【论文笔记】Explainable Reasoning over Knowledge Graphs for Recommendation
原文作者:Xiang Wang,Dingxian Wang,Canran Xu, Xiangnan He, Yixin Cao,
Tat-Seng Chua
原文标题:Explainable Reasoning over Knowledge Graphs for Recommendation
原文来源:AAAI 2019
原文链接:https://ojs.aaai.org//index.php/AAAI/article/view/4470
Explainable Reasoning over Knowledge Graphs for Recommendation
近些年,通过附加信息刻画用户-物品交互特征,为推荐系统赋予更好的可解释性成为了一个较热的研究课题。
通过知识图谱,用户-物品间的交互可以通过知识图谱找到的关联路径作解释。这类关联路径不仅表述了知识图谱中实体和关系的语义,还能够帮助我们理解用户的兴趣偏好,赋予推荐系统推理能力和可解释性。该论文提出了一种基于循环神经网络的方法KPRN,建模用户-物品对在知识图谱中存在的关联路径,为用户提供可解释的推荐。
问题定义
传统知识图谱可被定义为在已知实体和关系集合上的有向图:
KG = { ( h , r , t ) ∣ h , t ∈ E , r ∈ R } \mathcal{\text{KG}} = \{(h,r,t) \mid h,t\mathcal{\in E,}r\mathcal{\in R\}} KG={(h,r,t)∣h,t∈E,r∈R}
其中, E \mathcal{E} E是实体集合, R \mathcal{R} R是关系集合。三元组 ( h , r , t ) (h,r,t) (h,r,t)则表示从头实体 h h h到尾实体 t t t有关系 r r r这样的事实。
U = { u t } t = 1 M \mathcal{U =}\left\{ u_{t} \right\}_{t = 1}^{M} U={ut}t=1M和 I = { i t } t = 1 N \mathcal{I =}\left\{ i_{t} \right\}_{t = 1}^{N} I={it}t=1N分别表示用户集和item集,M和N是用户和item的数量。使用一个三元组 τ = ( u , interact , i ) \tau = \left( u,\text{interact},i \right) τ=(u,interact,i)表示用户和item之间的交互,将用户与实体合并,关系与交互合并,得到一个新的知识图谱。
G = { ( h , r , t ) ∣ h , t ∈ E ′ , r ∈ R ′ } \mathcal{G} = \{(h,r,t) \mid h,t \in \mathcal{E}^{'},r \in \mathcal{R}^{'}\} G={(h,r,t)∣h,t∈E′,r∈R′}
其中, E ′ = E ∪ U \mathcal{E}^{'}\mathcal{= E \cup U} E′=E∪U, R ′ = R ∪ {interact} \mathcal{R}^{'} = \mathcal{R \cup}\text{\{}\text{interact}\text{\}} R′=R∪{interact}。
给定用户 u u u,目标item
i i i,以及 ( u , i ) \left( u,i \right) (u,i)间的路径集合 P ( u , i ) = { p 1 , p 2 , ⋯ , p K } \mathcal{P(}u,i) = \left\{ p_{1},p_{2},\cdots,p_{K} \right\} P(u,i)={p1,p2,⋯,pK},
对用户与item发生交互的可能性做估计(CTR):
y ^ ui = f Θ ( u , i ∣ P ( u , i ) ) {\widehat{y}}_{\text{ui}} = f_{\Theta}(u,i \mid \mathcal{P(}u,i)) y ui=fΘ(u,i∣P(u,i))
与基于嵌入的模型不同的是,可以将 y ^ ui {\widehat{y}}_{\text{ui}} y ui解释为由 P ( u , i ) \mathcal{P(}u,i) P(u,i)推理出的三元组 τ = ( u , interact , i ) \tau = \left( u,\text{interact},i \right) τ=(u,interact,i)的合理性分数。
KPRN模型

如上图所示KPRN模型中有三个关键部分:
- 嵌入层。
将实体、实体类型、指向下一个节点的关系投影到隐空间中。将每个实体的类型、值分别投影为两个嵌入向量, e l ∈ R d , e l ′ ∈ R d \mathbf{e}_{l} \in \mathbb{R}^{d},\mathbf{e}_{l}^{'} \in \mathbb{R}^{d} el∈Rd,el′∈Rd。现实世界中,很多实体对在不同的关系下有着完全不同的语义,作者认为这些差异或许是用户选择item的原因。因此,将关系的语义明确地纳入路径表示学习中是很重要。每个关系嵌入表示为: r l ∈ R d \mathbf{r}_{l} \in \mathbb{R}^{d} rl∈Rd。对于路径 p k p_{k} pk,可以得到 [ e 1 , r 1 , e 2 , ⋯ , r L − 1 , e L ] \left\lbrack \mathbf{e}_{1},\mathbf{r}_{1},\mathbf{e}_{2},\cdots,\mathbf{r}_{L - 1},\mathbf{e}_{L} \right\rbrack [e1,r1,e2,⋯,rL−1,eL],其中每个元素都表示一个实体或关系。
- LSTM层。
按顺序对元素进行编码,目的是捕获以关系为条件的实体的组合语义。使用RNN模型来研究路径中的序列信息。为了记忆序列中的长期依赖,作者选择了LSTM模型。在评估连接用户和item实体的交互关系的可信度时,长期序列模式是很重要的。在路径中 l − 1 l - 1 l−1步,LSTM层输出状态向量 h l − 1 h_{l - 1} hl−1,同时将当前实体 e l − 1 e_{l - 1} el−1和关系 r l − 1 r_{l - 1} rl−1作为输入向量:
x l − 1 = e l − 1 ⊕ e l − 1 ′ ⊕ r l − 1 \mathbf{x}_{l - 1} = \mathbf{e}_{l - 1} \oplus \mathbf{e}_{l - 1}^{'} \oplus \mathbf{r}_{l - 1} xl−1=el−1⊕el−1′⊕rl−1
其中 ⊕ \oplus ⊕为拼接操作。这样 x \mathbf{x} x中即包含序列信息,又包含语义信息(实体和与下一个实体间的关系)。
h l − 1 h_{l - 1} hl−1和 x l − 1 \mathbf{x}_{l - 1} xl−1用来学习下一步的隐藏状态:
z l = tanh ( W z x l + W h h l − 1 + b z ) f l = σ ( W f x l + W h h l − 1 + b f ) i l = σ ( W i x l + W h h l − 1 + b i ) o l = σ ( W o x l + W h h l − 1 + b o ) c l = f l ⊙ c l − 1 + i l ⊙ z l h l = o l ⊙ tanh ( c l ) \begin{matrix} \mathbf{z}_{l}\ &= \tanh\left( \mathbf{W}_{z}\mathbf{x}_{l} + \mathbf{W}_{h}\mathbf{h}_{l - 1} + \mathbf{b}_{z} \right) \\ \mathbf{f}_{l}\ &= \sigma\left( \mathbf{W}_{f}\mathbf{x}_{l} + \mathbf{W}_{h}\mathbf{h}_{l - 1} + \mathbf{b}_{f} \right) \\ \mathbf{i}_{l}\ &= \sigma\left( \mathbf{W}_{i}\mathbf{x}_{l} + \mathbf{W}_{h}\mathbf{h}_{l - 1} + \mathbf{b}_{i} \right) \\ \mathbf{o}_{l}\ &= \sigma\left( \mathbf{W}_{o}\mathbf{x}_{l} + \mathbf{W}_{h}\mathbf{h}_{l - 1} + \mathbf{b}_{o} \right) \\ \mathbf{c}_{l}\ &=\mathbf{f}_{l} \odot \mathbf{c}_{l - 1} + \mathbf{i}_{l} \odot \mathbf{z}_{l} \\ \mathbf{h}_{l}\ &= \mathbf{o}_{l} \odot \tanh\left( \mathbf{c}_{l} \right) \\ \end{matrix} zl fl il ol cl hl =tanh(Wzxl+Whhl−1+bz)=σ(Wfxl+Whhl−1+bf)=σ(Wixl+Whhl−1+bi)=σ(Woxl+Whhl−1+bo)=fl⊙cl−1+il⊙zl=ol⊙tanh(cl)
其中, c l ∈ R d ′ , z ∈ R d ′ \mathbf{c}_{l} \in \mathbb{R}^{d^{'}},\mathbf{z} \in \mathbb{R}^{d^{'}} cl∈Rd′,z∈Rd′分别表示记忆细胞的状态向量和信息转换模块。 i l \mathbf{i}_{l} il, o l \mathbf{o}_{l} ol, f l \mathbf{f}_{l} fl分别为输入门,输出门和遗忘门。利用记忆状态,最后一个状态 h L \mathbf{h}_{L} hL就能表示整个路径。最后本文使用两个全连接层把最终状态映射为预测得分:
s ( τ ∣ p k ) = W 2 ⊤ ReLU ( W 1 ⊤ p k ) s\left( \tau \mid \mathbf{p}_{k} \right) = \mathbf{W}_{2}^{\top}\text{ReLU}\left( \mathbf{W}_{1}^{\top}\mathbf{p}_{k} \right) s(τ∣pk)=W2⊤ReLU(W1⊤pk)
- 池化层。
组合多个路径并输出最终评分。用户item对通常有很多个路径,令 S = { s 1 , s 2 , ⋯ , s K } \mathcal{S =}\left\{ s_{1},s_{2},\cdots,s_{K} \right\} S={s1,s2,⋯,sK}表示K个路径的预测分数,最终的预测值为:
y ^ u i = σ ( 1 K ∑ k = 1 K s k ) {\widehat{y}}_{ui} = \sigma \left( \frac{1}{K} \sum_{k = 1}^{K} s_{k} \right) y ui=σ(K1k=1∑Ksk)
有研究表明,不同的路径对于用户偏好有着不同的贡献,在上式中并没有体现这一点,因此作者设计了一个带权池化操作:
g ( s 1 , s 2 , ⋯ , s K ) = log [ ∑ k = 1 K exp ( s k γ ) ] g\left( s_{1},s_{2},\cdots,s_{K} \right) = \log\left\lbrack \sum_{k = 1}^{K}\exp\left( \frac{s_{k}}{\gamma} \right) \right\rbrack g(s1,s2,⋯,sK)=log[k=1∑Kexp(γsk)]
其中 γ \gamma γ是控制每个指数权值的超参数。那么,最终的预测分为:
y ^ u i = σ ( g ( s 1 , s 2 , ⋯ , s K ) ) {\widehat{y}}_{ui} = \sigma\left( g\left( s_{1},s_{2},\cdots,s_{K} \right) \right) y ui=σ(g(s1,s2,⋯,sK))
这样的池化能够区分路径的重要性。池化函数给予了预测函数更大的灵活性,当 γ \gamma γ趋于0时,该函数退化为最大池化;当 γ \gamma γ趋于无穷时,该函数变为平均池化。
本文中,作者将推荐任务视为二分类问题,观察到的user-item交互value为1,否则为0。KPRN模型目标函数如下:
L = − ∑ ( u , i ) ∈ O + log y ^ u i + ∑ ( u , j ) ∈ O − log ( 1 − y ^ u j ) \mathcal{L = -}\sum_{(u,i) \in \mathcal{O}^{+}}^{}\log{\widehat{y}}_{ui} + \sum_{(u,j) \in \mathcal{O}^{-}}^{} \log\left( 1 - {\widehat{y}}_{uj} \right) L=−(u,i)∈O+∑logy ui+(u,j)∈O−∑log(1−y uj)
其中, O + = { ( u , i ) ∣ y u i = 1 } \mathcal{O}^{+} = \left\{ (u,i) \mid y_{ui} = 1 \right\} O+={(u,i)∣yui=1}和 O − = { ( u , j ) ∣ y u j = 0 \mathcal{O}^{-} = \left\{ (u,j) \mid y_{uj} = \right.\ 0 O−={(u,j)∣yuj= 0分别为正样本和负样本。这里为了简单,省略了L2正则项(避免过拟合)。
实验
本文使用了三个数据集:电影领域MovieLens-1M和IMDb;音乐领域KKBox。表一中为数据集相关信息。
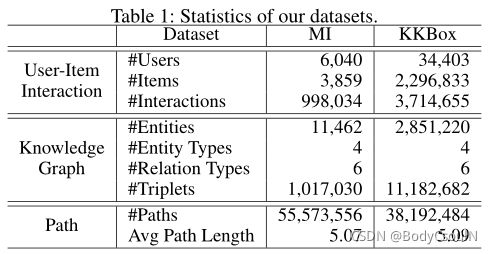
对于user-item之间的路径,有研究发现,路径超过6会产生不必要的噪音实体,因此本文路径长度最大为6。
选取了4个baseline:MF、NFM、CKE、FMG。
实验结果如图三所示。

可以看出KPRN模型的效果是最好的,通过利用路径来推断用户偏好,KPRN能够明确user-item的连接。
方法总结
本文将user、item作为实体融入知识图谱中,user-item之间的interact作为并入关系中,从而得到知识图谱中从user到item的路径。
然后先进行embedding,embedding中将实体的type也进行了嵌入,这是否有必要?因为关系中已经包含了实体与下一个实体之间的语义联系。
得到embedding后,由于路径中存在着一个序列关系,因此使用LSTM得到路径的representation。
另外考虑到每个路径的重要性不同,因此使用一个加权的池化层得到最终的预测分数,这里的预测分数可以看作是对user-item间的interact的可信度。
因为有了路径的关系,推荐的可解释性也得到了解决。
缺陷
缺点在于
- 路径提取方法非常的耗时耗力。
- 推荐的结果很大程度上依赖于路径的质量。