Supermap机器学习功能实操
AI GIS
官方参考文档:https://help.supermap.com/iDesktopX/zh/tools/MachineLearning/AboutMachineLearning
1. 简介
1.1 机器学习主要功能
- 影像分析
- 训练数据生成
- 模型训练
- 目标检测
- 二元分类
- 地物分类
- 场景分类
- 对象提取
- 通用变化检测
- 模型评估
- 图片分析
- 模型训练
- 图片分类
- 目标检测
- 视频分析
- 模型训练
- 元胞自动机
- 人工神经网络训练
- 基于人工神经网络的元胞自动机
- 主成分分析训练
- 基于主成分分析的元胞自动机
2. 环境搭建
2.1 系统 配置说明
- CPU运行环境最低配置:
- 处理器 :四核 3.7 GHz主频
- 内存要求 :主机内存不低于 8G, 总内存(物理内存及虚拟内存的总和) 不低于 16G
- CPU运行环境最低配置:
- NVIDIA显卡
- 显存≥10G,最低要求为8G
- 最新的显卡驱动
2.2 配置python环境
Python扩展包下载
配置环境变量前请先从官网下载SuperMap iObjects Python Environments 11i(2022)(win64 GPU)、SuperMap iObjects Python Environments 11i(2022)(win64 CPU)和SuperMap iObjects Python Machine Learning Resources 11i(2022)
环境变量配置
1.将SuperMap iObjects Python Machine Learning Resources 11i(2022)“解压到当前文件夹”,将resources_ml解压到SuperMap iDesktopX的根目录下,解压后如下图所示:

2.打开iDesktopX,点击“开始-Python”,点击Python窗口左下角设置按钮,设置环境变量
注:SuperMap iObjects Python Environments 11i(2022)(win64 GPU)是基于GPU资源的分析环境,显卡要求:NAVID显卡,显存≥10G,最低要求为8G最新的显卡驱动。SuperMap iObjects Python Environments 11i(2022)(win64 CPU)是基于CPU资源的分析环境,主机内存不低于 8G, 总内存(物理内存及虚拟内存的总和) 不低于 16G;处理器要求四核 3.7 GHz主频。
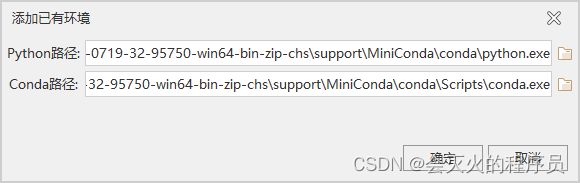
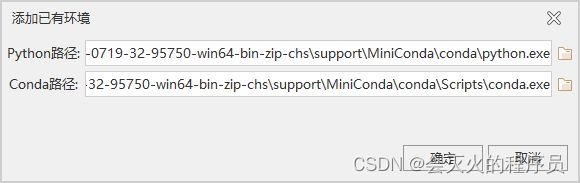
测试环境GPU只有6G显存,所以使用SuperMap iObjects Python Environments 11i(2022)(win64 CPU)包,将环境包解压到任意目录下(注意不要有中文),然后在iDesktop中点击添加已有变量,选择Python路径supermap-iobjectspy-env-cpu-11.0.0-20220628-win64\conda\python.exe后,Conda路径会自动带入,如下图:
配置完环境变量后重启Python环境。
3. 影像分析
从遥感影像中对指定地物进行识别,并进行空间统计和分析,以从影像中获取兴趣目标的信息,应用场景:
- 遥感影像中的目标检测、土地利用数据的自动化识别与分类
- 利用城市卫星图像结合土地利用,预测城市扩张;
- 通过影像自动更新 POI 等空间数据;
3.1 训练数据生成
样本影像
目标区域的影像数据,建议使用分辨率较高的航空影像片和卫星影像片。支持文件型影像,如tif、img、存储在udbx、数据库中的原始影像等格式。
样本标签
矢量面数据集,面对象为影像数据中对象目标的外廓多边形对象,及相关的属性信息,例如二元分类(房屋),标注信息需要标识是否是房屋、房屋的像素坐标等信息。如以下是房屋的样本标签数据:

训练数据用途
不同的训练数据用途使用的算法不同,根据用户用途而设定,提供了目标检测、二元分类、地物分类、场景分类、对象提取五种用途。
类别字段
设置标签数据中标识地物类型的字段,如房屋标识字段类型为“房屋”。
- 目标检测:矢量标签中含有记录检测对象类别的字段,可加入类别字段中作为参考,若只有一类目标物可设置为空值。
- 二元分类:可设置为空值。
- 地物分类:需选择含有矢量标签的类别字段。
- 场景分类:需选择含有矢量标签的类别字段。
输出路径
设置结果数据的输出路径,及结果数据的文件夹名称。结果数据包括影像数据和标签数据切分的图像,及数据的配置文件(*.sda)。 注意: 输出路径不能带中文字符。
3.2 模型训练

训练数据路径
选择通过训练数据生成工具的结果文件夹,即3.1的输出结果
训练模型用途
选择使用模型的功能,提供了目标检测、二元分类、地物分类、场景分类四种用途。
训练配置文件
选择训练数据结果中的配置文件。
注: 这里会根据模型算法系统自行选择的,不能自己选择。
训练次数
所有训练数据参与模型训练的次数(epoch),随着训练次数的增多,模型拟合度越大,次数太多可能会出现过拟合的情况。默认值为 10,用户可根据需求选择,一般训练次数为 10-20 次,训练次数与运行花费时间成正比。
单步运算量
一次训练中单步运算的图片数量(Batch Size)。多个图片组成的一份训练数据称之为一个 Batch,每个 Batch 所含的图片数量称为 Batch Size。在合理范围内,单步运算的数量与内存(显存)占用成正比,与训练时间成反比。默认值为 1,用户根据运行环境选择。
学习率
模型参数的更新幅度(learning rate)。一般情况下,学习率需要根据经验设置,设置一个相对合适的值。学习率过大,会导致待优化参数在最小值附近进行波动;学习率过小,会导致待优化参数收敛的速度慢。默认值为 0.0001,目标检测一般为 0.001,二元分类一般为 0.0001。
训练日志路径
用于设置训练日志存储路径,该路径下会生成多个文件夹,建议首次训练选择一个空文件夹。
加载预训练模型
若勾选该选项,可选择前一次训练的训练日志路径作为预训练模型的路径,会在前一次的基础上进行训练。
注意 :前后两次训练需要训练数据的尺寸、类别和用途相同。
结果数据
设置模型存储路径及模型名称。
训练z日志
# 下面是地物分类训练过程中的日志
PyDev console: starting.
Python 3.7.11 (default, Jul 27 2021, 09:42:29) [MSC v.1916 64 bit (AMD64)]
[iObjectsPy]: The Gateway service started successfully
Training Data is inited!
D:\SuperMap\idesktop\supermap-idesktopx-11.0.0-0719-32-95750-win64-bin-zip-chs\bin_python\iobjectspy\iobjectspy-py37_64\iobjectspy\ml\vision\_models\semantic_seg\_torch_models\geo_api\train_api.py:253: UserWarning: encoder_weights is None, and the data is preprocessed using ImageNet weights
# Epoch 1/10 表示开始第一次训练
Epoch: 1/10
train: 0%| | 0/83 [00:00<?, ?it/s]D:\SuperMap\idesktop\AIForGis\supermap-iobjectspy-env-cpu-11.0.0-20220628-win64\conda\lib\site-packages\rasterio\__init__.py:215: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix be returned.
s = DatasetReader(path, driver=driver, sharing=sharing, **kwargs)
train: 0%| | 0/83 [00:03<?, ?it/s, lr - 0.0001, cross_entropy_loss - 2.053, iou_score - 0.01196, f1_score - 0.02232]
train: 1%| | 1/83 [00:03<04:20, 3.18s/it, lr - 0.0001, cross_entropy_loss - 2.053, iou_score - 0.01196, f1_score - 0.02232]
# ...省略部分...
train: 99%|█████████▉| 82/83 [04:04<00:02, 2.90s/it, lr - 0.0001, cross_entropy_loss - 0.7748, iou_score - 0.1305, f1_score - 0.2037]
train: 100%|██████████| 83/83 [04:04<00:00, 2.90s/it, lr - 0.0001, cross_entropy_loss - 0.7748, iou_score - 0.1305, f1_score - 0.2037]
train: 100%|██████████| 83/83 [04:04<00:00, 2.95s/it, lr - 0.0001, cross_entropy_loss - 0.7748, iou_score - 0.1305, f1_score - 0.2037]
valid: 0%| | 0/27 [00:00<?, ?it/s]
valid: 0%| | 0/27 [00:00<?, ?it/s, cross_entropy_loss - 0.8091, iou_score - 0.1675, f1_score - 0.2175]
# ...省略部分...
valid: 96%|█████████▋| 26/27 [00:25<00:00, 1.07it/s, cross_entropy_loss - 0.7466, iou_score - 0.2482, f1_score - 0.3406]
valid: 100%|██████████| 27/27 [00:25<00:00, 1.07it/s, cross_entropy_loss - 0.7466, iou_score - 0.2482, f1_score - 0.3406]
valid: 100%|██████████| 27/27 [00:25<00:00, 1.07it/s, cross_entropy_loss - 0.7466, iou_score - 0.2482, f1_score - 0.3406]
Model saved!
# 第一次训练模型结束
Epoch: 2/10
train: 0%| | 0/83 [00:00<?, ?it/s]
train: 0%| | 0/83 [00:02<?, ?it/s, lr - 9e-05, cross_entropy_loss - 1.13, iou_score - 0.0826, f1_score - 0.1231]
train: 1%| | 1/83 [00:02<03:52, 2.83s/it, lr - 9e-05, cross_entropy_loss - 1.13,
3.3 目标检测
目标检测的目的是基于神经网络模型,对遥感图像中多个目标物的类别和位置进行自动化判定与识别,并以矢量矩形框的形式把目标物标记出来,用于后期的空间统计及分析。目标检测与传统方法相比,有着速度快、准确率较高等特点,通常用来快速确定影像中不同类别目标的数量和位置等空间信息。
数据源/数据集
选择需要进行目标检测的影像或栅格数据。支持文件型影像,如tif、img、存储在udbx、数据库中的原始影像等格式。
模型文件
选择一个目标检测的模型文件(*.sdm)。
概率阈值
对每一个检测出来的对象,系统都会为其计算出符合目标特征的概率,最后检测结果仅保留预测概率高于该值的目标,默认值为 0.5。
其他参数设置:
勾选该复选框即可设置以下去重阈值参数。
去重阈值
系统对一张图片里的检测对象生成多个候选框,并分别给出概率值,带入 NMS 算法后得到最优框,根据交并比(IoU)去除与最优框重叠部分大于去重阈值的候选框。去重阈值一般为 0.3~0.7,默认值为 0.3。
结果数据
即图像中目标物的标识面数据集,设置结果数据集所保存的数据源和保存名称。
3.4 二元分类
二元分类利用遥感图像中各类地物光谱信息和空间信息,通过深度学习算法对遥感图像中的某一类地物要素进行分类,并判定影像的像元是否为兴趣类别,并生成值为 0、1 的二值栅格数据,0 为非兴趣类别,1 为兴趣类别。
二元分类功能在像元级别细粒度解译影像,栅格结果灵活性较高,可以通过后一系列后处理步骤优化分类结果,可将结果的栅格数据转化成矢量数据,进行进一步的分析。
二元分类通常用来获得道路、河流和建筑物等特点明显的单一地类,可以通过像元计算兴趣类别的位置、边界和面积等信息。
数据源/数据集
选择需要进行分类的影像或栅格数据。
模型文件
选择二元分类的模型文件(*.sdm)。
切片重叠(像元)
在二元分类过程中,由于卷积神经网络的结构特征,会导致切片边缘的数据预测不充分,为使了提高预测质量,需要将切片重叠。此参数以像元为单位,一般为兴趣类别平均大小的 2~3 倍。
结果数据
即二元分类的结果栅格数据集,设置结果数据集保存的数据源和保存名称。
3.5 地物分类
对影像进行地物分类,即利用遥感图像中各类地物光谱信息和空间信息进行分析,将图像中具有语义信息的各个像元分别赋予语义类别标签,实现地物分类,包括:建筑物、林地、草地、水田、农用地等。类比于二元分类,地物分类是通过神经网络模型判断影像中的每个像元属于兴趣类别中的哪一类,用于多类地物判断,通过像元计算兴趣类别的位置、边界和面积等信息。
数据源/数据集
选择需要进行分类的影像或栅格数据。
模型文件
选择地物分类的模型文件(*.sdm)。
切片重叠(像元)
在地物分类过程中,由于卷积神经网络的结构特征,会导致切片边缘的数据预测不充分,为使了提高预测质量,需要将切片重叠。此参数以像元为单位,一般为兴趣类别平均大小的 2~3 倍。
结果数据
即地物分类的结果栅格数据集,设置结果数据集保存的数据源和保存名称。
3.5 场景分类
场景分类是根据一定的地物特征对影像数据进行分类,区分出具有相似特征的区域,为每一幅图像赋予场景标签,所以场景分类的关键就在于对图像特征的提取。
场景分类结果为大小均匀(32*32像元)的矢量网格,每个网格带有其对应位置影像的场景标签,是一种高于像元级别的粗粒度分类方法。场景分类一般用于较大尺度的分类任务,如城市局部气候区分类等。
数据源/数据集
选择需要进行场景分类的影像或栅格数据。
模型文件
选择场景分类的模型文件(*.sdm)。
结果数据
即场景分类的结果面数据集,设置结果数据集保存的数据源和保存名称。
3.6 对象提取
对象提取基于神经网络模型预选出兴趣类别在影像中的区域,然后对区域内像素分57类,进而获得对象的边界信息,以便于支持对象级别的空间分析。
数据源/数据集
选择需要进行对象提取的数据。
模型文件
选择用于提取对象的模型文件(*.sdm)。
概率阈值
对每一个提取出来的对象,系统都会为其计算出符合对象特征的概率,最后提取结果仅保留预测概率高于该值的对象,默认值为 0.5。
其他参数设置
勾选该复选框即可设置以下去重阈值参数。
去重阈值
系统对一张图片里的检测对象生成多个候选框,并分别给出概率值,带入 NMS 算法后得到最优框,根据交并比(IoU)去除与最优框重叠部分大于去重阈值的候选框。去重阈值一般为 0.3~0.7,默认值为 0.3。
返回最小外接矩形
若勾选则生成一份结果对象的最小外接矩形数据集,数据集名以“bbox”结尾。
结果数据
设置结果数据集所保存的数据源和保存名称。
3.7 通用变化检测
目前无相关文档介绍,可参考实操【7.7】
3.8 模型评估
目前无相关文档介绍,可参考实操【7.8】
4. 图片分析
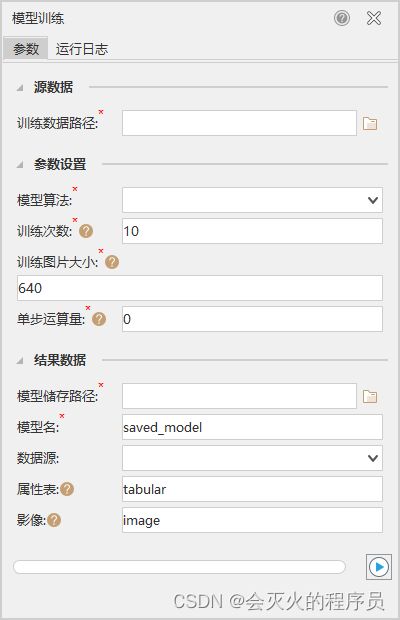
4.1 模型训练

训练数据路径
选择生成的训练数据文件夹。
训练数据用途
使用模型的功能。
训练配置文件
选择用于提取对象的模型文件(*.sdm)。
训练次数
所有训练数据参与模型训练的次数(epoch)。随着训练次数的增多,模型拟合度越大甚至过拟合。训练次数与运行花费时间成正比。默认值为 10,用户可根据需求选择。一般为 10~20 次。
单步运算量
一次训练中单步运算的图片数量(batch size)。多个图片组成的一份训练数据称之为一个 batch,每个 batch 所含的图片数量称为 batch size。在合理范围内,单步运算的数量与内存(显存)占用成正比,与训练时间成反比。默认值为 1,用户根据运行环境选择。
学习率
模型参数的更新幅度(learning rate)。一般情况下,学习率都是根据经验,设置一个相对合适的值。学习率过大,会导致待优化参数在最小值附近进行波动;学习率过小,会导致待优化参数收敛的速度慢。 默认值为 0.0001,目标检测一般为 0.001,二元分类一般为 0.0001。
训练日志路径
用户设定的训练日志存储路径,该路径下会生成多个文件夹,建议首次训练选择一个空文件夹。
加载预训练模型
若勾选该选项,可选择前一次训练的训练日志路径作为预训练模型的路径,会在前一次的基础上进行训练。 注 :前后两次训练需要训练数据的尺寸、类别和用途相同。
4.2 图片分类
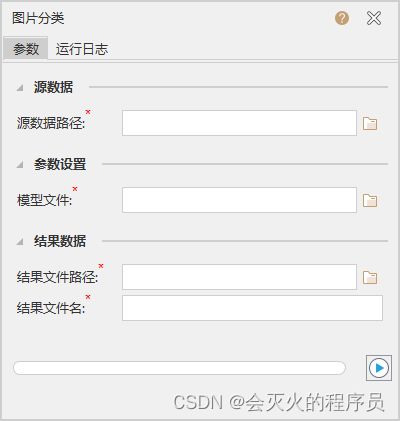
源数据路径
选择需要被分类的图片所在文件夹。
模型文件
选择用于图片分类的模型文件(*.sdm)。
结果数据
设置结果数据集所保存的数据源和保存名称。
4.3 目标检测
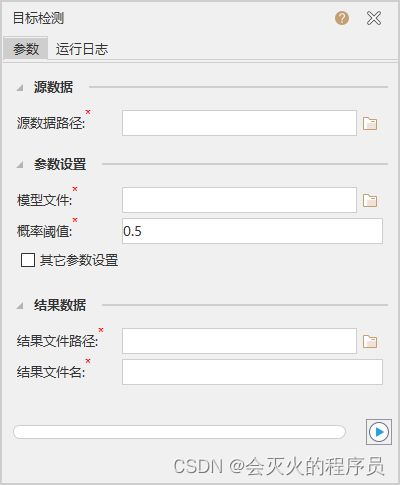
源数据路径
选择需要被检测的图片所在文件夹。
模型文件
选择用于图片目标检测的模型文件(*.sdm)。
概率阈值
对每一个检测出来的对象,系统都会为其计算出符合目标特征的概率,最后检测结果仅保留预测概率高于该值的目标,默认值为 0.5。
去重阈值
系统对一张图片里的检测对象生成多个候选框, 并分别给出概率值, 带入 NMS 算法后得到最优框,根据交并比(IoU) 去除与最优框重叠部分大于去重阈值的候选框。 去重阈值一般为 0.3~0.7,默认值为 0.3。
结果数据
设置结果数据所保存的路径及结果文件名称。
5. 视频分析
SuperMap iDesktopX 基于AI与AR技术,提供的视频分析功能,使得我们具备更强的视频感知能力,因而从视频中提取更为丰富的信息。视频分析模块提供了目标检测、车牌识别、围栏分析、轨迹提取,以及AR空间分析功能,包括缓冲区分析、空间查询、空气质量分析等,可将视频与GIS结合,在视频地图中提取更多的空间信息,并基于视频进行空间分析。
5.1 模型训练
6. 元胞自动机
元胞自动机(CA)是一种时间、空间、状态都离散,空间相互作用和时间因果关系为局部的网络动力学模型,具有模拟复杂系统时空演化过程的能力,因此,地理模拟可以通过元胞自动机来实现。它不是由严格定义的物理方程或函数确定,而是用一系列模型构造的规则构成。凡是满足这些规则的模型都可以算作是元胞自动机模型。因此元胞自动机是一类模型的总称,或者说是一个方法框架。其特点是时间、空间、状态都离散,每个变量只取有限多个状态,且其状态改变的规则在时间和空间上都是局部的。
元胞自动机的基本组成包括元胞、元胞空间、状态、邻域及转换规则等。
-
元胞:CA的基本研究对象,可以定义为规则格网。
-
空间:元胞在空间中分布的空间格点,可以是一维、二维或多维。
-
状态:可以是两种状态,如“生”或“死”,“黑”或“白”,“城市用地”或“非城市用地”来表示;也可以是多种状态,如不同的城市用地类型。
-
邻域:存在于某一元胞周围,能影响该元胞在下一时刻的状态。邻域的划分方式包括以下两种(4邻域和8邻域)。

- 转换规则:根据元胞及其邻域元胞的状态,决定下一时刻该元胞状态的动力学函数。定义转换规则是元胞自动机的核心。
元胞自动机最核心部分就是定义转换规则,整个模拟过程完全是受转换规则控制的。如何有效定义或获取转换规则中的参数是模拟对象演变的关键,目前相关学者在地理模拟中常用到的方法包括主成分分析、神经网络、马尔科夫链等,并逐渐将深度学习模型引入元胞自动机研究当中。
元胞自动机(CA)在地理模拟中最典型的应用就是模拟城市发展,为城市规划提供科学依据。CA的基本研究对象是元胞,元胞可以定义为特定空间分辨率的格网,因此能十分自然的与相应空间分辨率的遥感影像分类结果结合起来。CA强大的建模能力能模拟出与实际非常接近的结果,已被越来越多地运用到城市扩张模拟中。而最常用的城市模拟内容是土地利用变化模拟,CA可以模拟多种土地利用类型间的转变,进而对科学合理的土地利用规划服务。
在土地利用研究中,元胞空间代表所有类型土地的集合,每个元胞有各自的属性(即土地利用类型),每个元胞在下一时刻的状态由该元胞当前状态、其邻域内元胞状态和转换规则共同决定。然而由于土地系统的高度复杂性以及影响因子的多样性,元胞转换规则是该模型设计中的最大难点,常用的模拟土地利用变化的地理元胞自动机方法有基于人工神经网络的元胞自动机及基于主成分分析的元胞自动机等。
6.1 人工神经网络训练

-
训练起始栅格数据集:设置待分析的栅格数据集及所在数据源。
-
训练终止栅格数据集:设置训练终止栅格数据集及所在数据源。
-
参数设置
:
训练栅格值:填写表示类别的栅格值,用逗号隔开,例如在土地利用类型栅格数据中,栅格值1代表水域、2代表森林、3代表农田、4代表城市用地,则该处应输入1,2,3,4。
空间变量栅格数据:添加代表影响因子的空间变量栅格数据,例如表示地形、交通等的栅格数据集。
误差期望值:即训练在达到期望误差后终止,取值为[0,1],期望误差越小,达到的结果越准确,但如果太小,可能永远无法终止。
迭代最大次数:即在训练一定次数后终止,是人工神经网络训练的终止条件。
是否自定义邻域范围:
- 不勾选:需要设置邻域范围长度,即为元胞自动机考虑的正方形邻域的边长,确定提取抽样数据和进行模拟计算时所使用的NN范围的大小,范围越大,涉及的栅格越多,则当前栅格所受到邻域影响的栅格越多,可能需要根据模拟结果重新调整该参数再次进行模拟。建议取值在3-25之间,默认为7,代表使用77的栅格。
- 勾选:还需要设置邻域范围数组,自定义勾选邻域范围长度组成的矩阵代表邻域范围。
学习速率:神经网络的学习速率,数值越大,训练收敛更快,但更容易陷入局部最优解。取值范围为[0,1],默认为0.2。
抽样数目:采用随机抽样法得到训练样本的数量。抽样数目越大,则训练ANN时间越长,但需有一定的抽样数量以保证数据覆盖性,可以综合考虑数据的栅格总数及抽样成本来确定抽样数目。
模型训练路径:人工神经网络训练后的模型保存路径。
6.2 基于人工神经网络的元胞自动机

-
人工神经网络训练结果:在可视化建模中连接人工神经网络训练,该过程的结果即为此参数的输入。
-
起始数据栅格:设置起始栅格数据集及所在数据源。
-
参数设置:
空间变量栅格数据:添加代表影响因子的空间变量栅格数据,例如表示地形、交通等的栅格数据集。
迭代结果保存:
- 勾选:表示保存中间迭代结果。
- 不勾选:表示不保存中间迭代结果。
结果保存频率:即每隔多少次迭代输出一次结果,默认为10。
结果更新频率:即每隔多少次迭代刷新一次输出信息和图表。
转换数目:栅格转换数目作为模拟终止的策略,是指模拟终止时刻与初始时刻城市用地栅格数量之差。模拟过程可以使用初始时刻和终止时刻城市用地栅格变化量作为转换数目,模拟达到总量时终止模拟过程。若要进行土地利用变化预测时,应根据研究区土地利用变化趋势或设定的模拟情景来科学合理地确定转换数量。
迭代次数:该参数是为了防止每次迭代的转换数目不确定,而导致迭代次数过多。元胞自动机转换终止条件是转换数目,设置迭代次数,可以确定每次迭代的转换数目,该值转换数目除以迭代次数。通常CA模拟使用几十-几百次迭代。
是否检验结果:是否与终止数据进行对比。
- 勾选:表示需要与终止栅格数据进行对比,进而得到正确率,此时需要增加设置终止数据栅格的数据集及所在数据源。
- 不勾选:表示不需要与终止数据进行对比。
转变概率阈值:转变概率超过规定的阈值后,土地类型才会发生转变,阈值越大,变化越慢,取值范围为0-1,默认为0.75。
扩散参数:用来控制随机扰动的强度,取值在1-10范围内,值越大则计算的概率值越大。
栅格值数组:填写表示类别的栅格值,用逗号隔开,例如在土地利用类型栅格数据中,栅格值1代表水域、2代表森林、3代表农田、4代表城市用地,则该处应输入1,2,3,4。
转换规则:元胞自动机转换规则即是否可以转换为其他用地类型。设置不能转换时相当于设定该类型为限制发展区域,例如水体一般不可以转换为其他用地类型,林地、耕地等可以转换为城市用地。当输入“栅格值数值”后,该框中出现转换矩阵,勾选表示纵坐标类型可以转换为横坐标类型。
-
结果数据:设置结果数据集及所在数据源。
6.3 主成分分析训练

- 空间变量栅格数据:添加代表影响因子的空间变量栅格数据,例如表示地形、交通等的栅格数据集。
- 抽样数目:采用随机抽样法得到训练样本的数量。抽样数目越大,则训练时间越长,但需有一定的抽样数量以保证数据覆盖性,可以综合考虑数据的栅格总数及抽样成本来确定抽样数目。
- 主成分比例:取值范围 [0,1],例如取值为0.8时,表示选取前n个累计贡献率达到80%的主成分。
- 主成分分析模型保存路径:设置主成分分析模型输出保存的路径。
6.4 基于主成分分析的元胞自动机

-
主成分分析结果:在可视化建模中连接主成分分析训练,该过程的结果即为此参数的输入。
-
主成分分析模型保存路径:设置主成分分析训练过程得到的模型路径。
-
起始数据栅格:设置起始栅格数据集及所在数据源。
-
参数设置:
空间变量栅格数据:添加代表影响因子的空间变量栅格数据,例如表示地形、交通等的栅格数据集。
是否保存中间迭代结果:
- 勾选:表示保存中间迭代结果。
- 不勾选:表示不保存中间迭代结果。
结果保存频率:即每隔多少次迭代输出一次结果,默认为10。
结果更新频率:即每隔多少次迭代刷新一次输出信息和图表。
转换数目:栅格转换数目作为模拟终止的策略,是指模拟终止时刻与初始时刻城市用地栅格数量之差。模拟过程可以使用初始时刻和终止时刻城市用地栅格变化量作为转换数目,模拟达到总量时终止模拟过程。若要进行土地利用变化预测时,应根据研究区土地利用变化趋势或设定的模拟情景来科学合理地确定转换数量。
迭代次数:该参数是为了防止每次迭代的转换数目不确定,而导致迭代次数过多。元胞自动机转换终止条件是转换数目,设置迭代次数,可以确定每次迭代的转换数目,该值转换数目除以迭代次数。通常CA模拟使用几十-几百次迭代。
主成分权重数组:对主成分分析训练生成的主成分依次进行权重赋值,参考数值为:(1)非常重要:1.0;(2)很重要:0.75;(3)重要:0.5;(4)不太重要:0.25;(5)不重要:0.0。
指数变换值:非线性指数变换值,本系统为4。
扩散参数:用来控制随机扰动的强度,取值在1-10范围内,值越大则计算的概率值越大。
转换目标:例如农田转换为城市用地中,城市用地为转换目标。
转换规则:元胞自动机转换规则即是否可以转换为其他用地类型。设置不能转换时相当于设定该类型为限制发展区域,例如水体一般不可以转换为其他用地类型,林地、耕地等可以转换为城市用地。这里可以转换为上面设置的**“转换目标”**则选择true,不能转换则选择false。
-
迭代结果:设置中间迭代结果数据集及所在数据源。
-
结果数据:设置结果数据集及所在数据源。
7. 案例实操
案例实操使用机器学习资源包下的数据,数据详细说明请参考【7.1 机器学习资源包说明】。
7.1 机器学习资源包说明
机器学习资源包(即 【2.2】 中的SuperMap iObjects Python Machine Learning Resources 11i(2022)资源包)包含了SuperMap各产品中机器学习功能所需文件,如示例数据、程序、模型和训练配置文件等,详情请见目录结构。
1. 使用方式
- SuperMap iObjects Python:将资源包放在任意路径下,配置好SuperMap iObjects Python产品可运行
example中的示例程序 - SuperMap iDesktopX:将资源包
resources_ml文件夹解压到SuperMap iDesktopX根目录 - SuperMap iServer:将资源包
resources_ml文件夹解压到SuperMap iServer根目录中support/python文件夹下
2. 目录结构
resources_ml
├─backbone:主干网络权重
│
├─example:示例程序
│
├─example_data:示例数据
│ ├─densitycluster.udbx:密度聚类点数据
│ │
│ ├─evaluation:模型评估示例数据
│ │ ├─image_binary_classification
│ │ │ └─binary_cls_evaluation.udbx:二元分类模型评估示例数据
│ │ │
│ │ ├─image_object_detection
│ │ │ └─object_detection_evaluation.udbx:目标检测模型评估示例数据
│ │ │
│ │ ├─image_multi_classication
│ │ │ └─multi_cls__evaluation.udbx:地物分类模型评估示例数据
│ │ │
│ │ └─image_general_change_detection
│ │ └─change_detection_evaluation.udbx:通用变化检测模型评估示例数据
│ │
│ ├─inference:推理示例数据
│ │ │ building.udb:建筑物影像udb格式(U-Net)
│ │ │ building.udd
│ │ │ building_infer.tif:建筑物影像tif格式(U-Net)
│ │ │ building_infer_fpn_openc.tif:建筑物影像tif格式(FPN)
│ │ │ cd_image1.tif:普通变换检测tif格式影像
│ │ │ cd_image2.tif:普通变换检测tif格式对比影像
│ │ │ dp3_multi_infer.tfw
│ │ │ dp3_multi_infer.tif:地物分类tif格式(DeepLabV3+)
│ │ │ landcover_infer.tif:土地利用影像tif格式(U-Net)
│ │ │ lcz_infer.tif:城市气候区影像tif格式
│ │ │ plane_infer.tfw
│ │ │ plane_infer.tif:飞机影像tif格式
│ │ │ pv_panels_infer.tfw
│ │ │ pv_panels_infer.tif:光伏板影像tif格式
│ │ │ result.udbx:结果数据源
│ │ │ road_infer.tif:道路影像tif格式
│ │ │ road_infer.udbx:道路影像udbx格式
│ │ │ tabular_cls_infer.csv:中草药元素含量表格数据csv格式
│ │ │
│ │ ├─image_inference:电表数据jpg格式
│ │ │
│ │ ├─METR-LA:交通流量数据npz格式
│ │ │
│ │ ├─od_inference_road:道路破损图片jpg格式
│ │ │
│ │ ├─od_inference_traffic_sign:交通标志图片jpg格式
│ │ │
│ │ └─server:机器学习服务示例数据
│ │ binary_infer.udb:二元分类推理示例数据(建筑物)
│ │ binary_infer.udd
│ │ landcover_infer.udb:地物分类推理示例数据(土地利用分类)
│ │ landcover_infer.udd
│ │ ML_inference.udbx:分布式机器学习服务推理示例数据(基于森林的分类和回归、广义线性回归)
│ │ object_ext_infer.udb:对象提取推理示例数据(光伏板)
│ │ object_ext_infer.udd
│ │ object_infer.udb:目标检测推理示例数据(飞机)
│ │ object_infer.udd
│ │ scene_infer.udb:场景分类推理示例数据(城市气候区)
│ │ scene_infer.udd
│ │
│ └─training:训练示例数据
│ │ ML_train.udbx:分布式机器学习服务训练示例数据(基于森林的分类和回归、广义线性回归)
│ │
│ ├─binary_cls_train_data:二元分类训练示例数据(建筑物)
│ │ ├─raw:原始影像和标签数据
│ │ │
│ │ └─train_data:生成好的训练数据
│ │
│ ├─meter_image_cls_train_data:图片分类训练示例数据(电表)
│ │ └─train_data:生成好的训练数据
│ │
│ ├─METR-LA:时空预测训练示例数据(交通流量)
│ │ │
│ │ └─raw:原始交通流量表格数据
│ │
│ ├─multi_cls_train_data:地物分类训练示例数据(土地利用)
│ │ ├─raw:原始影像和标签数据
│ │ │
│ │ └─train_data:生成好的训练数据
│ │
│ ├─object_det_train_data:目标检测训练示例数据(飞机)
│ │ ├─raw:原始影像和标签数据
│ │ │
│ │ └─train_data:生成好的训练数据
│ │
│ ├─object_ext_train_data:对象提取训练示例数据(光伏板)
│ │ ├─raw:原始影像和标签数据
│ │ │
│ │ └─train_data:生成好的训练数据
│ │
│ ├─general_cd_train_data:通用变化检测(建筑物)
│ │ └─raw:原始两景影像和标签数据
│ │
│ ├─scene_cls_train_data:场景分类训练示例数据(城市气候区)
│ │ ├─raw:原始影像和标签数据
│ │ │
│ │ └─train_data:生成好的训练数据
│ │
│ └─tabular_cls_train_data:xgboost分类模型训练数据
│ └─raw:原始表格数据
│
├─model:示例模型
│ ├─forest_cls:基于森林的分类模型(中华按蚊适生区)
│ │
│ ├─forest_regr:基于森林的回归模型(房价预测)
│ │
│ ├─glr:广义线性回归模型(出生缺陷率预测)
│ │
│ ├─graph_streg_metrla:时空预测模型(交通流量)
│ │
│ ├─scene_cls_lcz:场景分类模型(城市气候区)
│ │
│ ├─general_cd_siamsfnet_building:通用变化检测模型(建筑物)
│ │
│ └─obj_det_plane_car_ship_cascade:影像目标检测Cascade R-CNN模型(飞机)
│
├─process_operator:机器学习算子
│
└─trainer_config:深度学习训练配置文件
├─general_change_detection:通用变化检测功能训练配置文件
│ general_cd_dsamnet.sdt:基于DSAMNet的通用变化检测
│ general_cd_siamsfnet.sdt:基于Siam-Net的通用变化检测
│
├─graph_spatio_temporal_regression:图时空回归功能训练配置文件
│ graph_streg_dcrnn.sdt:基于DCRNN的图时空回归
│
├─image_classification:图片分类训练配置文件
│ image_cls_efficientnet.sdt:基于EfficientNet的图片分类
│
├─scene_classification:场景分类训练配置文件
│ scene_cls_efficientnet.sdt:基于EfficientNet的场景分类
│
├─tabular_classification:表格分类训练配置文件
│ tabular_automl_train.sdt:自动机器学习表格分类
│ tabular_cls_xgb_train.sdt:xgboost表格分类
│
├─binary_classification:二元分类功能训练配置文件
│ binary_cls_train_config_deeplabv3plus.sdt:基于DeepLabV3+的二元分类
│ binary_cls_train_config_dlinknet.sdt:基于D-LinkNet的二元分类
│ binary_cls_train_config_fpn.sdt:基于FPN的二元分类
│ binary_cls_train_config_sfnet.sdt:基于SFNet的二元分类
│ binary_cls_train_config_unet.sdt:基于U-Net的二元分类
│
├─multi_classification:地物分类功能训练配置文件
│ multi_cls_train_config_deeplabv3plus.sdt:基于DeepLabV3+的地物分类
│ multi_cls_train_config_fpn.sdt:基于FPN的地物分类
│ multi_cls_train_config_sfnet.sdt:基于SFNet的地物分类
│ multi_cls_train_config_unet.sdt:基于U-Net的地物分类
│
├─object_detection:目标检测功能训练配置文件
│ train_config_cascade_rcnn_R_50_FPN_3x.sdt:基于Cascade R-CNN的目标检测
│ train_config_faster_rcnn_R_50_FPN_3x.sdt:基于Faster R-CNN的目标检测
│ train_config_retinanet_R_50_3x.sdt:基于RetinaNet的目标检测
│
└─object_extraction:对象提取功能训练配置文件
train_config_mask_rcnn_R_50_FPN_3x.sdt:基于Mask R-CNN的对象提取
【注】ML_train.udbx中ForestBasedClassification用于基于森林的分类,ForestBasedRegression用于基于森林的回归,glr用于广义线性回归。在以上三个功能的训练过程中,建模字段分别为dataType、total_price、NTD_rate,其余为解释字段(可选择)
7.2 目标检测
目标检测使用【7.1】中的目标检测(飞机)数据进行测试。
1. 准备数据
数据:resources_ml\example_data\training\object_det_train_data\raw下的plane.tif,打开后如下图:
模型:resources_ml\model\obj_det_plane_car_ship_cascade文件夹下的obj_det_plane_car_ship_cascade.sdm模型
说明:实际项目应用过程中,模型需要使用项目数据重新训练,此测试使用【7.1】中的现有模型数据。如果需要自己练习训练模型,可参考【3.2】、 【3.3】 中的步骤进行模型训练
2. 执行目标检测分析
- 在iDesktop的工具箱中选择“机器学习——影像分析——目标检测”。

- 在数据源中选择提前打开好的准备数据,参数设置中选择【7.2-1】中准备好的模型数据。
- 选择结果数据存放位置(可以自己新建数据源,这里是新建了一个内存数据源来存放结果数据),点击右下角执行按钮。
- 等待结果执行完毕(执行时长不到5分钟),将结果集在地图中打开,设置图层风格,展示效果如下:
7.3 二元分类
二元分类使用【7.1】中的 二元分类训练示例数据(建筑物)
1. 准备数据
**数据:**resources_ml\example_data\training\binary_cls_train_data\raw\文件夹下的image.tif
**训练数据:**resources_ml\example_data\training\binary_cls_train_data\train_data
注:二元分类的建筑没有训练模型,所以这里我们需要自己使用提供的训练数据训练模型。
2. 模型训练
- 点击iDesktopx的工具箱下的“机器学习——影像分析——模型训练”
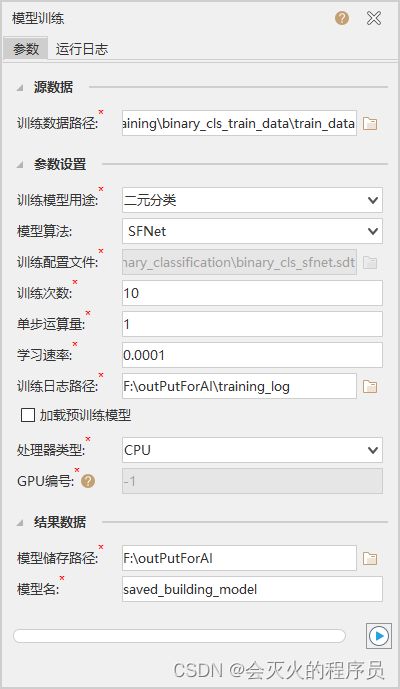
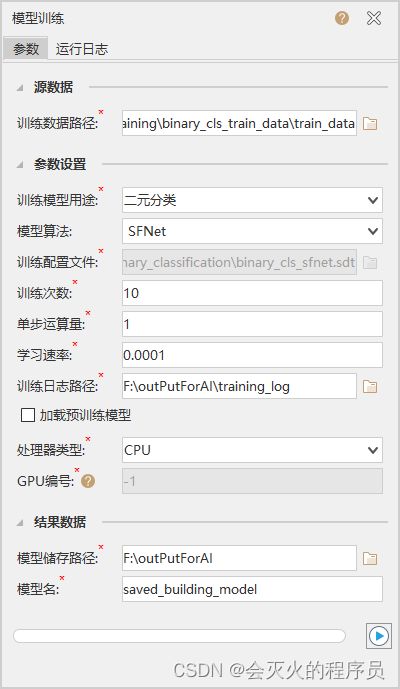
- 训练数据使用【7.3-1】准备好的训练数据,然后填入训练模型用途、训练日志路径、处理器类型、模型储存路径。
- 点击右下角执行按钮,开始生成模型,生成时间较长(图中参数生成共花费了4个多小时),在上图中的模型存储路径下会生成下图所示文件:
3. 执行二元分类检测分析
-
打开准备好的用于分析的影像数据,然后在工具箱下点击“机器学习——影像分析——二元分类”

-
点击右下角执行,执行结束后,会在数据集下生成一个栅格数据,在地图中窗口通过专题图展示如下图所示:

4. 结果数据处理
**注:**结果数据处理请参考【8-1】。
7.4 地物分类
地物分类使用【7.1】中的 地物分类训练示例数据(土地利用)
1. 准备数据
**数据:**resources_ml\example_data\training\multi_cls_train_data\raw\文件夹下的image.tif
**训练数据:**resources_ml\example_data\training\multi_cls_train_data\train_data文件夹
注:地物分类的没有现成的训练模型,所以这里我们需要自己使用提供的训练数据训练模型。
2. 训练模型

注:模型训练步骤同上【7.3-2】,这里不做重复说明(模型训练过程共花费1小时20分钟)
3. 执行地物分类分析
- 在iDesktop的工具箱中选择“机器学习——影像分析——地物分类”。
- 在数据源中选择提前打开好的准备数据,参数设置中选择2步骤中生成的模型数据。
- 选择结果数据存放位置(可以自己新建数据源,这里是新建了一个内存数据源来存放结果数据),点击右下角执行按钮。
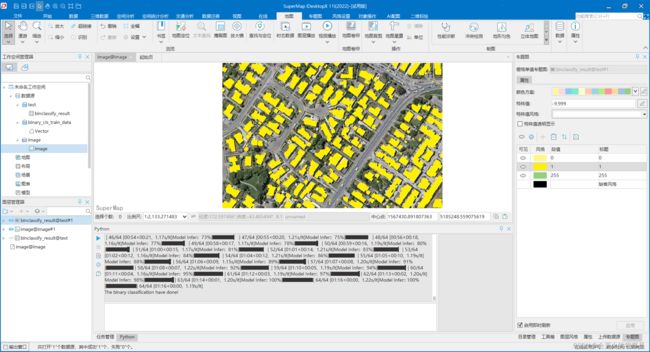
- 等待结果执行完毕(执行时长大约4分钟),将结果集在地图中打开,设置栅格图层风格,展示效果如下:
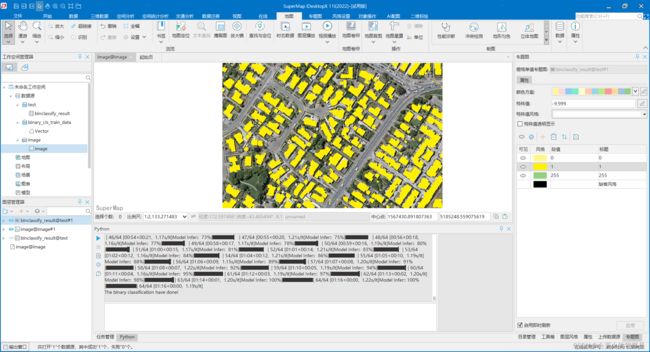
注:后续栅格转矢量请参考常见问题【8-1】
7.5 场景分类
地物分类使用【7.1】中的 场景分类训练示例数据(城市气候区)
1.准备数据
**数据:**resources_ml\example_data\training\general_cd_train_data\raw文件夹下的image.tif
**模型:**resources_ml\model\scene_cls_lcz文件夹下的模型数据
2. 执行场景分类分析
-
在iDesktop的工具箱中选择“机器学习——影像分析——场景分类”。

-
在数据源中选择提前打开好的准备数据,参数设置中选择【7.5-1】中准备好的模型数据。
-
选择结果数据存放位置(可以自己新建数据源,这里是新建了一个内存数据源来存放结果数据),点击右下角执行按钮。
-
等待结果执行完毕(执行时间不到1分钟),将结果集在地图中打开,设置图层风格,展示效果如下:
7.6 对象提取
对象提取使用【7.1】中的 对象提取训练示例数据(光伏板)
1. 准备数据
**数据:**resources_ml\example_data\training\object_ext_train_data\raw\文件夹下的image.tif
**训练数据:**resources_ml\example_data\training\object_ext_train_data\train_data文件夹
注:对象提取没有现成的训练模型,所以这里我们需要自己使用提供的训练数据训练模型。
2. 训练模型

注:模型训练步骤同上【7.3-2】,这里不做重复说明(模型训练过程共花费1小时10分钟)
3. 执行对象提取分析
-
打开准备好的用于分析的影像数据,然后在工具箱下点击“机器学习——影像分析——对象提取”
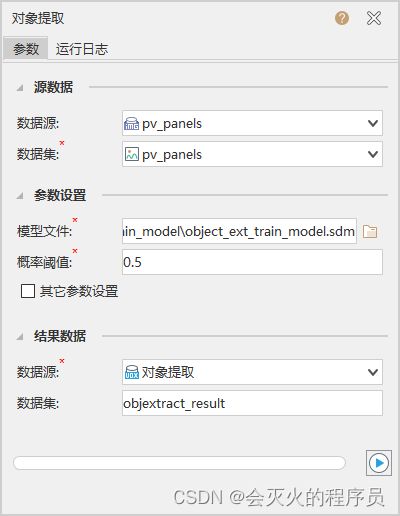
-
点击右下角执行,执行结束后(执行时长约3分钟左右),将结果集在地图中打开,设置图层风格,展示效果如下:

7.7 通用变化检测
通用变化检测使用【7.1】中的 通用变化检测(建筑物)
1.准备数据
**数据:**resources_ml\example_data\training\scene_cls_train_data\raw文件夹下的image1.tif和image2.tif
**模型:**resources_ml\model\scene_cls_lcz文件夹下的模型数据
2. 执行通用变化检测分析
- 在iDesktop的工具箱中选择“机器学习——影像分析——通用变化检测”。
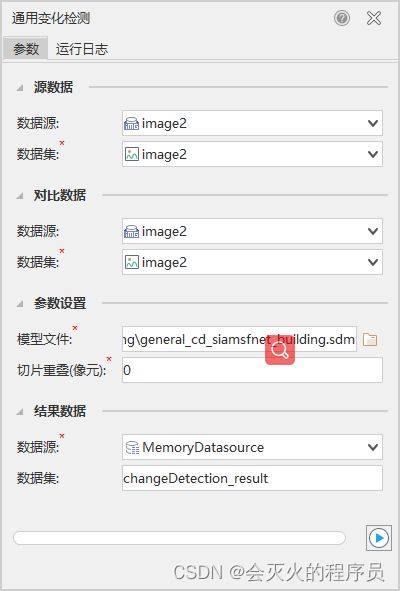
- 在数据源中选择提前打开好的准备数据,参数设置中选择【7.7-1】中准备好的模型数据。
- 选择结果数据存放位置(可以自己新建数据源,这里是新建了一个内存数据源来存放结果数据),点击右下角执行按钮。
- 等待结果执行完毕(执行时间不到2分钟),将结果集在地图中打开,设置图层风格,展示效果如下:

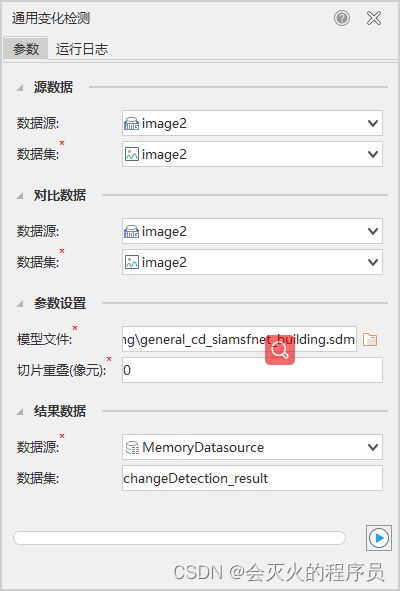
7.8 模型评估
模型评估目前可对目标目标检测、二元分类、地物分类、通用变化检测等影像分析模型结果进行评估。在iDesktop的工具箱中选择“机器学习——影像分析——模型评估”进入模型评估页面。
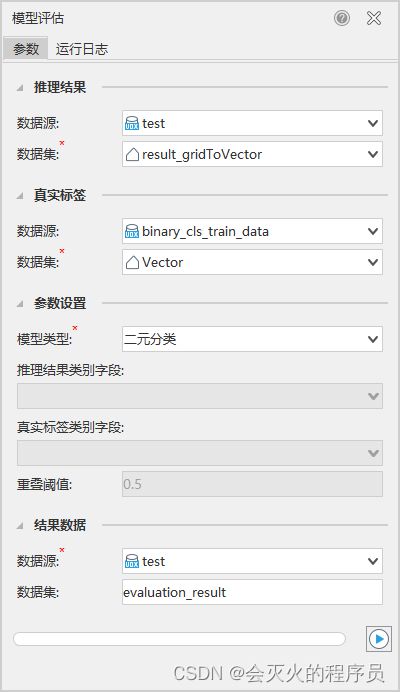
如下图所示,是对【7.3 二元分类】进行模型评估的结果:
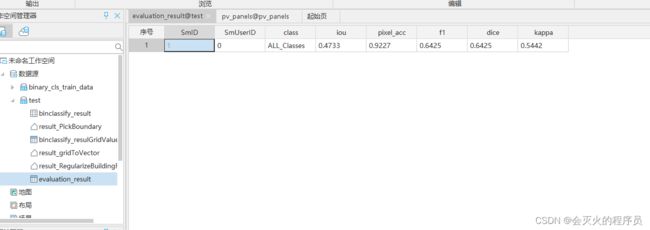
参数说明
-
iou: 定位准确率可以通过检测窗口与我们自己标记的物体窗口的重叠度,即交并比,即Intersection-Over-Union(IOU)进行度量。
-
pixel_acc:像素准确率,预测类别正确的像素数占总像素的比例。
-
f1:F1值是来综合评估精确率和召回率,当精确率和召回率都高时,F1也会高。参考文章:https://www.cnblogs.com/ljhdo/p/10609106.html
- 召回率(Recall Rate,也叫查全率)是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;
- 精准率(Precision Rate,也叫查准率)是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
-
dice:DICE系数也是常用的分割评价标准之一,DICE系数的取值范围为0到1,越接近1说明构建的模型越好,分割的效果越好。DICE系数是像素级别的。
-
kappa:kappa系数是用在统计学中评估一致性的一种方法,可以用它来进行多分类模型准确度的评估,这个系数的取值范围是[-1,1],实际应用中,一般是[0,1]。这个系数的值越高,则代表模型实现的分类准确度越高。
7.9 图片分析-图片分类
图片分类使用【7.1】中的 图片分类训练示例数据(电表)
1. 准备数据
**训练数据:**resources_ml\example_data\training\meter_image_cls_train_data\train_data文件夹
注:对象提取没有现成的训练模型,所以这里我们需要自己使用提供的训练数据训练模型。
2. 训练模型

注:使用官网11.0版本的iDesktopx没有跑成功,申请的临时11.1版本可以正常训练模型。模型训练步骤同上【7.3-2】,这里不做重复说明(模型训练过程共花费30分钟左右)
3. 执行图片分类分析
-
打开准备好的用于分析的影像数据,然后在工具箱下点击“机器学习——图片分析——图片分类”

-
点击右下角执行,执行结束后,会在结果文件路径下生成image_cls_efficientnet_result.csv文件,如下图所示:

8. 常见问题处理
1. 使用二元分类检测后生成的结果栅格数据在地图窗口打开是一片黑色的。
二元检测的结果是一个栅格数据,下图是二元分类建筑物的提取结果直接在地图中打开效果:

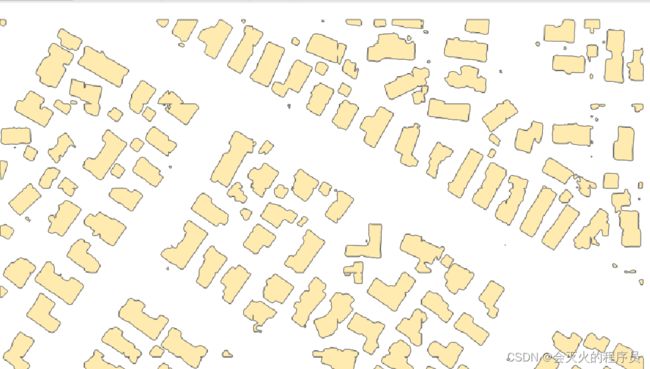
可以采用生成栅格专题图、栅格转矢量、建筑物规则化等方法对生成结果进行再次处理。
1) 对栅格数据创建栅格专题图,下图是二元分类建筑物的栅格专题图:
2) 使用栅格转矢量的方式,将栅格数据转换为矢量面数据,下图是对1)的binclassify_result栅格数据进行转矢量后的结果:

3) 如果提取的是建筑物,可以使用建筑物规则化,对建筑物进行规则化修整。这个过程会非常的慢,我的测试环境是662个面数据,总共用时超过6个小时。下图是对2)的矢量数据进行修正后的结果:
