数据挖掘——时间序列算法之平滑法
数据挖掘——时间序列算法之平滑法
- 前言
- 平滑法
-
- 1、简述
- 2、移动平均法
-
- 2.1、简单移动平均
- 2.2、加权移动平均法
- 3、指数平滑法
-
- 3.1、一次指数平滑
- 3.2 二次平滑指数
- 3.3、三次平滑指数
前言
时间序列是许多数据挖掘任务重最常见的类型之一,同时也比较难处理。这篇记录下我所理解下的时间序列模型的算法。注意,这不是特征工程,而是算法(暂时是这样理解的,毕竟目前还没使用过这些方法做特征工程)。
关于其他时间预测算法详见我的其他博文:
1、平滑法
2、趋势拟合法
3、组合模型
4、AR模型
5、MA模型
6、ARMA模型
7、ARIMA模型
8、ARCH模型
9、GARCH模型及其衍生模型
平滑法
1、简述
所谓时间序列平滑预测是指用平均的方法,把时间序列中的随机波动剔除掉,使序列变得比较平滑,以反映出其基本轨迹,并结合一定的模型进行预测。所平均的范围可以是整个序列(整体平均数),也可以是序列中的一部分(局部平均数);所用平均数可以是简单平均数,也可以是加权平均数。在一次平均之后,就局部平均而言,还可以进行第二次、第三次以至更多次的平均,进行多层次的平滑。
所以,平滑预测的方法也是多种多样的。
平滑法常用于趋势分析和预测,利用修匀技术,削弱短期随机波动对序列的影响,使序列平滑化。根据所使用的平滑技术的不同,可具体分为移动平均法和指数平滑法。
2、移动平均法
移动平均法是用一组最近的实际数据值来预测未来一期或几期内公司产品的需求量、公司产能等的一种常用方法。移动平均法适用于即期预测。当产品需求既不快速增长也不快速下降,且不存在季节性因素时,移动平均法能有效地消除预测中的随机波动,是非常有用的。------来自百度百科移动平均法根据预测时使用的各元素的权重不同,可以分为:**简单移动平均法**和**加权移动平均法。**
2.1、简单移动平均
简单时间序列平滑法是指用简单平均数进行预测的一类预测方法。当给定一组数据或观测值后,这些数值的平均数的种类很多,常见的有算术平均数、几何平均数、调和平均数、加权算术平均数、移动平均数与指数平滑平均数等。这些平均数各有各的计算方法,各有各的特点与用途,在使用平均法进行预测时,首先要判断使用哪一种或哪几种能够满足需要,然后再根据相应的计算方法求之。
由于算术平均数、几何平均数、调和平均数、加权算术平均数的计算方法相对其余几种来说,比较简单,故常称这几种平均数的求法为“简单平均法”。
举例:这里仅使用算数平均数来求预测值:
对应公式:
F ( t + 1 ) = V ( 1 ) + V ( 2 ) + . . . + V ( t ) t (1) F(t + 1) = \frac{V(1)+V(2)+...+V(t)}{t}\tag{1} F(t+1)=tV(1)+V(2)+...+V(t)(1)
其中V(t)是第t时刻的实际值,F(t+1)是使用平均值得到的未来预测值
例如:某家商店在2047年、2048年、2049年的限售量分别为,25,35,30,那么预测在2050年该家商店的限售量为 25 + 35 + 30 3 = 30 \frac{25+35+30}{3}=30 325+35+30=30
上面的例子仅是使用了简单的算数平均,当然还有更复杂些的计算方法(几何平均数、调和平均数、加权算术平均数的计算方法相对其余几种)。
2.2、加权移动平均法
加权移动平均法就是根据同一个移动段内不同时间的数据对预测值得影响程度,分别寄予不同的系数以预测未来值。
从上面介绍的简单移动平均算法可以明显看出,不同时期都会被视为同等重要,显然这是不符合实际认知的,因为距离当前时期较远的时期对预测值的重要性比那些距离当前时期较近的时期小(有点绕),所以为了改善这种情况,需要不同的对待移动期内的各个数据,对近期数据给予较大的权数,对较远的数据给予较小的权数,这样来弥补简单移动平均法的不足。
数学描述:
F n + 1 = ∑ i = n − k − 1 n + 1 V i x i (2) F_{n+1}= \sum_{i=n-k-1}^{n+1}V_{i}x_{i}\tag{2} Fn+1=i=n−k−1∑n+1Vixi(2)
其中: F n + 1 是 预 测 值 , V i 是 第 i 期 的 实 际 值 , n 是 本 期 数 , k 是 移 动 跨 期 , x i 是 第 i 期 实 际 值 的 权 重 , 且 权 重 和 等 于 1 F_{n+1}是预测值,V_{i}是第i期的实际值,n是本期数,k是移动跨期,x_{i}是第i期实际值的权重,且权重和等于1 Fn+1是预测值,Vi是第i期的实际值,n是本期数,k是移动跨期,xi是第i期实际值的权重,且权重和等于1
注:用加权移动平均法求预测值,对近期的趋势反映较敏感,但如果一组数据有明显的季节性影响时,用加权移动平均法所得到的预测值可能会出现偏差。因此,有明显的季节性变化因素存在时,最好不要加权。
看不懂?下面举例:
----------------------------------------------------------------------------------------------------------------------
例题:某商场1月份至11月份的实际销售额如表所示。假定跨越期为3个月,权数为l、2、3,试用加权移动平均法预测12月份的销售额
| 月份 | 销售额 | 3个月的加权移动平均 |
|---|---|---|
| 1 | 38 | - |
| 2 | 45 | - |
| 3 | 35 | 38.83 |
| 4 | 49 | 43.67 |
| 5 | 70 | 43.67 |
| 6 | 43 | 57.17 |
| 7 | 46 | 53.00 |
| 8 | 55 | 49.00 |
| 9 | 45 | 50.00 |
| 10 | 68 | 48.5 |
| 11 | 64 | 58.17 |
| 12 | 62.17 |
解:(这里k取3)
V 4 = 3 ∗ 35 + 2 ∗ 45 + 1 ∗ 38 1 + 2 + 3 = 38.83 V 5 = 3 ∗ 49 + 2 ∗ 35 + 1 ∗ 45 1 + 2 + 3 = 43.67 … … F ( 12 ) = 3 ∗ 64 + 2 ∗ 68 + 1 ∗ 45 1 + 2 + 3 = 62.17 V_{4}=\frac{3*35 + 2*45 +1*38}{1+2+3}=38.83\\ V_{5}=\frac{3*49 + 2*35 +1*45}{1+2+3}=43.67\\ ……\\ \\ \\ F(12)=\frac{3*64 + 2*68 +1*45}{1+2+3}=62.17 V4=1+2+33∗35+2∗45+1∗38=38.83V5=1+2+33∗49+2∗35+1∗45=43.67……F(12)=1+2+33∗64+2∗68+1∗45=62.17
----------------------------------------------------------------------------------------------------------------------
3、指数平滑法
基本思想:最近的过去势态,在某种程度上会持续到最近的未来,所以将较大的权重放在最近的数据上。
指数平滑法是生产预测中常用的一种方法。也用于中短期经济发展趋势预测,所有预测方法中,指数平滑是用得最多的一种。简单的全期平均法是对时间数列的过去数据一个不漏地全部加以同等利用;移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期资料更大的权重;而指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。--from 百度百科
也就是说指数平滑法是在移动平均法基础上发展起来的一种时间序列分析预测法,它是通过计算指数平滑值,配合一定的时间序列预测模型对现象的未来进行预测。其原理是任一期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均。
3.1、一次指数平滑
数学表达:
S t ( 1 ) = α ⋅ y t + ( 1 − α ) ⋅ S t − 1 ( 1 ) (3) S_{t}^{(1)}=\alpha \cdot y_{t} +( 1- \alpha)\cdot S_{t-1}^{(1)} \tag{3} St(1)=α⋅yt+(1−α)⋅St−1(1)(3)
其中, S t ( 1 ) 时 间 t 的 平 滑 值 , y t 时 间 t 的 真 实 值 , S t − 1 ( 1 ) 时 间 t − 1 的 平 滑 值 , α ⊆ [ 0 , 1 ] 平 滑 参 数 。 S_{t}^{(1)}时间t的平滑值,y_{t}时间t的真实值,S_{t-1}^{(1)}时间t-1的平滑值, \alpha\subseteq [0,1]平滑参数。 St(1)时间t的平滑值,yt时间t的真实值,St−1(1)时间t−1的平滑值,α⊆[0,1]平滑参数。
可以看出指数平滑法数对移动平滑法的升级,即弥补了简单平均法的不能体现各时期重要性的缺点,又弥补了加权平均法只能关注最近时期的缺点。
式(3)中各自成分其含义如下:
- S t S_{t} St具有逐期追溯的性质,可包括全部数据,但实际计算时,仅需要两个值,即 y t y_{t} yt、 S t − 1 ( 1 ) S_{t-1}^{(1)} St−1(1);
- 平滑指数 α \alpha α以指数形式递减,故称之为指数平滑法。平滑指数取值很重要,平滑常数 α \alpha α决定了平滑水平以及对预测值与实际结果之间差异的响应速度: α \alpha α越接近于1,远期实际值对本期平滑值影响程度下降的越快;越接近于0,远期实际值对本期平滑值的影响程度下降的越慢。所以,当时间数列相对平稳时,可取较大 α \alpha α;当时间数列波动较大时,应取较小的 α \alpha α,以此不忽略远期实际值的影响。经验如下(他人):指数平滑系数α的确定
(1)当时间序列呈现较稳定的水平趋势时,应选较小的α,一般可在0.05~0.20之间取值‘
(2)当时间序列有波动,但长期趋势变化不大时,可选稍大的α值,常在0.1~0.4之间取值;
(3)当时间序列波动很大,长期趋势变化幅度较大,呈现明显且迅速的上升或下降趋势时,宜选择较大的α值,如可在0.6~0.8间选值。以使预测模型灵敏度高些,能迅速跟上数据的变化。
(4)当时间序列数据是上升(或下降)的发展趋势类型,α应取较大的值,在0.6~1之间。
初始值的确定:
求第一期的平滑值 S 1 ( 1 ) = α ⋅ y 1 + ( 1 − α ) ⋅ S 0 ( 1 ) S_{1}^{(1)}=\alpha \cdot y_{1} + (1-\alpha) \cdot S_{0}^{(1)} S1(1)=α⋅y1+(1−α)⋅S0(1)时,很明显不存在 y 0 y_{0} y0,便也无法产生 S 0 ( 1 ) S_{0}^{(1)} S0(1),用下面的两种方法解决此问题:
(1)如果能够找到 y 1 y_{1} y1以前的历史资料,那么当数据较少时,使用全期平均、移动平均;当数据较多时,可用最小二乘法。
(2)如果仅有从 y 1 y_{1} y1开始的数据,那么确定初始值的方法:取 S 1 ( 1 ) = y 1 S_{1}^{(1)}=y_{1} S1(1)=y1;待积累若干数据后,取 S 1 S_{1} S1等于前面若干数据的简单算数平均数,如: S 0 ( 1 ) = y 1 + y 2 + y 3 3 S_{0}^{(1)}=\frac{y_{1}+y_{2}+y_{3}}{3} S0(1)=3y1+y2+y3
-------------------------------------------------------------------------------------------------------------------------------
举个例子:
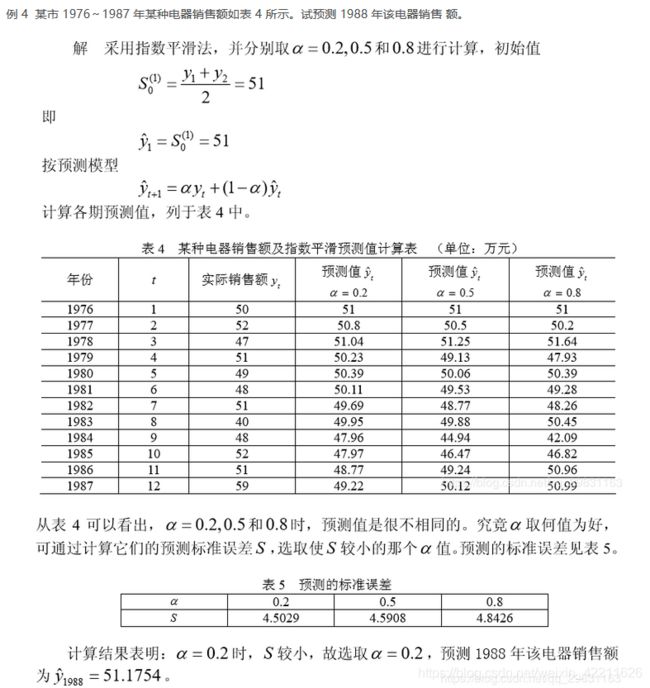
3.2 二次平滑指数
一次指数平滑法虽然克服了移动平均法的缺点,但当时间序列的变动出现直线趋势时,用一次指数平滑法进行预测,仍存在明显的滞后偏差,因此,必须加以修正。修正的方法与趋势移动平均法相同,即再作二次指数平滑,利用滞后偏差的规律建立直线趋势模型,这就是二次指数平滑法。
其数学表达为:
S t ( 1 ) = α y t + ( 1 − α ) S t − 1 ( 1 ) S t ( 2 ) = α S t ( 1 ) + ( 1 − α ) S t − 1 ( 2 ) (4) S_{t}^{(1)}=\alpha y_{t}+(1-\alpha)S_{t-1}^{(1)}\\ S_{t}^{(2)}=\alpha S_{t}^{(1)}+(1-\alpha)S_{t-1}^{(2)} \tag{4} St(1)=αyt+(1−α)St−1(1)St(2)=αSt(1)+(1−α)St−1(2)(4)
上式中, S t ( 1 ) S_{t}^{(1)} St(1)为一次指数平滑值, S t ( 2 ) S_{t}^{(2)} St(2)为二次指数平滑值。
当时间序列 y t {y_{t}} yt,某时期开始具有直线趋势时,可用直线趋势模型:
y ^ t + T = a t + b t T (5) \hat{y}_{t+T}= a_{t}+b_{t}T\tag{5} y^t+T=at+btT(5)
其中:
{ a t = 2 S t ( 1 ) − S t ( 2 ) b t = α 1 − α ( S t ( 1 ) − S t ( 2 ) ) (6) \left\{\begin{matrix} a_{t}=2S_{t}^{(1)}-S^{(2)}_{t}\\ b_{t}=\frac{\alpha}{1-\alpha}(S^{(1)}_{t}-S^{(2)}_{t}) \end{matrix}\right.\tag{6} {at=2St(1)−St(2)bt=1−αα(St(1)−St(2))(6)
-------------------------------------------------------------------------------------------------------------------------
举个例子:
仍以例 3 我国 1965~1985 年的发电总量资料为例,试用二次指数平滑法预 测 1986 年和 1987 年的发电总量:
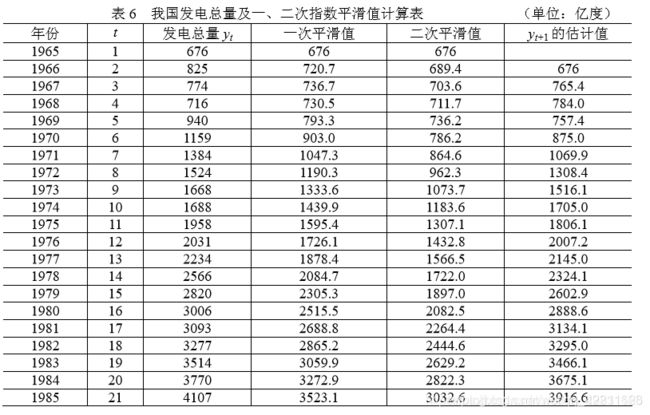

 为了求各期的模拟值,可将式(6)带入直线模型(5),并另T = 1,则得:
为了求各期的模拟值,可将式(6)带入直线模型(5),并另T = 1,则得:
y ^ t + 1 = ( 2 S t ( 1 ) − S t ( 2 ) ) + α 1 + α ( S t ( 1 ) − S t ( 2 ) ) (7) \hat{y}_{t+1}=(2S_{t}^{(1)}-S_{t}^{(2)})+\frac{\alpha}{1+\alpha}(S_{t}^{(1)}-S_{t}^{(2)})\tag{7} y^t+1=(2St(1)−St(2))+1+αα(St(1)−St(2))(7)
即:
y ^ t + 1 = ( 1 + 1 1 + α ) S t ( 1 ) − 1 1 − α S t ( 2 ) (8) \hat{y}_{t+1}=(1+\frac{1}{1+\alpha})S_{t}^{(1)}-\frac{1}{1-\alpha}S_{t}^{(2)}\tag{8} y^t+1=(1+1+α1)St(1)−1−α1St(2)(8)
3.3、三次平滑指数
前面说了,二次平滑是为了拟合直线趋势,三次平滑指数则是为了拟合二次曲线趋势。三次平滑指数是在二次平滑上在平滑一次。
数学表达:
{ S t ( 1 ) = α y t + ( 1 + α ) S t ( 1 ) S t ( 2 ) = α S t ( 1 ) + ( 1 + α ) S t − 1 ( 2 ) S t ( 3 ) = α S t ( 2 ) + ( 1 + α ) S t − 1 ( 3 ) (9) \left\{\begin{matrix} S_{t}^{(1)}=\alpha y_{t}+(1 +\alpha )S_{t}^{(1)}\\S_{t}^{(2)}=\alpha S_{t}^{(1)}+(1 +\alpha )S_{t-1}^{(2)}\\S_{t}^{(3)}=\alpha S_{t}^{(2)}+(1 +\alpha )S_{t-1}^{(3)} \end{matrix}\right.\tag{9} ⎩⎪⎨⎪⎧St(1)=αyt+(1+α)St(1)St(2)=αSt(1)+(1+α)St−1(2)St(3)=αSt(2)+(1+α)St−1(3)(9)
式中 S t ( 3 ) S_{t}^{(3)} St(3)为三次平滑值。
三次指数平滑法的预测模型为:
y ^ = a t + b t T + C t T 2 (10) \hat{y}=a_{t}+b_{t}T+C_{t}T^{2}\tag{10} y^=at+btT+CtT2(10)
其中:
{ a t = 3 S t ( 1 ) − 3 S t ( 2 ) + S t ( 3 ) b t = α 2 ( 1 + α ) [ ( 6 − 5 α ) S t ( 1 ) − 2 ( 5 − 4 α ) S t ( 2 ) + ( 4 − 3 α ) S t ( 3 ) ] c t = α 2 2 ( 1 − α ) 2 [ S t ( 1 ) − 2 S t ( 2 ) + S t ( 3 ) ] (11) \left\{\begin{matrix} a_{t}=3S_{t}^{(1)}-3S_{t}^{(2)}+S_{t}^{(3)}\\b_{t}=\frac{\alpha}{2(1+\alpha)}[(6-5\alpha)S_{t}^{(1)}-2(5-4\alpha)S_{t}^{(2)}+(4-3\alpha)S_{t}^{(3)}]\\c_{t}=\frac{\alpha ^{2}}{2(1-\alpha)^{2}}[S_{t}^{(1)}-2S_{t}^{(2)}+S_{t}^{(3)}] \end{matrix}\right.\tag{11} ⎩⎪⎨⎪⎧at=3St(1)−3St(2)+St(3)bt=2(1+α)α[(6−5α)St(1)−2(5−4α)St(2)+(4−3α)St(3)]ct=2(1−α)2α2[St(1)−2St(2)+St(3)](11)
----------------------------------------------------------------------------------------------------------------------
举例:
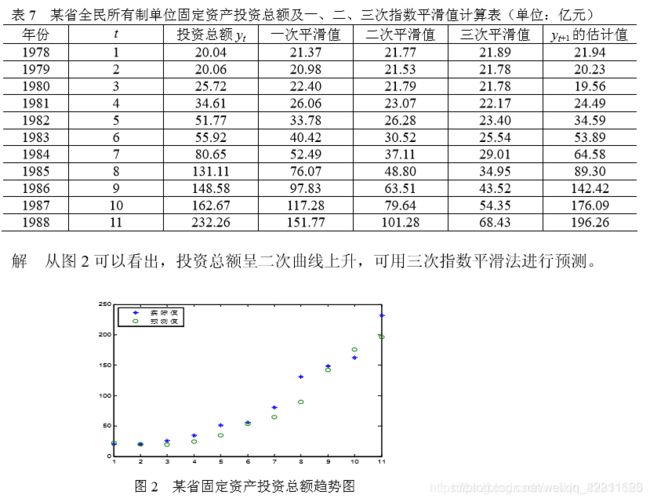
某省 1978~1988 年全民所有制单位固定资产投资总额如下表7所示,试预测 1989 年和 1990 年固定资产投资总额: