论文笔记|Unsupervised Key-phrase Extraction and Clustering for Classification Scheme in Scientific Pu...
导读
这是一篇发表在SDU@AAAI 2021 workshop上的论文。研究主要面向科学出版物(以下简称论文),使用无监督学习的方法,自动从科学论文中抽取关键词,并依据这些关键词形成分类体系。本文的贡献主要在于提出了一套从科学论文中提取关键词以生成分类体系的方法,再提取关键词时,作者提出了多个用来评估提取关键词时用于排序的评分,也是本文的创新点。论文链接
一、研究背景
在研究中,通过以结构化和组织化的方式对领域知识进行信息组织,学者们可以获取领域研究的重要动态、知识和见解。在以往的方式中,这样结构化的组织多由领域的专家手工来完成,但随着近些年来文献数量的大幅提升,用手工的方法去完成结构化的信息组织变得越来越困难且耗时。
在人工的传统方法中,共分为关键词提取和形成分类体系两个步骤。在关键词提取步骤中,专家们通过精读论文提取领域中的术语,这些属于在整个研究领域是通用的,对于科学论文来说,应该倾向于抽取那些多词的表达。
本文的工作在于回答如下三个问题:
- 集成多种评分在关键词抽取中的性能表现;
- 基于在语义网络的嵌入表示在词语语义表示中的效果;
- 对语义相关的关键词进行分组聚类的效果。
二、模型与方法
本文提出的关键词抽取和分类体系自动生成模型主要包含如下两个部分:
- 从标题和摘要中抽取关键词;
- 术语聚类以识别关键词的类别。
下图给出了本文模型的总体框架:

2.1 关键词抽取
本文所提出的关键词抽取模型是基于SIFRank模型改进的,SIFRank模型主要包括两个:1)通过词性标注抽取名词性短语作为候选关键词;2)计算候选关键词与文档在词向量嵌入上的余弦相似度,从而完成候选关键词的打分和排序。本文的关键词抽取模型在打分的时候,使用了三个指标:
- 文档相关性指标;
- 领域相关性指标;
- 短语质量指标。
其中,文档相似程度是从SIFRank模型得来。下面介绍这三个评分的具体情况。
2.1.1 文档相关性指标
由于作者是直接使用了SIFRank的模型,不属于本文的具体贡献和创新点,在这里只简要介绍SIFRank的思想,不深入展开内部的计算机理。SIFRank通过词性标注,预先筛选出那些是名词性短语(Noun Phrase, NP)的关键词作为候选关键词;之后使用基于BERT改进的ELMo预选连模型对候选的关键词和整篇文档做一定向量空间上的语义表征;而后计算各个候选关键词和整篇文档在嵌入向量上的余弦相似度,从而完成对候选关键词的排序。
但在本文中,作者根据科技论文的特性,认为有代表性的关键词一般出现在标题中。因此基于SIFRank模型产生的得分后,作者对候选关键词的得分依据是否出现在标题中进行了加权。这个权重是由候选关键词包含的单词数量决定的。
2.1.2 领域相关性指标
由于作者是对某一特定领域(文中是可解释人工智能)进行分类体系构建,本文考虑了关键词与领域中词汇的相关性。作者认为,应该抽取那些与目标领域语料库中词语相似而于其他领域语料库中词语不相似的候选关键词。本文构建了<可解释人工智能>研究领域的词汇表,其主要来源与两个公开的知识图谱:
- Dessi等人于2020年提出的人工智能知识图谱。作者选择了那些与<人工智能>有直接关联的关键词;
- 清华大学唐杰老师团队的Aminer。
本文对所有的候选关键词分别计算了与词汇表中术语的语义相似度,其详细过程如下:
- 基于预训练模型获取获选关键词和词汇表中术语的语义嵌入表示;
- 对于候选关键词集合中的每一个关键词,计算其与词汇表中每一个术语的余弦相似度;
- 对于候选关键词集合中的每一个关键词,其领域相关性得分为,大小前50%余弦相似度的平均值。
2.1.3 短语质量指标
作者结合科研实践, 认为高质量的短语通常情况下是由多个词语组成的,但有一种情况是例外,即由首字母缩写所形成的缩略短语,如GAN、BERT等。因此,在短语质量方面,作者依据短语的长度对短语质量得分进行惩罚,这里的目的是为了降低那些只有一个词语的短语和特别长的短语的质量得分。作者认为,最好的那些关键词一般都由2-3个词语组成,因此对于短语 ,作者构建了长度得分
,作者构建了长度得分![]() 。但是对于那些缩略词,由于其具有一定的特征,如全部都是大写字母,对于长度的惩罚不会应用到这些候选关键词上。
。但是对于那些缩略词,由于其具有一定的特征,如全部都是大写字母,对于长度的惩罚不会应用到这些候选关键词上。
另外,作者在考量短语质量的时候,还使用了逐点互信息(Point-wise mutual information, PMI)和左右邻接信息熵。其中PMI用来筛选那些低频率的短语,而信息熵用于最终评分。PMI是基于条件概率利用词语之间的共现关系的评分方式,在本文中,对于短语explainable artificial intelligence, 其基于PMI的评分为PMI(x=explainable artificial, y=intelligence)和PMI(x=explainable, y=artificial intelligence)中较小的那个值。通过PMI的值进行筛选后,本文对候选关键词计算了左右信息熵![]() ,其中
,其中![]() 代表邻接的token。这个信息熵越大,越能代表词语的质量高。在本文中,作者同时计算了左邻接信息熵和右邻接信息熵,选取其中较小的那个值作为短语的信息熵评分。
代表邻接的token。这个信息熵越大,越能代表词语的质量高。在本文中,作者同时计算了左邻接信息熵和右邻接信息熵,选取其中较小的那个值作为短语的信息熵评分。
最终,基于以上两点,短语的质量评分可由信息熵得分与短语长度惩罚二者的和构成。
2.2 关键词聚类
在本文中,对于所有的关键词,本文基于他们的语义信息(嵌入表示)作为关键词的表征信息,完成关键词的聚类。本文中,作者使用了两种聚类方法,一种是球面的k均值聚类,另一种是层次聚类。这两种聚类的区别在于,球面的k均值聚类需要规定超参数k,并且最终聚类的类别是没有层次体系的;而层次聚类不需要指定超参数,并且最终形成的分类体系是有层次地。至于为何使用球面上的k均值聚类,是因为研究表明对于文本来说,在球面上的高维向量余弦相似度能够完成更好的特征表示。
三、技术与实现细节
3.1 数据来源
本文的数据来源于IEEE Xplore在可解释人工智能领域下的286篇科技论文,提取了其标题和摘要,将标题和摘要合并作为论文的文本特征。另外IEEE Xplore提供了由人类专家指定的索引术语,这些属于将被用于关键词抽取的评估。
3.2 数据预处理
这一步骤,作者基于常用的停用词表进行了拓展,去除了文本中的停用词;此外,作者认为下划线的使用在以往研究中被证实会影响关键词的召回率,因此,作者移除了所有的下划线。
3.3 候选关键词筛选
作者使用了spaCy对文本做了词性标注,使用了如下的正则模式抽取了文本中的名词性短语,![]() 。另外对于缩略词,文章使用了ScispaCy中的缩略语抽取功能。值得注意的是,在数据预处理之前,就完成了缩略词的抽取。
。另外对于缩略词,文章使用了ScispaCy中的缩略语抽取功能。值得注意的是,在数据预处理之前,就完成了缩略词的抽取。
3.4 候选关键词排序
这一部分的内容在第二章内已经介绍。值得注意的是,通过阅读文章的源代码,作者对三个指标分别赋予了不同的权重,最终的得分是三个指标的加权得分。通过得分,抽取出每一篇文章的关键词。
3.5 用于聚类的候选关键词选取
在输入聚类器之前,先需要确定用于聚类的关键词集合,作者使用了如下的规则来挑选关键词:
- 对同义词进行分辨,对于一组同义词,只取其中得分较高的那个表示;
- 关键词在所出现的文档中平均排序超过15;
- 将缩略词替换为其原始表示;
- 根据TF-IDF值去除后20%的关键词。
3.6 聚类算法
聚类算的的实现使用sklearn和spherecluster两个库。对于每个词语,其表示来源于ConceptNet Numberbatch。对于k均值聚类,尝试了k值由5-100。
3.7 评价指标
对于关键词抽取任务,评价指标为precision、recall和F1值。而对于关键词聚类,使用了silhouette coefficient score来评估各个类表之间的分离程度。
四、实验
首先,作者对比了三个评价指标结合,对于以往单一指标的效果。可以看出多个指标能够在一定程度上提升抽取的效果。

其次,作者比较了不同类别的词嵌入对于抽取的效果影响。可以看出ConceptNet上的语义表示能够取得更好的效果。
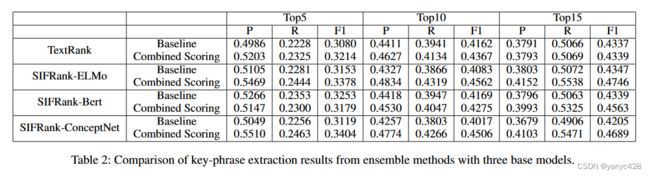
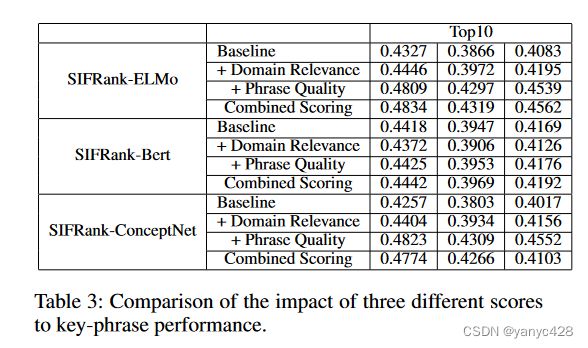
此外,作者还将新提出的两种指标分别加入原先的模型,比较加入新指标之后模型的性能改善。可以看出,两个指标对于模型确实是有实打实的改进。
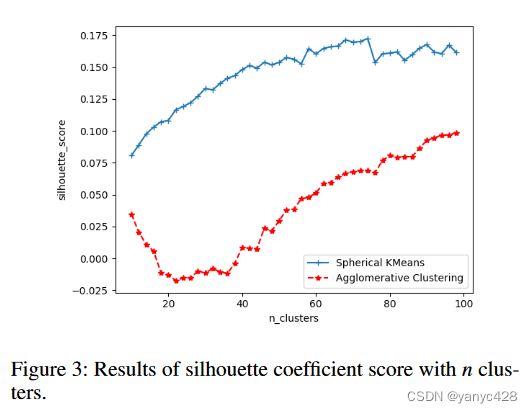
此外,作者对比了两种聚类方法的轮廓系数。可以看出球面的k均值聚类方法能够取得更好的聚类效果。
五、总结和想法
本文的贡献在于提出了领域相关性指标和短语质量指标用于关键词抽取,并在可解释的人工智能领域构建了分类体系,总的来说,文章中提出的两个score还是很有启发性的。阅读论文后,我也有一些拙见:
- 本文所提出的方法只能用于某一特定领域,如果扩展到更加宽广的领域,如整个的信息科学,可能效果会不如人意,这在目前学科深度交叉和融合的背景下,是值得面对的一个问题。
- 本文在评估短语质量时所提出的长度惩罚过于理想化,感觉作者深耕计算机领域太久了,没有考虑其他领域的情况,例如对于化学领域,光元素周期表就有一百多个单字,这个想法可能并不适用于所有的领域。
- 作者在短语质量评估部分对于PMI和信息熵的解释不够,文章中甚至还出现了错误,这一部分通过阅读代码,才能明白其大致的意思,并且这一部分有一些阈值是人为设置的,也没有进行灵敏度的分析,参数缺乏可解释性,感觉文章避重就轻了。
- 在科研实践中,学者应该更加倾向于去获得一个层次的分类体系,因此k-means的聚类方法我认为在这个地方是不能够满足需求的。