Pytorch(三):数据变换 Transforms
目录
-
- 0. 简介
- 1. 裁剪类
-
- (1) torchvision.transforms.CenterCrop(size)
- (2) torchvision.transforms.FiveCrop(size)
- (3) torchvision.transforms.RandomCrop()
- (4) torchvision.transforms.RandomResizedCrop()
- (5) torchvision.transforms.TenCrop(size, vertical_flip=False)
- 2. 翻转和旋转类
-
- (1) torchvision.transforms.RandomHorizontalFlip(p=0.5)
- (2) torchvision.transforms.RandomVerticalFlip(p=0.5)
- (3) torchvision.transforms.RandomRotation()
- 3. 图像变换类
-
- (1) torchvision.transforms.Resize()
- (2) torchvision.transforms.Normalize()
- (3) torchvision.transforms.Pad()
- (4) torchvision.transforms.Grayscale(num_output_channels)
- (5) torchvision.transforms.RandomGrayScale(p=0.1)
- (6) torchvision.transforms.ColorJitter()
- (7) torchvision.transforms.RandomAffine()
- (8) torchvision.transforms.LinearTransformation()
- (9) torchvision.transforms.RandomErasing()
- (10) torchvision.transforms.GaussianBlur()
- (11) torchvision.transforms.RandomPerspective()
- 4. 图像格式转换类
-
- (1) torchvision.transforms.ConvertImageDtype()
- (2) torchvision.transforms.ToTensor
- (3) torchvision.transforms.ToPILImage(mode=None)
- 5. 系列变换类
-
- (1) torchvision.transforms.RandomApply()
- (2) torchvision.transforms.RandomChoice()
- (3) torchvision.transforms.RandomOrder()
- 6. 通用变换
-
- torchvision.transforms.lambda
- 7. 组合变换
-
- torchvision.transforms.Compose(transforms)
一般情况下,预加载的数据集或自己构造的数据集并不能直接用于训练机器学习算法,为了将其转换为训练模型所需的最终形式,我们可以使用
transforms 对数据进行处理,以使其适合训练。
0. 简介
在介绍 Dataset 时,提到 torchvision.datasets 中的数据集都有两个参数:
transform:可以对数据进行的变换;target_transform:可以对标签进行的变换。
而 torchvision.transforms.functional 模块提供了一些常用的转换,这些转换都能够接受以下三种输入:
PIL Image:对于 RGB 图像,size 为(W, H),将其转换为 NumPy array 后 size 为(H, W, C);Tensor Image:指具有 shape 为(C, H, W)的一个 tensor,C 为通道数,H、W 分别是图像的高和宽;batch of Tensor Images:指具有 shape 为(B, C, H, W)的一个 tensor,B 为 batchsize,也就是一个批次中的图像数量。
这里需要注意的一个地方是:
- Pytorch 中存储的
Tensor Image的存储格式为(C, H, W); - 而转换为 NumPy array 的
PIL Image的 存储格式 为(H, W, C);
所以在可视化图像数据或将 PIL Image 用于训练时常常会涉及格式转化,一般有以下几种情况。
可参考 Pytorch中Tensor与各种图像格式的相互转化
| 转换类型 | 操作 |
|---|---|
| PIL --> Tensor | 将参数 transform 设置为 torchvision.transforms.ToTensor() |
| Tensor --> PIL | 将参数 transform 设置为 torchvision.transforms.ToPILImage() |
| NumyP --> Tensor | img_tensor = img_numpy.transpose(2, 0, 1) |
| Tensor --> NumPy | img_numpy = img_tensor.transpose(1, 2, 0) |
ok 回到torchvision.transforms.functional 模块上,该模块提供的这些转换都可以通过 torchvision.transforms.compose() 组合在一起使用,对于构建比较复杂的转换任务(例如:分割任务)是非常有用的。下面会简单记录几个比较常见的转换,示例代码均是以单张图片作为输入。
参考 TORCHVISION.TRANSFORMS
1. 裁剪类
(1) torchvision.transforms.CenterCrop(size)
可用于 PIL Image 或 Tensor Image。
参数:
size,类型是元组序列或整数,表示裁剪后的图像大小。如果size是一个整数,则会生成一个方形的裁剪,即输出大小为(size,size);如果size是(h, w)之类的序列, 则输出大小为(h, w);如果提供长度为 1 的序列,那么输出大小将被认是(size [0],size [0])。
该转换的意义是对给定的图像进行中心裁剪,返回值是一张图像。被裁剪的图像类型可以是 PIL Image 或 Tensor Image,如果图像尺寸沿任何维度都小于输出尺寸 size,则图像会被以 0 填充,然后再进行中心裁剪。
示例代码。
# @Time : 2021/5/22 16:10
# @Author : ykx
# @File : 03-Transforms.py
# @Software : PyCharm
# -------------------------- #
# 1.中心裁剪
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 2, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
# 展示经过不同参数的中心裁剪后的图像
titles = ['int_size', 'sequence_size', '0 padding']
tfs = [transforms.CenterCrop(200),
transforms.CenterCrop((150, 200)),
transforms.CenterCrop(300)
]
for i in range(3):
figure.add_subplot(2, 2, i+2)
plt.title(titles[i])
plt.imshow(tfs[i](im))
plt.axis('off')
plt.show()

(2) torchvision.transforms.FiveCrop(size)
可用于 PIL Image 或 Tensor Image。
参数:
size,类型是元组序列或整数,表示裁剪后的图像大小。如果size是一个整数,则会生成一个方形的裁剪,即输出大小为(size,size);如果size是(h, w)之类的序列, 则输出大小为(h, w);如果提供长度为 1 的序列,那么输出大小将被认是(size [0],size [0])。
该转换的意义是对图像进行五点裁剪,被裁剪的图像类型可以是 PIL Image 或 Tensor Image,将给定的一幅图像裁剪为四个角和一个中心,因此 返回值是一个具有5个图像的元组。
示例代码。
# -------------------------- #
# 2.五点裁剪
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tf = transforms.FiveCrop(100)
ims = tf(im)
titles = ['left_up', 'right_up', 'left_bottom', 'right_bottom', 'center']
for i in range(5):
figure.add_subplot(2, 3, i+2)
plt.title(titles[i])
plt.imshow(ims[i])
plt.axis('off')
plt.show()

(3) torchvision.transforms.RandomCrop()
随机裁剪:torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
可用于 PIL Image 或 Tensor Image。
参数:
size:类型是元组序列或整数,表示裁剪后的图像大小。- 如果
size是一个整数,则会生成一个方形的裁剪,即输出大小为(size,size); - 如果
size是(h, w)类型的元组, 则输出大小为(h, w); - 如果提供长度为 1 的序列,那么输出大小将被认是
(size [0],size [0])。
- 如果
padding:可选参数,类型是元组序列或整数,默认是不进行填充。- 如果
padding是一个整数,那么填充将作用于所有边上; - 如果
padding是一个 长度为2 的序列,那么对应序列中不同值的填充将对应作用于 左/右 和 上/下 边界上; - 如果
padding是一个 长度为4 的序列,那么对应序列中不同值的填充将对应作用于 左、上、右、下 边界上。 - 注意,在
torchscript模式下是不支持single int填充的,因此需要使用 长度为1 的序列[padding,]。
- 如果
pad_if_needed:类型为布尔值,如果原图小于参数size,图像将被填充,以免引发异常,注意这里裁剪是在填充之后完成的。fill:类型是数字或字符串或元组,表示用于常值填充的像素值,也就是仅当padding_mode=constant时才会用到该参数。- 默认是0;
- 如果是长度为3 的元组,那么分别用于填充R、G、B通道;
- 注意,对于 Tensor Image 仅支持数字类型,对于 PIL Image 支持整数或字符串或元组类型。
padding_mode:表示填充的类型,有以下几种选择:constant:表示常值填充,常值由参数fill指定,默认填充类型;edge:表示以图像边缘处的最后一个像素值进行填充。如果输入是一个 5D 的 Tensor Image,那么最后的三个维度会被填充;reflect:表示反射填充,但不重复最边缘处的像素值,例如在reflect mode下以每边上的2个元素填充[1, 2, 3, 4],那么结果应该是[3, 2, 1, 2, 3, 4, 3, 2];symmetric:表示对称填充,重复最边缘处的像素值,例如在symmetric mode下以每边上的2个元素填充[1, 2, 3, 4],那么结果应该是[2, 1, 1, 2, 3, 4, 4, 3]。
该变换的意义是对给定的图像进行随机裁剪,返回值是一幅裁剪后的图像。
示例代码。
# -------------------------- #
# 3.随机裁剪
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.RandomCrop(150, padding=None, pad_if_needed=False, fill=None, padding_mode=None),
transforms.RandomCrop((150, 200), padding=None, pad_if_needed=False, fill=None, padding_mode=None),
transforms.RandomCrop(250, padding=20, pad_if_needed=True, fill=255, padding_mode='constant'),
transforms.RandomCrop(300, padding=(20, 40), pad_if_needed=True, fill=(0, 0, 255), padding_mode='edge'),
transforms.RandomCrop(350, padding=(20, 40), pad_if_needed=True, fill=0, padding_mode='symmetric'),
]
titles = ['sq_no_pad', 'rec_no_pad', 'sq_cons_pad', 'sq_edge_pad', 'sq_sym_pad']
for i in range(5):
im_i = tfs[i](im)
figure.add_subplot(2, 3, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(4) torchvision.transforms.RandomResizedCrop()
随机缩放裁剪:torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=
可用于 PIL Image 或 Tensor Image。
参数:
size,类型是元组序列或整数,表示裁剪后的图像大小。- 如果
size是一个整数,则会生成一个方形的裁剪,即输出大小为(size,size); - 如果
size是(h, w)类型的元组, 则输出大小为(h, w); - 如果提供长度为 1 的序列,那么输出大小将被认是
(size [0],size [0])。
- 如果
scale,类型是浮点型元组,表示缩放前裁剪后图像相对于原始图像的比例范围。ratio,类型是浮点型元组,表示缩放前裁剪后图像的宽高比范围。interpolation,由torchvision.transforms.InterpolationMode定义的插值模式, 默认值为InterpolationMode.NEAREST。- 如果输入为 Tensor Image,则仅支持
InterpolationMode.NEAREST、InterpolationMode.BILINEAR; - 为了反向兼容,也可使用整数值,eg:
PIL.Image.NEAREST。
- 如果输入为 Tensor Image,则仅支持
该变换的意义是将给定图像裁剪为随机的大小和宽高比,返回值是Tensor Image 或PIL Image。 上述参数执行了一个尺寸范围为 ( 0.08 , 1.0 ) (0.08, 1.0) (0.08,1.0)、宽高比范围在 ( 0.75 , 1.3333333333333333 ) (0.75, 1.3333333333333333) (0.75,1.3333333333333333) 的随机裁剪,并将裁剪后的图像调整至 size 大小。
示例代码。
# -------------------------- #
# 4.随机缩放裁剪
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(3, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tf = transforms.RandomResizedCrop(size=200, scale=(0.08, 1.0),
ratio=(0.75, 1.3333333333333333), interpolation=Image.BILINEAR)
im1 = tf(im)
figure.add_subplot(1, 2, 2)
plt.title('rc')
plt.imshow(im1)
plt.axis('off')
plt.show()

(5) torchvision.transforms.TenCrop(size, vertical_flip=False)
可用于 PIL Image 或 Tensor Image。
参数:
size,类型是元组序列或整数,表示裁剪后的图像大小。- 如果
size是一个整数,则会生成一个方形的裁剪,即输出大小为(size,size); - 如果
size是(h, w)类型的元组, 则输出大小为(h, w); - 如果提供长度为 1 的序列,那么输出大小将被认是
(size [0],size [0])。
- 如果
vertical_flip,类型是布尔值,True表示使用垂直翻转,False表示使用水平翻转,默认为False。
该变换的意义是将给定的图像裁剪为四个角和中心,以及翻转后的四个角和中心(默认情况下使用水平翻转),返回值是一个元素为 Tensor Image 或 PIL Image 的长度为 10 的元组。
示例代码。
# -------------------------- #
# 5.TenCrop()
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
# figure.add_subplot(2, 5, 1)
# plt.title('origin image')
# plt.imshow(im)
# plt.axis('off')
tf = transforms.TenCrop(100)
ims = tf(im)
titles = ['l_u', 'r_u', 'l_b', 'r_b', 'c', 'l_uf', 'r_uf', 'l_bf', 'r_bf', 'cf', ]
for i in range(10):
figure.add_subplot(2, 5, i+1)
plt.title(titles[i])
plt.imshow(ims[i])
plt.axis('off')
plt.show()

2. 翻转和旋转类
(1) torchvision.transforms.RandomHorizontalFlip(p=0.5)
可用于 PIL Image 或 Tensor Image。
参数:
p:类型是浮点型,表示水平翻转的概率,默认值是 0.5。返回值是原图或翻转后图像。
示例代码。
# -------------------------- #
# 8.随机水平翻转
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.RandomHorizontalFlip(p=0.1),
transforms.RandomHorizontalFlip(p=0.3),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomHorizontalFlip(p=0.7),
transforms.RandomHorizontalFlip(p=0.9)]
titles = ['p=0.1', 'p=0.3', 'p=0.5', 'p=0.7', 'p=0.9', ]
for i in range(5):
im_i = tfs[i](im)
figure.add_subplot(2, 3, i + 2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(2) torchvision.transforms.RandomVerticalFlip(p=0.5)
该变换与上一个随机水平翻转几乎一致,表示以给定的概率 p p p 对输入图像执行随机垂直翻转,返回值是Tensor Image 或 PIL Image,这里就不重复叙述了。
(3) torchvision.transforms.RandomRotation()
随机旋转:torchvision.transforms.RandomRotation(degrees, interpolation=
可用于 PIL Image 或 Tensor Image。
参数:
degrees,类型是数字或元组,表示旋转的角度范围,如果给定的度数是数字而不是序列(min, max),则度数的范围将是(-degrees, +degrees)。interpolation,由torchvision.transforms.InterpolationMode定义的插值模式, 默认值为InterpolationMode.NEAREST。- 如果输入为 Tensor Image,则仅支持
InterpolationMode.NEAREST、InterpolationMode.BILINEAR; - 为了反向兼容,也可使用整数值,eg:
PIL.Image.NEAREST。
- 如果输入为 Tensor Image,则仅支持
expand,可选参数,布尔型,表示是否扩张输出。- 如果为
True,则扩展输出使其足够大以容纳整个旋转后的图像; - 如果为
False或None,则使输出图像的大小与输入图像的大小相同; - 注意,
expand假定围绕中心旋转且没有平移。
- 如果为
center,可选参数,类型为元组,表示旋转中心(x, y),默认是图像的中心,原点是图像左上角。fill,类型为数字或元组序列,表示转换后图像外部区域的像素填充值,默认值为0。- 如果类型为数字,则该值用于所有分段;
- 如果输入为PIL Image,则该选项仅适用于
Pillow> = 5.0.0的版本。
resample,可选参数,类型为整数,官方表示不推荐使用该参数,且自v0.10.0版本起将被删除,如有需要改用interpolation参数,Image.NEAREST (0), Image.BILINEAR (2) or Image.BICUBIC (3)。
该变换的意义是按给定角度旋转图像,返回值是Tensor Image 或 PIL Image。
示例代码。
# -------------------------- #
# 3.随机旋转
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 2, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = transforms.RandomRotation((40, 90), expand=True)
im1 = tfs(im)
figure.add_subplot(1, 2, 2)
plt.title('r')
plt.imshow(im1)
plt.axis('off')
plt.show()

3. 图像变换类
(1) torchvision.transforms.Resize()
缩放:torchvision.transforms.Resize(size, interpolation=
可用于 PIL Image 或 Tensor Image。
参数:
size,类型是元组序列或整数,表示裁剪后的图像大小。- 如果
size是一个整数,则图像的较短边会与该数匹配,即如果h > w,图像将被缩放为(size * height / width, size); - 如果
size是(h, w)类型的元组, 则输出大小为(h, w); - 在
torchscript模式下,不支持单个 int 的size,需要使用长度为 1 的序列:[size, ]。
- 如果
interpolation,由torchvision.transforms.InterpolationMode定义的插值模式, 默认值为InterpolationMode.NEAREST。- 如果输入为 Tensor Image,则仅支持
InterpolationMode.NEAREST、InterpolationMode.BILINEAR; - 为了反向兼容,也可使用整数值,eg:
PIL.Image.NEAREST。
- 如果输入为 Tensor Image,则仅支持
该变换的意义是将输入图像调整至给定的尺寸,返回值是Tensor Image 或 PIL Image。
示例代码。
# -------------------------- #
# 1.缩放 Resize()
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 2, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.Resize(150, interpolation=0),
transforms.Resize((100, 200), interpolation=0),
transforms.Resize(80, interpolation=2)]
titles = ['square-0', 'rectangle-0', 'square-2']
for i in range(3):
im_i = tfs[i](im)
figure.add_subplot(2, 2, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(2) torchvision.transforms.Normalize()
归一化:torchvision.transforms.Normalize(mean, std, inplace=False)
只能用于 Tensor Image。
参数:
mean,类型是元组序列,表示每个通道的均值;std,类型是元组序列,表示每个通道的标准差;inplace,可选参数,类型是布尔值,表示是否以in-place执行该操作。
该变换的意义是用均值和标准差对 Tensor Image 进行归一化,即给定 n 个通道的均值 (mean[1], mean[2], ..., mean[n]) 和 标准差 (std[1], std[2]), ..., std[n],那么输出图像:output[channel] = (input[channel] - mean[channel])/std[channel],返回值是 Tensor Image。
示例代码。
# -------------------------- #
# 2.归一化
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tf1 = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
tf2 = transforms.ToPILImage()
im_tensor = tf1(im)
im_pil = tf2(im_tensor)
figure.add_subplot(1, 2, 2)
plt.title('normalized')
plt.imshow(im_pil)
plt.axis('off')
plt.show()
这个输出的图片有点吓人哈哈哈~

(3) torchvision.transforms.Pad()
填充:torchvision.transforms.Pad(padding, fill=0, padding_mode='constant')
可用于 PIL Image 或 Tensor Image。
参数:
padding,类型是元组序列或整数,表示用于填充边界的大小。- 如果
padding是一个整数,那么填充将作用于所有边上; - 如果
padding是一个 长度为2 的序列,那么对应序列中不同值的填充将对应作用于 左/右 和 上/下 边界上; - 如果
padding是一个 长度为4 的序列,那么对应序列中不同值的填充将对应作用于 左、上、右、下 边界上。 - 注意,在
torchscript模式下是不支持single int填充的,因此需要使用 长度为1 的序列[padding,]。
- 如果
fill,类型是数字或字符串或元组,表示用于常值填充的像素值,也就是仅当padding_mode=constant时才会用到该参数。- 默认是0;
- 如果是长度为3 的元组,那么分别用于填充R、G、B通道;
- 注意,对于 Tensor Image 仅支持数字类型,对于 PIL Image 支持整数或字符串或元组类型。
padding_mode,表示填充的类型,有以下几种选择:constant:表示常值填充,常值由参数fill指定,默认填充类型;edge:表示以图像边缘处的最后一个像素值进行填充。如果输入是一个 5D 的 Tensor Image,那么最后的三个维度会被填充;reflect:表示反射填充,但不重复最边缘处的像素值,例如在reflect mode下以每边上的2个元素填充[1, 2, 3, 4],那么结果应该是[3, 2, 1, 2, 3, 4, 3, 2];symmetric:表示对称填充,重复最边缘处的像素值,例如在symmetric mode下以每边上的2个元素填充[1, 2, 3, 4],那么结果应该是[2, 1, 1, 2, 3, 4, 4, 3]。
该变换的意义是在特定的填充模式下对以给定的填充值对图像进行填充,返回值是一幅填充后的图像。
示例代码。
# -------------------------- #
# 3.填充
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(3, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.Pad(padding=20, fill=0, padding_mode='constant'),
transforms.Pad(padding=20, fill=(255, 0, 255), padding_mode='constant'),
transforms.Pad(padding=20, fill=255, padding_mode='constant'),
transforms.Pad(padding=(20, 40), fill=0, padding_mode='constant'),
transforms.Pad(padding=(20, 40, 60, 80), fill=0, padding_mode='constant'),
transforms.Pad(padding=30, fill=0, padding_mode='edge'),
transforms.Pad(padding=40, fill=0, padding_mode='reflect'),
transforms.Pad(padding=50, fill=0, padding_mode='symmetric'),
transforms.Grayscale(num_output_channels=1),
transforms.Grayscale(num_output_channels=3)]
titles = ['all-black-padding', 'all-purple-padding', 'all-red-padding',
'lr-tb-padding', 'l-t-r-b-padding',
'edge-mode', 'reflect-mode', 'symmetric-mode']
for i in range(8):
im_i = tfs[i](im)
figure.add_subplot(3, 3, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(4) torchvision.transforms.Grayscale(num_output_channels)
可用于 PIL Image 或 Tensor Image。
参数:
num_output_channels,指输出通道数。- 当设置为 1 时,输出为通道数=1 的灰度图;
- 当设置为 3 时,输出为通道数=3 的彩色图,通道为
(r,g,b)。
该转换的意义是将图像转换为灰度图,同样适用于 PIL Image 或 Tensor Image 的图像类型,返回值是一幅灰度图像。
示例代码。
# -------------------------- #
# 4.转换为灰度图
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.Grayscale(num_output_channels=1),
transforms.Grayscale(num_output_channels=3)]
titles = ['out_c=1', 'out_c=3']
for i in range(2):
im_i = tfs[i](im)
figure.add_subplot(1, 3, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(5) torchvision.transforms.RandomGrayScale(p=0.1)
可用于 PIL Image 或 Tensor Image。
参数:
p:类型为浮点型,表示图像被转换为灰度图的概率,默认为 0.1。- 如果输入图像是 1 通道,那么输出的灰度图也是 1 通道;
- 如果输入图像是 3 通道:那么输出的灰度图也是 3 通道,其中
r == g == b。
该变换的意义是以一个给定的概率 p 对图像进行灰度图转换,因此返回值是原图或灰度图,保持原图的概率为 1-p。
示例代码。
# -------------------------- #
# 5.随机转换灰度图
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.RandomGrayscale(p=0.1),
transforms.RandomGrayscale(p=0.3),
transforms.RandomGrayscale(p=0.5),
transforms.RandomGrayscale(p=0.7),
transforms.RandomGrayscale(p=0.9)]
titles = ['p=0.1', 'p=0.3', 'p=0.5', 'p=0.7', 'p=0.9', ]
for i in range(5):
im_i = tfs[i](im)
figure.add_subplot(2, 3, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(6) torchvision.transforms.ColorJitter()
随机更改图像的亮度,对比度,饱和度和色调:torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
可用于PIL Image或Tensor Image。
参数:
brightnesss:类型为浮点型数字或浮点型元组(min, max),表示对亮度进行调整的程度,应为非负数,因此该参数会从(max(0, 1 - brightness), 1 + brightness)中选取。contrast:类型为浮点型数字或浮点型元组(min, max),表示对比度的调整程度,应为非负数,因此该参数会从(max(0, 1 - contrast), 1 + contrast)中选取。saturation:类型为浮点型数字或浮点型元组(min, max),表示对饱和度进行调整的程度,应为非负数,因此该参数会从(max(0, 1 - saturati), 1 + saturation)中选取。hue:类型为浮点型数字或浮点型元组(min, max),表示对色调进行调整的程度。如果给定浮点型数字,那么选取范围为[-hue, hue],否则为[min, max],该参数应当满足:0 <= hue <= 0.5,或-0.5 <= min <= max <= 0.5
该变换的意义是返回值是随机更改图像的亮度,对比度,饱和度和色调,如果输入图像是 PIL Image,则不支持模式为 1, L, I, F 或 具有 alpha channel 的模式,返回值为Tensor Image 或PIL Image。
示例代码。
# -------------------------- #
# 6.色度变化 ColorJitter()
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(2, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0),
transforms.ColorJitter(brightness=0, contrast=0.5, saturation=0, hue=0),
transforms.ColorJitter(brightness=0, contrast=0, saturation=0.5, hue=0),
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0.5),
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.5, hue=0.3)]
titles = ['b', 'c', 's', 'h', 'bcsh']
for i in range(5):
im_i = tfs[i](im)
figure.add_subplot(2, 3, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(7) torchvision.transforms.RandomAffine()
随机仿射:torchvision.transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, interpolation=
可用于 PIL Image 或 Tensor Image。
参数:
degrees:可供选择的旋转度数范围,类型是数字或元组序列。- 如果是数字,那么实际范围是
(-degrees, +degrees); - 如果是序列,那么范围直接就是
(min, max); degrees=0表示不进行旋转。
- 如果是数字,那么实际范围是
translate:可选参数,类型是元组,表示水平和垂直方向上最大平移的绝对值比例,默认不进行平移。例如,translate=(a,b),那么水平方向的平移程度dx将从(-img_width * a, img_width * a)中随机抽取,垂直方向的平移程度dy将从(-img_height * b, img_height * b)中随机抽取。scale:可选参数,类型是元组,表示缩放因子的区间,默认不进行缩放。例如,scale=(a,b),那么缩放因子将从(a,b)中随机抽取。shear:可选参数,类型是数字或元组序列,表示可供选择的剪切度数范围,默认不进行剪切。- 如果是数字,
(-shear, shear)范围内的平行剪切将会应用在x轴上; - 如果是长度为2 的元组,那么
(shear[0], shear[1])范围内的平行剪切将会应用在x轴上; - 如果是长度为4 的元组,那么
(shear[0], shear[1])范围内的剪切会应用在x轴上,(shear[2], shear[3])范围内的剪切会应用在y轴上。
- 如果是数字,
interpolation:由torchvision.transforms.InterpolationMode定义的插值模式, 默认值为InterpolationMode.NEAREST。- 如果输入为 Tensor Image,则仅支持
InterpolationMode.NEAREST、InterpolationMode.BILINEAR; - 为了反向兼容,也可使用整数值,eg:
PIL.Image.NEAREST。
- 如果输入为 Tensor Image,则仅支持
fill,类型为数字或元组序列,表示转换后图像外部区域的像素填充值,默认值为0。- 如果类型为数字,则该值用于所有分段;
- 如果输入为PIL Image,则该选项仅适用于
Pillow> = 5.0.0的版本。
fillcolor,可选参数,类型是数字或元组序列,官方表示不推荐使用该参数,且自v0.10.0版本起将被删除,如有需要改用fill参数。resample,可选参数,类型为整数,官方表示不推荐使用该参数,且自v0.10.0版本起将被删除,如有需要改用interpolation参数,Image.NEAREST (0), Image.BILINEAR (2) or Image.BICUBIC (3)。
该变换的意义是保持中心不变的随机仿射,返回值是一幅仿射后的图像。
但是在Pytorch中使用时,发现参数和官网上的不太一致,所以示例代码中只展示了可以使用的参数:
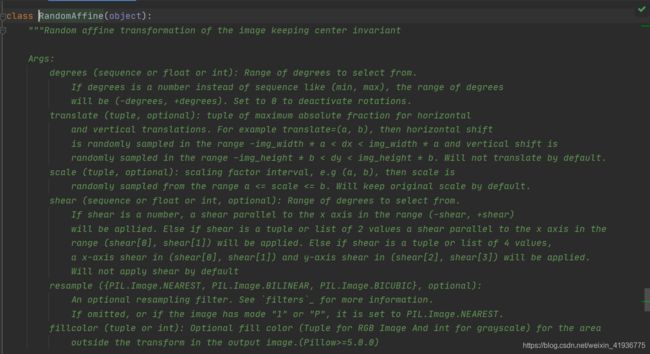
示例代码。
# -------------------------- #
# 7.随机仿射变换
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(3, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.RandomAffine(135, fillcolor=(255, 0, 0)),
transforms.RandomAffine((45, 90), fillcolor=(0, 0, 255)),
transforms.RandomAffine(0, translate=(0, 0.5), fillcolor=(0, 255, 0)),
transforms.RandomAffine(0, scale=(0.5, 2), fillcolor=125),
transforms.RandomAffine(0, shear=(10, 20, 30, 40), fillcolor=225),
transforms.RandomAffine(0, fillcolor=175, resample=0),
transforms.RandomAffine(0, fillcolor=75, resample=2),
transforms.RandomAffine(0, translate=(0, 0.5), scale=(0.5, 2), shear=(5, 10, 15, 20), fillcolor=255, resample=0)
]
titles = ['135 rotation', '(45,90) rotation', 'translate', 'scale', 'shear',
'nearest', 'Bilinear', 'all']
for i in range(8):
im_i = tfs[i](im)
figure.add_subplot(3, 3, i + 2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(8) torchvision.transforms.LinearTransformation()
线性变换:torchvision.transforms.LinearTransformation(transformation_matrix, mean_vector)
只能用于Tensor Image。
参数:
transformation_matrix:是一个形状为[D x D]的 tensor,其中D=C x H x W,表示一个变换方阵;mean_vector:是一个形状为[D]的 tensor,其中D=C x H x W,表示一个均值向量。
该变换的意义是对 Tensor Image 进行线性变换( A x + B Ax+B Ax+B),将输入图像减去均值向量后,与变换方阵做点积,并将结果调整至原始形状,返回值是一个Tensor Image。
(9) torchvision.transforms.RandomErasing()
随机抹除像素值:torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
只能用于 Tensor Image。
参数:
p,类型为浮点型,表示随机擦除像素操作被执行的概率;scale,元组序列或浮点型,表示被擦除的区域相对于输入图像的比例;ratio,元组序列或浮点型,表示被擦除区域的宽高比;value,类型为整数或元组序列或字符串random,默认值为0。- 如果为单一整数,则用于擦除所有像素;
- 如果是一个长度为 3 的元组,则分别用于擦除
R,G,B通道的像素; - 如果是
random,则使用随机值擦除每个像素。
inplace,类型为布尔值,默认是False,表示是否以in-place执行该操作。
该变换的意义是在输入 Tensor Image 图像中随机选取一个矩形区域并将该区域中的像素擦除,返回值是 erased Tensor Image。可以参考 Random Erasing Data Augmentation
示例代码。
# -------------------------- #
# 11.随机擦除区域像素
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tf1 = transforms.ToTensor()
tf2 = transforms.ToPILImage()
im_tensor = tf1(im)
tfs = [transforms.RandomErasing(p=0.8, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False),
transforms.RandomErasing(p=0.8, scale=(0.05, 0.25), ratio=(3.3, 0.3), value=0, inplace=False)]
titles = ['1', '2']
for i in range(2):
im_i = tfs[i](im_tensor)
im_pil = tf2(im_i)
figure.add_subplot(1, 3, i+2)
plt.title(titles[i])
plt.imshow(im_pil)
plt.axis('off')
plt.show()

(10) torchvision.transforms.GaussianBlur()
高斯模糊:torchvision.transforms.GaussianBlur(kernel_size, sigma=(0.1, 2.0))
可用于 PIL Image或 Tensor Image。
参数:
kernel_size,类型为整数或元组,表示高斯核的大小。sigma,浮点型或元组浮点型(min, max),表示用于创建高斯核以执行模糊的标准差。- 如果是浮点型数字,则
sigma是固定的; - 如果是元组
(min, max),则从给定范围内均匀的选择sigma。
- 如果是浮点型数字,则
该变换的意义是对输入图像进行高斯模糊,返回值是Tensor Image 或 PIL Image。
(11) torchvision.transforms.RandomPerspective()
随机透视变换:torchvision.transforms.RandomPerspective(distortion_scale=0.5, p=0.5, interpolation=
可用于 PIL Image 或 Tensor Image。
参数:
distortion_scale,类型为浮点型数字,表示用于控制失真程度的参数,范围为 0到1,默认值为 0.5。p,类型为浮点型数字,表示图像进行透视变换的概率,默认为 0.5。interpolation:由torchvision.transforms.InterpolationMode定义的插值模式, 默认值为InterpolationMode.NEAREST。- 如果输入为 Tensor Image,则仅支持
InterpolationMode.NEAREST、InterpolationMode.BILINEAR; - 为了反向兼容,也可使用整数值,eg:
PIL.Image.NEAREST。
- 如果输入为 Tensor Image,则仅支持
fill,类型为数字或元组,表示转换后图像外部区域的像素填充值,默认值为0。- 如果类型为数字,则该值用于所有分段;
- 如果输入为PIL Image,则该选项仅适用于
Pillow> = 5.0.0的版本。
该变换的意义是以给定的概率 p p p 对输入图像执行随机透视变换,返回值是Tensor Image 或 PIL Image;
示例代码。
# -------------------------- #
# 11.随机透视变换
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.RandomPerspective(0.5, 0.5, interpolation=Image.BILINEAR),
transforms.RandomPerspective(0.3, 0.7, interpolation=Image.BILINEAR)]
titles = ['0.5-0.5', '0.3-0.7']
for i in range(2):
im_i = tfs[i](im)
figure.add_subplot(1, 3, i+2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

4. 图像格式转换类
(1) torchvision.transforms.ConvertImageDtype()
数据类型转换:torchvision.transforms.ConvertImageDtype(dtype: torch.dtype)
只能用于 Tensor Image。
参数:
dtype,表示所需的输出数据的类型。
该变换的意义是将 Tensor Image 转换为给定的 dtype 并相应地缩放像素值,该变换无返回值。
注意,
Runtime Error,当尝试将torch.float32转换为torch.int32或torch.int64时,以及尝试将torch.float64转换为torch.int64时,可能会导致溢出错误,因为浮点类型无法在整数类型的范围内存储连续的整数。
(2) torchvision.transforms.ToTensor
该变换的意义是:
- 如果 PIL Image 属于其中一种模式
(L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)或numpy.ndarray具有dtype = np.uint8,那么将 PIL Image 或范围为[0, 255]的numpy.ndarray(H xW x C)转换为形状为(C x H x W)的范围为[0.0,1.0]的 Torch.FloatTensor Image; - 在其他情况下,返回的 Tensor Image 不进行缩放。
(3) torchvision.transforms.ToPILImage(mode=None)
参数:
mode,可选参数,表示输入数据的色彩模式和像素深度,默认为None。- 如果输入具有 4 个通道,则假定该模式为
RGBA; - 如果输入具有 3 个通道,则该模式假定为
RGB; - 如果输入具有 2 个通道,则该模式假定为
LA; - 如果输入具有1个通道,则模式由数据类型(即
int,float,short)决定。
- 如果输入具有 4 个通道,则假定该模式为
该变换的意义是将形状为 C x H x W 的 Tensor Image 或形状为 H x W x C 的 Ndarray Image 转换为 PIL Image,此转换不支持torchscript。
5. 系列变换类
(1) torchvision.transforms.RandomApply()
随机应用变换:torchvision.transforms.RandomApply(transforms, p=0.5)
可应用于 PIL Image 或 Tensor Image。
参数:
transforms,类型为序列或torch.nn.Module,表示一个以变换为元素的列表。p,表示给定的应用列表中变换的概率。
该变换的意义是以给定的概率 p p p 对输入图像做一系列的变换 transforms;
# -------------------------- #
# 1.随机应用 RandomApply()
# -------------------------- #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 3, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.CenterCrop(200),
transforms.Grayscale(num_output_channels=3),
transforms.ColorJitter(0.5, 0.5, 0.5, 0.5)]
tf = [transforms.RandomApply(tfs, 0.7),
transforms.RandomApply(tfs, 0.5)]
titles = ['p=0.7', 'p=0.5']
for i in range(2):
im_i = tf[i](im)
figure.add_subplot(1, 3, i + 2)
plt.title(titles[i])
plt.imshow(im_i)
plt.axis('off')
plt.show()

(2) torchvision.transforms.RandomChoice()
随机选择一个变换:torchvision.transforms.RandomChoice(transforms)
仅适用于 PIL Image 的变换。
参数:
transforms,表示一个以变换为元素的列表。
该变换的意义是从变换列表 transforms 中随机选择一个转换应用于输入图像, 此转换不支持torchscript。
示例代码。
# ------------------------------ #
# 2.随机选择变换应用 RandomChoice()
# ------------------------------ #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 2, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.CenterCrop(200),
transforms.Grayscale(num_output_channels=3),
transforms.ColorJitter(0.5, 0.5, 0.5, 0.5)]
tf = transforms.RandomChoice(tfs)
im1 = tf(im)
figure.add_subplot(1, 2, 2)
plt.title('choice')
plt.imshow(im1)
plt.axis('off')
plt.show()

(3) torchvision.transforms.RandomOrder()
以随机顺序应用列表中变换:torchvision.transforms.RandomOrder(transforms)
仅适用于 PIL Image 的变换。
参数:
transforms,表示一个以变换为元素的列表。
该变换的意义是以随机顺序对输入图像应用变换列表 transforms 中的转换, 此转换不支持torchscript。
示例代码。
# ------------------------------ #
# 3.随机顺序应用变换 RandomOrder()
# ------------------------------ #
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt # plt 用于显示图片
figure = plt.figure()
im = Image.open('./data/faces/person.jpg') # im.size=(239,209)
# 展示原图像
figure.add_subplot(1, 2, 1)
plt.title('origin image')
plt.imshow(im)
plt.axis('off')
tfs = [transforms.CenterCrop(200),
transforms.Grayscale(num_output_channels=3),
transforms.ColorJitter(0.5, 0.5, 0.5, 0.5)]
tf = transforms.RandomOrder(tfs)
im1 = tf(im)
figure.add_subplot(1, 2, 2)
plt.title('choice')
plt.imshow(im1)
plt.axis('off')
plt.show()

6. 通用变换
torchvision.transforms.lambda
参数:
lambda,相当于函数,用于转换。
该变换需要用户自定义lambd,此转换不支持torchscript。 可以看下官网的例子,

7. 组合变换
torchvision.transforms.Compose(transforms)
参数:
transforms,是一个Transform objects构成的列表。
表示将几个变换组合在一起使用, 此转换不支持torchscript。例如,
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])