少样本苹果分类机器深度学习
场景:
样本少,且只有部分进行了标注。负样本类别(不是被标注的那些)不可穷尽,图像处理
步骤:
1,数据增强,扩充确认为普通苹果的样本数量
2,特征提取,使用VGG16模型提取图像特征
3,Kmeans模型尝试普通/其他苹果聚类,查看效果
4,Meanshift模型提升模型表现
5,数据降维PCA处理,提升模型表现
环境:
使用conda 安装:
tensorflow-gpu 2.10.1
keras 2.10.0
使用pip安装:
numpy
scipy
matplotlib
scikit-learn
操作解释:
1,因为数据量太少了,需要对数据进行增强 :有多种方式,旋转,平移,换色等。
2,准备数据集。找一个文件夹,单独建一个文件夹存放标注的样本
文件夹中只存放普通苹果的样本。
将增强生成的图片可以放到另一个train_data 文件夹中,然后在该文件夹中放入其他类型的苹果,最终结果如下:

使用代码:
#对数据进行增强
from keras.preprocessing.image import ImageDataGenerator
path = "E:\\BaiduNetdiskDownload\\DataSet\\Apple"
dst_path = "E:\\BaiduNetdiskDownload\\DataSet\\GenApple"
data_gen = ImageDataGenerator(rotation_range=10, #这个表示旋转
width_shift_range=0.1,
height_shift_range=0.02,
horizontal_flip=True, #水平翻转
vertical_flip=True) #垂直翻转
gen = data_gen.flow_from_directory(path, target_size=(224, 224),
batch_size=2, # 表示每轮循环生成两张照片。
save_to_dir=dst_path,
save_prefix="gen",
save_format="jpg")
for i in range(100):
gen.next()
可以使用如下代码加载查看:
#from keras.preprocessing.image import load_img,img_to_array #因为keras版本的缘故,无法适用load_img等方法,使用下面的utils进行加载。
from keras.utils import load_img, img_to_array
img_path = "E:\\BaiduNetdiskDownload\\DataSet\\train_data\\1.jpg"
img = load_img(img_path, target_size=(224, 224)) #224 大小是vgg16模型的适用的
from matplotlib import pyplot as plt
plt.imshow(img)
img = img_to_array(img)
print(img.shape)
3,使用VGG16,提取特征
# 加载模型,提取特征
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
model_vgg = VGG16(weights="imagenet", include_top=False)
X = np.expand_dims(img, axis=0) #增加一个维度
X = preprocess_input(X) #预处理vgg可以使用
features = model_vgg.predict(X) # 这一步就是借助vgg16提取图片的特征
features = features.reshape(1, 7*7*512) #这一步就相当于全连接层的展开。
4,上面两段代码只是用vgg提取了单个图片的特征,下面用代码批量提取图片的特征。
#上面是逐个对图片进行提取特征
import os
import numpy as np
folder = "E:\\BaiduNetdiskDownload\\DataSet\\train_data"
dirs = os.listdir(folder)
img_path = []
for i in dirs:
img_path.append(folder + "\\" + i)
def featureProcess(img_path, model):
img = load_img(img_path,target_size=(224,224))
img = img_to_array(img)
X = np.expand_dims(img, axis=0)
X = preprocess_input(X) #处理成VGG16可以处理的格式。
X_VGG = model.predict(X)
X_VGG = X_VGG.reshape(1, 7*7*512)
return X_VGG
features_train = np.zeros([len(img_path), 7*7*512]) #这里
for i in range(len(img_path)):
features_i = featureProcess(img_path[i], model_vgg)
features_train[i] = features_i
X = features_train
print(type(X))
print(X.shape) #230个苹果,10个普通的200个增强的,其他的是多余的
5,使用kmeans算法预测分类。
# 使用kmeans 模型进行聚类。 使用k均值聚类算法。
from sklearn.cluster import KMeans
cnn_kmeans = KMeans(n_clusters=2, max_iter=2000) #分为两类, 最大迭代次数是2000次
cnn_kmeans.fit(X)
y_predict_kmeans = cnn_kmeans.predict(X) # 这里只是得到的 0 1 的预测结果,需要统计一下0,1各自的数量
from collections import Counter #计数器,统计聚类算法分类对应的个数
print(Counter(y_predict_kmeans))
使用下面的代码可视化查看效果
normal_apple_id = 1
fig2 = plt.figure(figsize=(10,40))
for i in range(45):
for j in range(5):
img = load_img(img_path[i*5 + j])
plt.subplot(45,5, i*5 +j +1)
plt.title("apple" if y_predict_kmeans[i*5 +j]== normal_apple_id else "other")
plt.imshow(img)
plt.axis("off") # 这个的功能是去掉坐标和边框
# 会发现预测效果不是很好

6,效果太差,尝试换一个聚类算法,使用MeanShift
# 预测效果太差,尝试换一个聚类算法,来查看效果
from sklearn.cluster import MeanShift, estimate_bandwidth
bw = estimate_bandwidth(X, n_samples = 140) #均值漂移算法先确定,需要以多大宽度进行搜索
# 每140个样本作为一个搜索。
cnn_ms = MeanShift(bandwidth = bw)
cnn_ms.fit(X)
y_predict_ms = cnn_ms.predict(X)
from collections import Counter
print(Counter(y_predict_ms))
可视化查看
normal_apple_id = 0
fig3 = plt.figure(figsize=(10,40))
for i in range(45):
for j in range(5):
img = load_img(img_path[i*5 + j])
plt.subplot(45,5, i*5 +j +1)
plt.title("apple" if y_predict_ms[i*5 +j]== normal_apple_id else "other")
plt.imshow(img)
plt.axis("off") # 这个的功能是去掉坐标和边框
# 效果改善了非常多

7,效果有所改善,可以继续进一步优化。因为一个模型的好坏更多取决于数据,数据多了后难免会有许多噪点。所以我们应该想怎么样去除它们,去除异常点,PCA降维都可以。
# 效果虽然改善了,但是还有其他维度没有去除,肯定是存在噪点的。所以采用PCA进行降维去噪
from sklearn.preprocessing import StandardScaler
stds = StandardScaler()
X_norm = stds.fit_transform(X) #标准化
from sklearn.decomposition import PCA
pca = PCA(n_components=200) # n_components 指定要降到的维度
X_pca = pca.fit_transform(X_norm)
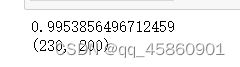
var_ratio = pca.explained_variance_ratio_ # 获取pca处理后各维度的方差比例
print(np.sum(var_ratio))
print(X_pca.shape)
再使用MeanShift进行预测:
from sklearn.cluster import MeanShift, estimate_bandwidth
bw = estimate_bandwidth(X_pca, n_samples = 140)
cnn_pca_ms = MeanShift(bandwidth = bw)
cnn_pca_ms.fit(X_pca)
y_predict_pcs_ms = cnn_pca_ms.predict(X_pca)
normal_apple_id = 0
fig4 = plt.figure(figsize=(10,40))
for i in range(45):
for j in range(5):
img = load_img(img_path[i*5 + j])
plt.subplot(45,5, i*5 +j +1)
plt.title("apple" if y_predict_pcs_ms[i*5 +j]== normal_apple_id else "other")
plt.imshow(img)
plt.axis("off") # 这个的功能是去掉坐标和边框