【机器学习】逻辑回归之心脏病预测
目录
一、分析数据
它有三个部分:
一些可视化处理
散点图:以心率和年龄为例
二、 处理数据
文本型变量应当转换成0、1数据格式
代码如下
三、构建特征集和标签集
1、代码如下
2、输出如下:
3、拆分训练集和验证集,打乱顺序
四、训练模型
五、开始预测
六、评价
一、分析数据
from IPython.core.display_functions import display
import numpy as np
import pandas as pd
df_heart = pd.read_csv("./heart.csv") # 读取文件
display(df_heart)
# df.head() # 显示前5行数据
df_heart.tail() #显示后五行它有三个部分:
data部分:303条数据
最后一列为标签
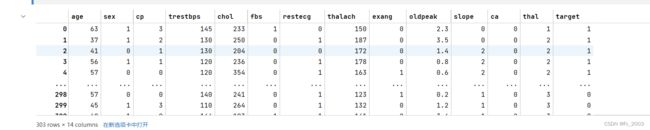
target部分: 303条 0代表无心脏病,1代表有心脏病
表头部分: 13个属性(特征)-影响心脏病的因素
'''
cp:胸痛类型
trestbps:休息时血压
chol:胆固醇
fbs:血糖
restecg:心电图
thalach:最大心率
exang:运动后心绞痛
oldpeak:运动后ST段压低
slope:运动高峰期ST段的斜率
ca:主动脉荧光造影染色数
thal:缺陷种类
target:0代表无心脏病,1代表有心脏病
'''
统计其中有多少个有心脏病:
# df_heart.sex.value_counts()
num=df_heart.target.value_counts()
print(num[0]) # 输出类别数目(0/1)
num输出如下:

可见138人没有心脏病,165人有
一些可视化处理
散点图:以心率和年龄为例
from matplotlib import pyplot as plt
#thalach:最大心率
#散点图
plt.scatter(x=df_heart.age[df_heart.target == 1],
y=df_heart.thalach[(df_heart.target == 1)], c="red")
plt.scatter(x=df_heart.age[df_heart.target == 0],
y=df_heart.thalach[(df_heart.target == 0)])
plt.legend(["Disease", "No Disease"]) # 显示图例
plt.xlabel("Age") # X轴:年龄
plt.ylabel("Thalach") # Y轴:最大心率
plt.show()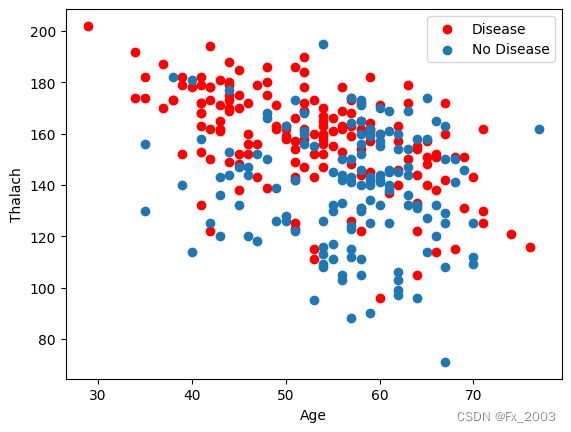
二、 处理数据
文本型变量应当转换成0、1数据格式
例如性别,取值为0、1,对于男女
数据集中有三个需要处理的文本型变量----转换成哑变量
这些文本型变量,比如cp,它们的取值是0、1、2、3,但是这个值的大小是没有比较意义的,但是计算机会把它们理解为数值,所以我们需要转换为哑变量 转换成0、1数据格式
代码如下:
# 把3个文本型变量转换为哑变量
#get_dummies
a = pd.get_dummies(df_heart['cp'], prefix="cp")
b = pd.get_dummies(df_heart['thal'], prefix="thal")
c = pd.get_dummies(df_heart['slope'], prefix="slope")
#drop
df_heart = df_heart.drop(columns=['cp', 'thal', 'slope']) #去掉这三列
# 添加哑变量
#拼接列表
df_heart = pd.concat([df_heart, a, b, c], axis=1)
df_heart.head() # 显示新的dataframe输出如下:
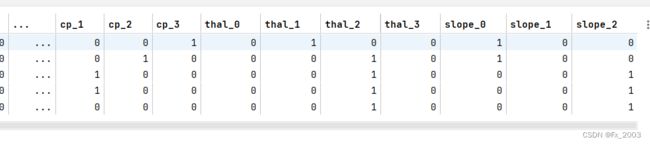
其中:
concat 用来拼接或合并数据,其根据不同的轴既可以横向拼接,又可以纵向拼接
它有两个常用参数:
- objs:合并的数据集,一般用列表传入,例如:[df1,df2,df3]
- axis:指定数据拼接时的轴,0是行、1是列
get_dummies:其实相当与独热编码
参考博客:特征提取之pd.get_dummies()用法_那记忆微凉的博客-CSDN博客_pd.get_dummies
比如上面的 cp:胸痛类型 有四个取值:0、1、2、3
那么就变成了四列:cp_0、cp_1。。。。
每一列都是取值0或1
三、构建特征集和标签集
1、代码如下
X = df_heart.drop(['target'], axis=1) # 特征集
y = df_heart.target.values # 标签集
y = y.reshape(-1, 1) # -1是相对索引,等价于len(y)
print("张量X的形状:", X.shape)
print("张量y的形状:", y.shape)
# X
y2、输出如下:
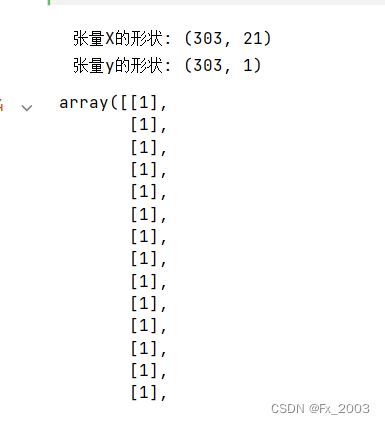
这个reshape可以用来转换这个行列,
比如3x4的数据我,reshape(12,1),就变成了12行的列向量
3、拆分训练集和验证集,打乱顺序
用sklearn的拆分工具
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_train
可以看到,已经打乱顺序,
至于为什么是212行?
因为我X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
test_size=0.3 说明验证集占比30%,而303*0.7=212.1,取整212
四、训练模型
from sklearn.linear_model import LogisticRegression #导入逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train) # 拟合
print("测试准确率{:.2f}%".format(lr.score(X_test, y_test) * 100))
display(lr.coef_,lr.intercept_)model.coef_:斜率 正值说明正相关,负值说明负相关model.intercept_:截距(用的默认的----fit_intercept=True)
输出:

五、开始预测
y_predict = lr.predict(X_test)
print(len(y_predict))
y_predict输出为 :(91=303-212)

六、评价
print("测试准确率{:.2f}%".format(lr.score(X_test, y_test) * 100))输出如下:
