自然语言理解(NLU)-文本纠错学习笔记1
1概念理解:
首先,文本纠错是实现文本语句自动检查、自动纠错的一项重要技术,提高语言的正确性并减少人工成本。
通常类型有:语音转换语言转换、发音不标准、拼写错误、语法错误(多打漏打乱序等)、知识错误(概念模糊)等
2目前研究现状:
目前纠错方法主要分为两个方向:基于规则和基于深度模型
基于规则:第一步是错误检测,第二步是错误纠正
错误检测:先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
错误纠正:遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
深度模型: 具体可参照下文中“其他”部分的第三类方法
端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,rnn_attention在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
seq2seq模型是使用encoder-decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一。
常用纠错模型:Pycorrector
该纠错模型是由规则纠错和深度学习纠错两部分组成
常见研究:
“而中文文本纠错学术进展主要集中在比赛项目上,如前几年SIGHAN举办的中文拼写纠错比赛以及近几年NLPCC等举办的中文语法检测和纠错的比赛等。在2017年的中文语法错误检测比赛中,其Top1的主要方案利用了序列标注模型结合人工提取特征。在NLPCC2018年举办的中文语法纠错比赛中,冠军团队应用基于Transformer的翻译模型,其主要原理是将错误句子翻译为正确句子。”
开源项目:
中文文本纠错算法走到多远了?_悟乙己的博客-CSDN博客_文本纠错
中文文本纠错算法--错别字纠正的二三事 - 知乎
其他
对一个特定领域的项目时,文本纠错方法可以有以下几种:
(文本纠错 - 知乎)
1、构建一个领域字典
红细胞 --> 红细胸、虹细胞、红组胞
真菌 --> 其菌、真蓝、真萄
血小板 --> 面小板、曲小板、血小权、值小板
总结一个错误表述到正确表述的词典,然后进行匹配替换就行。
如有纠错行为产生,则一定能够纠正成功。
2、编辑距离
将输入文本与标准文本描述的文本进行编辑距离(对文本进行:增/删/插 操作,不熟悉编辑距离的读者可以自行百度搜索)的计算,然后输出编辑距离最近的标准描述。
input:输入文本 output:纠正后描述 minDistance = +inf for 标准表述 in 标准描述库: if distance(输入文本,标准描述)< minDistance: output = 标准表述
将输入文本进行分词等操作,形成词粒度或字粒度的形式。计算输入文本和标准词库中的距离信息,取距离值最小的作为该输入文本的正确表述,并输出。
可能会出现纠正行为产生后,仍旧输出错误表述。
3、深度学习
为了降低误判率,可以在模型的输出层加入CRF层校对,通过学习转移概率和全局最优路径避免不合理的错别字输出。
详细通俗重点CRF层讲解_weixin_ry5219775的博客-CSDN博客_crf层
CRF,巧妙而不复杂 - 知乎
具体方法:
【1】HANSpeller++: A Unified Framework for Chinese Spelling Correction Shuiyuan
pipeline : 预处理+备选生成+答案选择
【2】Confusionset-guided Pointer Networks for Chinese Spelling Check
利用seq2seq模型

【3】Spelling Error Correction with Soft-Masked BERT
分为检测网络(Bi-GRU)和校正网络(基于BERT的序列多分类标记模型-BERT 12层Transformer模块)
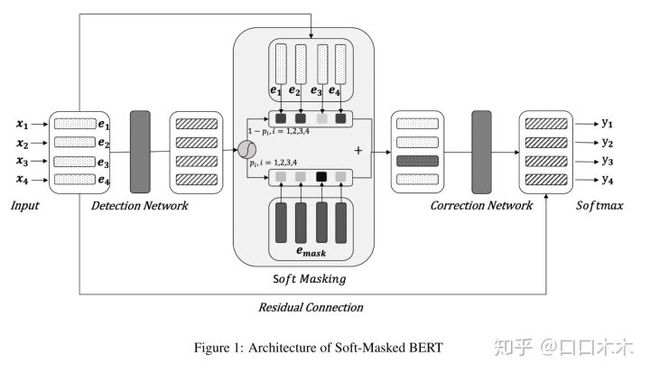
代码复现:
1、pycorrector:【深度学习】PyCorrector中文文本纠错实战_海贼王的博客的博客-CSDN博客_pycorrector
2、BiLSTM+CRF
3、Seq2Seq(BiLSTM,BiLSTM+attention)
4、BiGRU+BERT
参考资料:
【NLP-文本纠错】从入门到精通 - 简书
中文文本纠错_论文Spelling Error Correction with Soft-Masked BERT(ACL_2020)学习笔记与模型复现_料理菌的博客-CSDN博客
策略算法工程师之路-Query纠错算法 - 知乎
平安寿险 AI 团队 | 文本纠错技术探索和实践 - AIQ
中文文本纠错算法走到多远了?_悟乙己的博客-CSDN博客_文本纠错