确定性算法
这类算法在有限的一段时间内终止
他们可能要花很长时间来执行指定的任务
但仍将在一定的时间内终止
这类算法得出的结果常取决于输入值
二
有限的非确定算法
这类算法在有限的时间内终止
然而
对于一个(或一些)给定的数值
算法的结果并不是唯一的或确定的
三
无限的算法
是那些由于没有定义终止定义条件
或定义的条件无法由输入的数据满足而不终止运行的算法
通常
无限算法的产生是由于未能确定的定义终止条件分词并过滤停用词
[算法, 大致, 分, 基本, 算法, 数据, 结构, 算法, 数论, 算法, 计算, 几何, 算法, 图, 算法, 动态, 规划, 数值, 分析, 加密, 算法, 排序, 算法, 检索, 算法, 随机, 化, 算法, 并行, 算法, 厄, 米, 变形, 模型, 随机, 森林, 算法]
[算法, 宽泛, 分为, 三类]
[]
[有限, 确定性, 算法]
[类, 算法, 有限, 一段, 时间, 终止]
[可能, 花, 长, 时间, 执行, 指定, 任务]
[一定, 时间, 终止]
[类, 算法, 得出, 常, 取决, 输入, 值]
[二]
[有限, 非, 确定, 算法]
[类, 算法, 有限, 时间, 终止]
[]
[一个, 定, 数值]
[算法, 唯一, 确定]
[三]
[无限, 算法]
[没有, 定义, 终止, 定义, 条件]
[定义, 条件, 无法, 输入, 数据, 满足, 终止, 运行, 算法]
[通常]
[无限, 算法, 产生, 未, 确定, 定义, 终止, 条件]
迭代投票
for (int _ = 0; _ < max_iter; ++_)
{
double[] m = new double[D];
double max_diff = 0;
for (int i = 0; i < D; ++i)
{
m[i] = 1 - d;
for (int j = 0; j < D; ++j)
{
if (j == i || weight_sum[j] == 0) continue;
m[i] += (d * weight[j][i] / weight_sum[j] * vertex[j]);
}
double diff = Math.abs(m[i] - vertex[i]);
if (diff > max_diff)
{
max_diff = diff;
}
}
vertex = m;
if (max_diff <= min_diff) break;
}排序输出结果
这类算法在有限的时间内终止
这类算法在有限的一段时间内终止
无限算法的产生是由于未能确定的定义终止条件分别对应于原文
算法可大致分为基本算法、数据结构的算法、数论算法、计算几何的算法、图的算法、动态规划以及数值分析、加密算法、排序算法、检索算法、随机化算法、并行算法、厄米变形模型、随机森林算法。
算法可以宽泛的分为三类,
一,有限的确定性算法,这类算法在有限的一段时间内终止。他们可能要花很长时间来执行指定的任务,但仍将在一定的时间内终止。这类算法得出的结果常取决于输入值。
二,有限的非确定算法,这类算法在有限的时间内终止。然而,对于一个(或一些)给定的数值,算法的结果并不是唯一的或确定的。
三,无限的算法,是那些由于没有定义终止定义条件,或定义的条件无法由输入的数据满足而不终止运行的算法。通常,无限算法的产生是由于未能确定的定义终止条件。
TextRank代码
使用textrank源代码可以抽取摘要,也可以抽取关键词。
以snownlp的源代码为例,抽取摘要:
def solve(self): #针对抽关键句
for cnt, doc in enumerate(self.docs):
scores = self.bm25.simall(doc) #在本实现中,使用的不是前面提到的公式,而是使用的BM25算法,之前会有一个预处理(self.bm25 = BM25(docs)),然后求doc跟其他所有预料的相似程度。
self.weight.append(scores)
self.weight_sum.append(sum(scores)-scores[cnt])#需要减掉本身的权重。
self.vertex.append(1.0)
for _ in range(self.max_iter):
m = []
max_diff = 0
for i in range(self.D):#每个文本都要计算与其他所有文档的链接,然后计算出重要程度。
m.append(1-self.d)
for j in range(self.D):
if j == i or self.weight_sum[j] == 0:
continue
m[-1] += (self.d*self.weight[j][i]
/ self.weight_sum[j]*self.vertex[j])
#利用前面的公式求解
if abs(m[-1] - self.vertex[i]) > max_diff:
#找到该次迭代中,变化最大的一次情况。
max_diff = abs(m[-1] - self.vertex[i])
self.vertex = m
if max_diff <= self.min_diff:#当变化最大的一次,仍然小于某个阈值时认为可以满足跳出条件,不用再循环指定的次数。
break
self.top = list(enumerate(self.vertex))
self.top = sorted(self.top, key=lambda x: x[1], reverse=True)
def solve(self):#针对抽关键词
for doc in self.docs:
que = []
for word in doc:
if word not in self.words:
self.words[word] = set()
self.vertex[word] = 1.0
que.append(word)
if len(que) > 5:
que.pop(0)
for w1 in que:
for w2 in que:
if w1 == w2:
continue
self.words[w1].add(w2)
self.words[w2].add(w1)
for _ in range(self.max_iter):
m = {}
max_diff = 0
tmp = filter(lambda x: len(self.words[x[0]]) > 0,
self.vertex.items())
tmp = sorted(tmp, key=lambda x: x[1] / len(self.words[x[0]]))
for k, v in tmp:
for j in self.words[k]:
if k == j:
continue
if j not in m:
m[j] = 1 - self.d
m[j] += (self.d / len(self.words[k]) * self.vertex[k]) #利用之前提到的公式,简化的结果。
for k in self.vertex:
if k in m and k in self.vertex:
if abs(m[k] - self.vertex[k]) > max_diff:
max_diff = abs(m[k] - self.vertex[k])
self.vertex = m
if max_diff <= self.min_diff:
break
self.top = list(self.vertex.items())
self.top = sorted(self.top, key=lambda x: x[1], reverse=True)
转自:
https://blog.csdn.net/kamendula/article/details/51756552
http://www.hankcs.com/nlp/textrank-algorithm-java-implementation-of-automatic-abstract.html
https://blog.csdn.net/HHTNAN/article/details/78032712