MNIST 数据集分类
构建简单的CNN对 mnist 数据集进行分类。同时,还会在实验中学习池化与卷积操作的基本作用。
1. 引入库文件
mport torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy
# 一个函数,用来计算模型中有多少参数
def get_n_params(model):
np=0
for p in list(model.parameters()):
np += p.nelement()
return np
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
2. 加载数据
PyTorch里包含了 MNIST, CIFAR10 等常用数据集,调用 torchvision.datasets 即可把这些数据由远程下载到本地,下面给出MNIST的使用方法:
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
- root 为数据集下载到本地后的根目录,包括 training.pt 和 test.pt 文件
- train,如果设置为True,从training.pt创建数据集就是为训练集,否则从test.pt创建即测试集。
- download,如果设置为True, 从互联网下载数据并放到root文件夹下
- transform, 一种函数或变换,输入PIL图片,返回变换之后的数据。
- target_transform 一种函数或变换,输入目标,进行变换。
配合DataLoader进行使用
loader_data=DataLoader(test_set,batch_size=64,shuffle=True,drop_last=True)
- 首先传入一个dataset数据类型的数据
- batch_size:可以理解为一副牌,每个人手里拿几张牌
- shuffle:是否每次随机抓取,就是是否重新洗牌
- drop_last:总共的dataset的数量除以batch_size的余数是否保留
- num_workers:加载数据的时候使用几个子进程
input_size = 28*28 # MNIST上的图像尺寸是 28x28
output_size = 10 # 类别为 0 到 9 的数字,因此为十类
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1000, shuffle=True)
2.1 查看数据
除了使用老师提供的plt,还可以使用tensorboard展示
#显示数据集中的部分图像
#除了老师使用的plt还可以使用SummaryWriter
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter('logs')#日志文件的存放地址
step=0
for data in train_loader:
img,target=data
writer.add_images('train_loader',img,step)
step=step+1
%load_ext tensorboard
%tensorboard --logdir logs
writer.close()
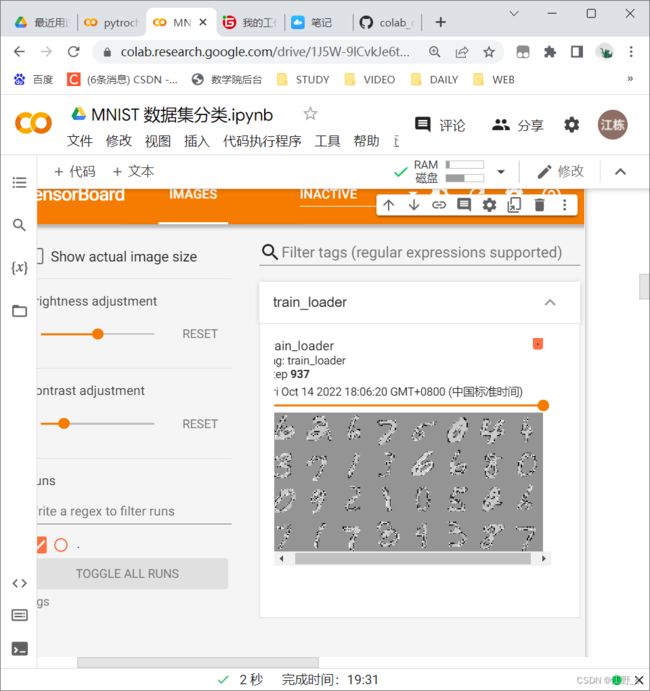
这里的图像呈现灰色,是因为前面做了标准化处理transforms.Normalize
3. 创建网络
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数init中。
注:这两个方法必须重写!
只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
# 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字
# 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64
# 大家可以加一行代码:print(x.cpu().numpy().shape)
# 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的
# forward 函数的作用是,指定网络的运行过程,这个全连接网络可能看不啥意义,
# 下面的CNN网络可以看出 forward 的作用。
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数,所有的网络都要这么写
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
3.2 定义训练和测试函数
# 训练函数
def train(model):
model.train()
# 主里从train_loader里,64个样本一个batch为单位提取样本进行训练
for batch_idx, (data, target) in enumerate(train_loader):
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
# 把数据送入模型,得到预测结果
output = model(data)
# 计算本次batch的损失,并加到 test_loss 中
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability,最后一层输出10个数,
# 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里
pred = output.data.max(1, keepdim=True)[1]
# 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中
# 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
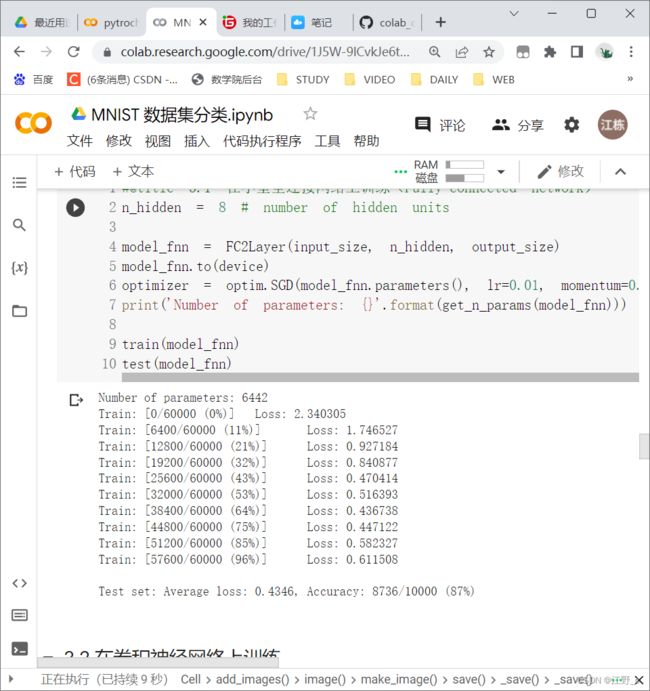
4.1 在小型全连接网络上训练(Fully-connected network)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train(model_fnn)
test(model_fnn)
运行结果
4.2 在卷积神经网络上训练
#@title 3.2 在卷积神经网络上训练
# Training settings
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train(model_cnn)
test(model_cnn)
运行结果
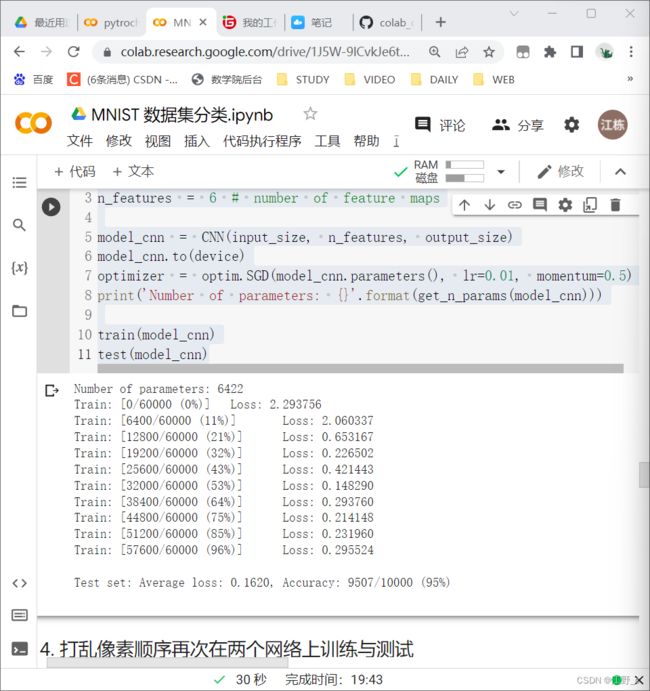
通过上面的测试结果,可以发现,含有相同参数的 CNN 效果要明显优于 简单的全连接网络,是因为 CNN 能够更好的挖掘图像中的信息,主要通过两个手段:
- 卷积:Locality and stationarity in images
- 池化:Builds in some translation invariance
5. 打乱像素顺序再次在两个网络上训练与测试
5.1 图像的形态
考虑到CNN在卷积与池化上的优良特性,如果我们把图像中的像素打乱顺序,这样 卷积 和 池化 就难以发挥作用了,为了验证这个想法,我们把图像中的像素打乱顺序再试试。
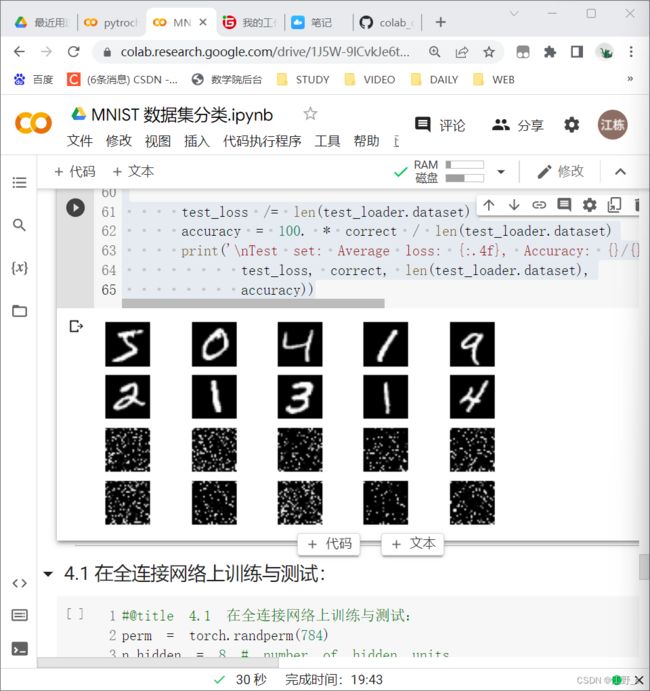
首先下面代码展示随机打乱像素顺序后,图像的形态:
#@title 4. 打乱像素顺序再次在两个网络上训练与测试
# 这里解释一下 torch.randperm 函数,给定参数n,返回一个从0到n-1的随机整数排列
perm = torch.randperm(784)
plt.figure(figsize=(8, 4))
for i in range(10):
image, _ = train_loader.dataset.__getitem__(i)
# permute pixels
image_perm = image.view(-1, 28*28).clone()
image_perm = image_perm[:, perm]
image_perm = image_perm.view(-1, 1, 28, 28)
plt.subplot(4, 5, i + 1)
plt.imshow(image.squeeze().numpy(), 'gray')
plt.axis('off')
plt.subplot(4, 5, i + 11)
plt.imshow(image_perm.squeeze().numpy(), 'gray')
plt.axis('off')
# 对每个 batch 里的数据,打乱像素顺序的函数
def perm_pixel(data, perm):
# 转化为二维矩阵
data_new = data.view(-1, 28*28)
# 打乱像素顺序
data_new = data_new[:, perm]
# 恢复为原来4维的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
# 训练函数
def train_perm(model, perm):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试函数
def test_perm(model, perm):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
重新定义训练与测试函数,我们写了两个函数 train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。
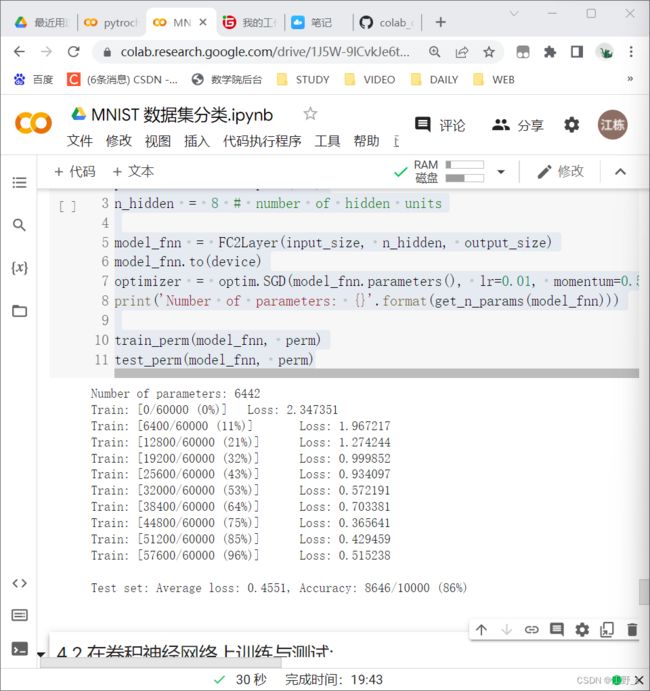
5.2 在全连接网络上训练与测试:
#@title 4.1 在全连接网络上训练与测试:
perm = torch.randperm(784)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train_perm(model_fnn, perm)
test_perm(model_fnn, perm)
5.3 在卷积神经网络上训练与测试:
#@title 4.2 在卷积神经网络上训练与测试:
perm = torch.randperm(784)
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train_perm(model_cnn, perm)
test_perm(model_cnn, perm)
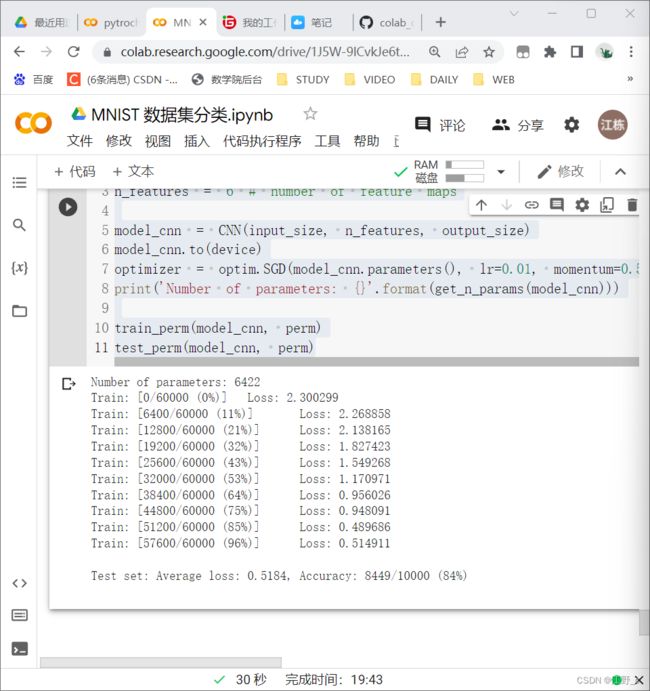
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
关于实验中的一些问题
- dataloader 里面 shuffle 取不同值有什么区别
当shuffle取True时就是每次取为乱序
取False就不会重新随机排序
- transform 里,取了不同值,这个有什么区别?
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
首先理解transform是对数据进行一些预处理的操作
1. Compose为一个流水线操作,就是依次执行数组里的操作
2. ToTensor将数据转为tensor数据类型
3. Normalize进行归一化处理,这就是为什么查看图片会是灰色的
- epoch 和 batch 的区别?
- Epoch:所有训练样本在神经网络中都进行了一次正向传播和一次反向传播。也就是1个epoch等于使用训练集中的全部样本训练一次。
- Batch:将整个训练样本分成若干个Batch。
- 1x1的卷积和 FC 有什么区别?主要起什么作用?
- 1x1的卷积是针对矩阵的卷积操作,1x1卷积不改变宽度和高度,只改变channel数,主要作用是升维、降维以及提升网络的非线性;
- FC是针对神经元的操作。FC的作用主要是将局部特征进行整合,并得到分类标签。