深度强化学习中深度Q网络(Q-Learning+CNN)的讲解以及在Atari游戏中的实战(超详细 附源码)
需要源码请点赞收藏关注后评论区留下QQ~~~
深度强化学习将深度学习的感知(预测能力)与强化学习的决策能力相结合,利用深度神经网络具有有效识别高维数据的能力,使得强化学习算法在处理高纬度状态空间任务中更加有效
一、DQN算法简介
1:核心思想
深度Q网络算法(DQN)是一种经典的基于值函数的深度强化学习算法,它将卷积神经网络与Q-Learning算法相结合,利用CNN对图像的强大表征能力,将视频帧视为强化学习中的状态输入网络,然后由网络输出离散的动作值函数,Agent再根据动作值函数选择对应的动作
DQN利用CNN输入原始图像数据,能够在不依赖于任意特定问题的情况下,采用相同的算法模型,在广泛的问题中获得较好的学习效果,常用于处理Atari游戏
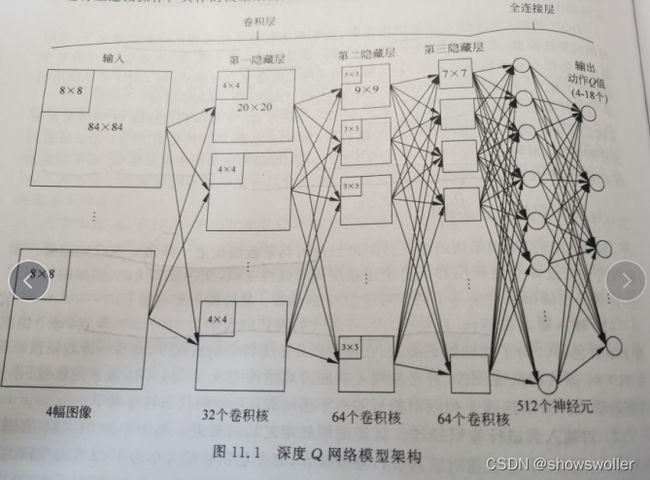
2:模型架构
深度Q网络模型架构的输入是距离当前时刻最近的连续4帧预处理后的图像,该输入信号经过3哥卷积层和2个全连接层的非线性变换,变换成低维的,抽象的特征表达,并最终在输出层产生每个动作对应的Q值函数
具体架构如下
1:输入层
2:对输入层进行卷积操作
3:对第一隐藏层的输出进行卷积操作
4:对第二隐藏层的输出进行卷积操作
5:第三隐藏层与第四隐藏层的全连接操作
6:第四隐藏层与输出层的全连接操作
3:数据预处理
包括以下几个部分
1:图像处理
2:动态信息预处理
3:游戏得分预处理
4:游戏随机开始的预处理
二、训练算法
DQN之所以能够较好的将深度学习与强化学习相结合,是因为它引入了三个核心技术
1:目标函数
使用卷积神经网络结合全连接作为动作值函数的逼近器,实现端到端的效果,输入为视频画面,输出为有限数量的动作值函数
2:目标网络
设置目标网络来单独处理TD误差 使得目标值相对稳定
3:经验回放机制
有效解决数据间的相关性和非静态问题,使得网络输入的信息满足独立同分布的条件
DQN训练流程图如下
三、DQN算法优缺点
DQN算法的优点在于:算法通用性强,是一种端到端的处理方式,可为监督学习产生大量的样本。其缺点在于:无法应用于连续动作控制,只能处理具有短时记忆的问题,无法处理需长时记忆的问题,且算法不一定收敛,需要仔细调参
四、DQN在Breakout、Asterix游戏中的实战
接下来通过Atari 2600游戏任务中的Breakout,Asterix游戏来验证DQN算法的性能。
在训练过程中 Agent实行贪心策略,开始值为1并与环境进行交互,并将交互的样本经验保存在经验池中,点对于每个Atari游戏,DQN算法训练1000000时间步,每经历10000时间步,Agent将行为网络的参数复杂到目标网络,每经历1000时间步,模型进行一次策略性能评估
可视化如下

训练阶段的实验数据如下
可以看出 有固定目标值的Q网络可以提高训练的稳定性和收敛性

loss变化如下

五、代码
部分代码如下
import gym, random, pickle, os.path, math, glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy
numpy.random.bit_generator = numpy.random.bit_generator
import torch
im=
from atari_wrappers import make_atari, wrap_deepmind, LazyFrames
from IPython.display import clear_output
from tensorboardX import SummaryWriter
from gym import envs
env_names = [spec for spec in envs.registry]
for name in sorted(env_names):
print(name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class DQN(nn.Module):
def __init__(self, in_channels=4, num_actions=5):
= nn.Conv2d(32, 64, kernel_size=4, stride=2)
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
self.fc4 = nn.Linear(7 * 7 * 64, 512)
self.fc5 = nn.Linear(512, num_actions)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.fc4(x.view(x.size(0), -1))) # 输出的维度是为[x.size(0),1]
return self.fc5(x)
class Memory_Buffer(object):
def __init__(self, memory_size=1000):
self.buffer = []
self.memory_size = memory_size
self.next_idx = 0
def push(self, state, action, reward, next_state, done):
data = (state, action, reward, next_state, done)
if len(self.buffer) <= self.memory_size: # buffer not full
self.buffer.append(data)
else: # buffer is full
self.buffer[self.next_idx] = data
self.=s, rewards, next_states, dones = [], [], [], [], []
for i in range(batch_size):
idx = random.randint(0, self.size() - 1)
data = self.buffer[idx]
state, action, reward, next_state, done = data
states.append(state)
actions.append(action)
rewards.append(reward)
next_states.append(next_state)
dones.append(done)
return np.concatenate(states), actions, rewards, np.concatenate(next_states), dones
def size(self):
return len(self.buffer)
class DQNAgent:
def __init__(self, in_channels=1, action_space=[], USE_CUDA=False, memory_size=10000, epsilon=1, lr=1e-4):
self.epsilo=ction_space
self.memory_buffer = Memory_Buffer(memory_size)
self.DQN = DQN(in_channels=in_channels, num_actions=action_space.n)
self.DQN_target = DQN(in_channels=in_channels, num_actions=action_space.n)
self.DQN_target.load_state_dict(self.DQN.state_dict())
self.USE_CUDA = USE_CUDA
if USE_CUDA:
self.DQN = self.DQN.to(device)
self.DQN_target = self.DQN_target.to(device)
self.optimizer = optim.RMSprop(self.DQN.parameters(), lr=lr, eps=0.001, alpha=0.95)
def observe(self, lazyframe):
# from Lazy frame to tensor
state = torch.from_numpy(lazyframe._force().transpose(2, 0, 1)[None] / 255).float()
if self.USE_CUDA:
state = state.to(device)
return state
def value(self, state):
q_values = self.DQN(state)
return q_values
def act(self, state, epsilon=None):
"""
sample actions with epsilon-greedy policy
recap: with p = epsilon pick random action, else pick action with highest Q(s,a)
"""
if epsilon is None:
epsilon = self.epsilon
q_values = self.value(state).cpu().detach().numpy()
if random.random() < epsilon:
aciton = random.randrange(self.action_space.n)
else:
aciton = q_values.argmax(1)[0]
return aciton
def compute_td_loss(self, states, actions, rewards, next_states, is_done, gamma=0=tensor(actions).long() # shape: [batch_size]
rewards = torch.tensor(rewards, dtype=torch.float) # shape: [batch_size]
is_done = torch.tensor(is_done, dtype=torch.uint8) # shape: [batch_size]
if self.USE_CUDA:
actions = actions.to(device)
rewards = rewards.to(device)
is_done = is_done.to(device)
# get q-values for all actions in current states
predicted_qvalues = self.DQN(states) # [32,action]
# print("predicted_qvalues:",predicted_qvalues)
# input()
# select q-values for chosen actions
predicted_qvalues_for_actions = predicted_qvalues[range(states.shape[0]), actions]
# print("predicted_qvalues_for_actions:",predicted_qvalues_for_actions)
# input()
# compute q-values for all actions in next states
predicted_next_qvalues = self.DQN_target(next_states)
# compute V*(next_states) using predicted next q-values
next_state_values = predicted_next_qvalues.max(-1)[0]
# compute "target q-values" for loss - it's what's inside square parentheses in the above formula.
target_qvalues_for_actions = rewards + gamma * next_state_values
# at the last state we shall use simplified formula: Q(s,a) = r(s,a) since s' doesn't exist
target_qvalues_for_actions = torch.where(is_done, rewards, target_qvalues_for_actions)
# mean squared error loss to minimize
# loss = torch.mean((predicted_qvalues_for_actions -
# target_qvalues_for_actions.detach()) ** 2)
loss = F.smooth_l1_loss(predicted_qvalues_for_actions, target_qvalues_for_actions.detach())
return loss
def sample_from_buffer(self, batch_size):
states, actions, rewards, next_states, dones = [], [], [], [], []
for i in range(batch_size):
idx = random.randint(0, self.memory_buffer.size() - 1)
data = self.memory_buffer.buffer[idx]
frame, action, reward, next_frame, done = data
states.append(self.observe(frame))
actions.append(action)
rewards.append(reward)
next_states.append(self.observe(next_frame))
dones.append(done)
return torch.cat(states), actions, rewards, torch.cat(next_states), dones
def learn_from_experience(self, batch_size):
if self.memory_buffer.size() > batch_size:
states, actions, rewards, next_states, dones = self.sample_from_buffer(batch_size)
td_loss = self.compute_td_loss(states, actions, rewards, next_states, dones)
self.optimizer.zero_grad()
td_loss.backward()
for param in self.DQN.parameters():
param.grad.data.clamp_(-1, 1) # 梯度截断,防止梯度爆炸
self.optimizer.step()
return (td_loss.item())
else:
return (0)
def plot_training(frame_idx, rewards, losses):
pd.DataFrame(rewards, columns=['Reward']).to_csv(idname, index=False)
clear_output(True)
plt.figure(figsize=(20, 5))
plt.subplot(131)
plt.title('frame %s. reward: %s' % (frame_idx, np.mean(rewards[-10:])))
plt.plot(rewards)
plt.subplot(132)
plt.title('loss')
plt.plot(losses)
plt.show()
# Training DQN in PongNoFrameskip-v4
idname = 'PongNoFrameskip-v4'
env = make_atari(idname)
env = wrap_deepmind(env, scale=False, frame_stack=True)
#state = env.reset()
#print(state.count())
gamma = 0.99
epsilon_max = 1
epsilon_min = 0.01
eps_decay = 30000
frames = 2000000
USE_CUDA = True
learning_rate = 2e-4
max_buff = 100000
update_tar_interval = 1000
batch_size = 32
print_interval = 1000
log_interval = 1000
learning_start = 10000
win_reward = 18 # Pong-v4
win_break = True
action_space = env.action_space
action_dim = env.action_space.n
state_dim = env.observation_space.shape[0]
state_channel = env.observation_space.shape[2]
agent = DQNAgent(in_channels=state_channel, action_space=action_space, USE_CUDA=USE_CUDA, lr=learning_rate)
#frame = env.reset()
episode_reward = 0
all_rewards = []
losses = []
episode_num = 0
is_win = False
# tensorboard
summary_writer = SummaryWriter(log_dir="DQN_stackframe", comment="good_makeatari")
# e-greedy decay
epsilon_by_frame = lambda frame_idx: epsilon_min + (epsilon_max - epsilon_min) * math.exp(-1. * frame_idx / eps_decay)
plt.plot([epsilon_by_frame(i) for i in range(10000)])
for i in range(frames):
epsilon = epsilon_by_frame(i)
#state_tensor = agent.observe(frames)
#action = agent.act(state_tensor, epsilon)
#next_frame, reward, done, _ = env.step(action)
#episode_reward += reward
#agent.memory_buffer.push(frame, action, reward, next_frame, done)
#frame = next_frame
loss = 0
if agent.memory_buffer.size() >= learning_start:
loss = agent.learn_from_experience(batch_size)
losses.append(loss)
if i % print_interval == 0:
print("frames: %5d, reward: %5f, loss: %4f, epsilon: %5f, episode: %4d" %
(i, np.mean(all_rewards[-10:]), loss, epsilon, episode_num))
summary_writer.add_scalar("Temporal Difference Loss", loss, i)
summary_writer.add_scalar("Mean Reward", np.mean(all_rewards[-10:]), i)
summary_writer.add_scalar("Epsilon", epsilon, i)
if i % update_tar_interval == 0:
agent.DQN_target.load_state_dict(agent.DQN.state_dict())
'''
if done:
frame = env.reset()
all_rewards.append(episode_reward)
episode_reward = 0
episode_num += 1
avg_reward = float(np.mean(all_rewards[-100:]))
'''
summary_writer.close()
# 保存网络参数
#torch.save(agent.DQN.state_dict(), "trained model/DQN_dict.pth.tar")
plot_training(i, all_r=
创作不易 觉得有帮助请点赞关注收藏~~~