MapReduce高级编程(计数器、mysql读写、join、工作流)
文章目录
-
-
- 1 MapReduce Counter计数器
-
- 1.1 MapReduce内置计数器
- 1.2 MapReduce自定义计数器
- 2 MapReduce读写Mysql操作
-
- 2.1 读取mysql数据库
- 2.2 mysql数据库写入
- 3 MapReduce Join操作
-
- 3.1 Reduce side join
-
- mapper.java
- reducer.java
- driver.java
- 3.2 MapReduce 分布式缓存使用
- 3.3 map side join
-
- mapper.java
- driver.java
- 3.4 yarn模式运行步骤:
- 4 MapReduce 工作流
-
1 MapReduce Counter计数器
概述:
- 在执行MapReduce程序的时候,控制台输出日志中可以发现,输出信息中的核心词是counter,中文叫做计数器。
- Hadoop内置的计数器可以收集、统计程序运行中核心信息,帮助用户理解程序的运行情况,辅助用户诊断故障。
1.1 MapReduce内置计数器
概述:
- Hadoop为每个MapReduce作业维护了一些内置的计数器,报告程序执行时各种指标信息。用户可以根据这些信息进行判断程序:执行逻辑是否合理、执行结果是否正确。
- Hadoop内置计数器根据功能进行分组(Counter Group)。每个组包括若干个不同的计数器。
- Hadoop计数器都是MapReduce程序中全局的计数器,跟MapReduce分布式运算没有关系,不是所谓的局部统计信息。
- 内置Counter Group包括:MapReduce任务计数器(Map-Reduce Framework)、文件系统计数器(File System Counters)、作业计数器(Job Counters)、输入文件任务计数器(File Input Format Counters)、输出文件计数器(File Output Format Counters)。
MapReduce任务计数器:
该组计数器主要统计MapReduce框架执行中各个阶段的输入输出信息。
| 计数器名字 | 说明 |
|---|---|
| MAP_INPUT_RECORDS | 所有mapper已处理的输入记录数 |
| MAP_OUTPUT_RECORDS | 所有mapper产生的输出记录数 |
| MAP_OUTPUT_BYTES | 所有mapper产生的未经压缩的输出数据的字节数 |
| COMBINE_INPUT_RECORDS | 所有combiner(如果有)已处理的输入记录数 |
| COMBINE_OUTPUT_RECORDS | 所有combiner(如果有)已产生的输出记录数 |
| REDUCE_INPUT_GROUPS | 所有reducer已处理分组的个数 |
| REDUCE_INPUT_RECORDS | 所有reducer已经处理的输入记录的个数。每当某个reducer的迭代器读一个值时,该计数器的值增加 |
| REDUCE_OUTPUT_RECORDS | 所有reducer输出记录数 |
| REDUCE_SHUFFLE_BYTES | Shuffle时复制到reducer的字节数 |
文件系统计数器:
文件系统的计数器会针对不同的文件系统使用情况进行统计,比如HDFS、本地文件系统
| 计数器名字 | 说明 |
|---|---|
| BYTES_READ | 程序从文件系统中读取的字节数 |
| BYTES_WRITTEN | 程序往文件系统中写入的字节数 |
| READ_OPS | 文件系统中进行的读操作的数量(例如,open操作,filestatus操作) |
| LARGE_READ_OPS | 文件系统中进行的大规模读操作的数量 |
| WRITE_OPS | 文件系统中进行的写操作的数量(例如,create操作,append操作) |
作业计数器:
主要统计记录MapReduce 任务启动的task情况,包括:个数、使用资源情况等。
| 计数器名字 | 说明 |
|---|---|
| Launched map tasks | 启动的map任务数,包括以“推测执行”方式启动的任务 |
| Launched reduce tasks | 启动的reduce任务数,包括以“推测执行”方式启动的任务 |
| Data-local map tasks | 与输人数据在同一节点上的map任务数 |
| Total time spent by all maps in occupied slots (ms) | 所有map任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all reduces in occupied slots (ms) | 所有reduce任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all map tasks (ms) | 所有map task花费的时间 |
| Total time spent by all reduce tasks (ms) | 所有reduce task花费的时间 |
输入/输出文件任务计数器:
| 计数器名字 | 说明 |
|---|---|
| 读取的字节数(BYTES_READ) | 由map任务通过FilelnputFormat读取的字节数 |
| 写的字节数(BYTES_WRITTEN) | 由map任务(针对仅含map的作业)或者reduce任务通过FileOutputFormat写的字节数 |
1.2 MapReduce自定义计数器
概述:
- Hadoop内置的计数器还是比较全面的,给作业运行过程的监控带了方便。
- 但是对于一些业务中的特定要求,比如统计程序执行中某种情况出现次数进行统计,则内置的无法实现。
- 为此,MapReduce提供了用户编写自定义计数器的方法。
- 最重要的是,计数器是全局的统计,避免了用户自己维护全局变量的不利性。
使用:
- 通过context.getCounter方法获取一个全局计数器,创建的时候需要指定计数器所属的组名和计数器的名字。
- 在程序中需要使用计数器的地方,调用counter提供的方法即可,比如+1操作。
- 在执行程序的时候,在控制台输出的信息上就有自定义计数器组和计数器统计信息。
示例:
//从程序的上下文环境中获取一个全局计数器,指定计数器所属组的名字,计数器的名字
Counter counter = context.getCounter("group_counters", "wrx count");
//计数器的使用
if("wrx".equals(word)){
counter.increment(1);
}
控制台出现了自定义计数器的输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jW1FsT0Z-1668775401000)(assets/image-20221117144052938.png)]
2 MapReduce读写Mysql操作
2.1 读取mysql数据库
DBInputFormat类:
- DBInputFormat类用于从SQL表读取数据。底层一行一行读取表中的数据,返回
- 其中k是LongWritable类型,表中数据的记录行号,从0开始;
- 其中v是DBWritable类型,表示该行数据对应的对象类型。
GoodsBean.java
使用GoodBean 用于封装查询返回的结果(如果要查询表的所有字段,那么属性就跟表的字段一一对应即可)。
- 需要实现setter、getter、toString、构造方法。
- 实现Hadoop序列化接口Writable和数据库读取和写入的实现的DBWritable接口
DBWritable与Writable相似,区别在于write(PreparedStatement)方法采用PreparedStatement,而readFields(ResultSet)采用ResultSet。
package mysql_MR_read;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class GoodsBean implements Writable, DBWritable {
private long goodsId;
private String goodsSn;
private String goodsName;
private double marketPrice;
private double shopPrice;
private long saleNum;
public GoodsBean() {
}
public GoodsBean(long goodsId, String goodsSn, String goodsName, double marketPrice, double shopPrice, long saleNum) {
this.goodsId = goodsId;
this.goodsSn = goodsSn;
this.goodsName = goodsName;
this.marketPrice = marketPrice;
this.shopPrice = shopPrice;
this.saleNum = saleNum;
}
public void set(long goodsId, String goodsSn, String goodsName, double marketPrice, double shopPrice, long saleNum) {
this.goodsId = goodsId;
this.goodsSn = goodsSn;
this.goodsName = goodsName;
this.marketPrice = marketPrice;
this.shopPrice = shopPrice;
this.saleNum = saleNum;
}
public long getGoodsId() {
return goodsId;
}
public void setGoodsId(long goodsId) {
this.goodsId = goodsId;
}
public String getGoodsSn() {
return goodsSn;
}
public void setGoodsSn(String goodsSn) {
this.goodsSn = goodsSn;
}
public String getGoodsName() {
return goodsName;
}
public void setGoodsName(String goodsName) {
this.goodsName = goodsName;
}
public double getMarketPrice() {
return marketPrice;
}
public void setMarketPrice(double marketPrice) {
this.marketPrice = marketPrice;
}
public double getShopPrice() {
return shopPrice;
}
public void setShopPrice(double shopPrice) {
this.shopPrice = shopPrice;
}
public long getSaleNum() {
return saleNum;
}
public void setSaleNum(long saleNum) {
this.saleNum = saleNum;
}
@Override
public String toString() {
return "GoodsBean{" +
"goodsId=" + goodsId +
", goodsSn='" + goodsSn + '\'' +
", goodsName='" + goodsName + '\'' +
", marketPrice=" + marketPrice +
", shopPrice=" + shopPrice +
", saleNum=" + saleNum +
'}';
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(goodsId);
dataOutput.writeUTF(goodsSn);
dataOutput.writeUTF(goodsName);
dataOutput.writeDouble(marketPrice);
dataOutput.writeDouble(shopPrice);
dataOutput.writeLong(saleNum);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.goodsId = dataInput.readLong();
this.goodsSn = dataInput.readUTF();
this.goodsName = dataInput.readUTF();
this.marketPrice = dataInput.readDouble();
this.shopPrice = dataInput.readDouble();
this.saleNum = dataInput.readLong();
}
@Override
public void write(PreparedStatement preparedStatement) throws SQLException {
preparedStatement.setLong(1,goodsId);
preparedStatement.setString(2,goodsSn);
preparedStatement.setString(3,goodsName);
preparedStatement.setDouble(4,marketPrice);
preparedStatement.setDouble(5,shopPrice);
preparedStatement.setLong(6,saleNum);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.goodsId = resultSet.getLong(1);
this.goodsSn = resultSet.getString(2);
this.goodsName = resultSet.getString(3);
this.marketPrice = resultSet.getDouble(4);
this.shopPrice = resultSet.getDouble(5);
this.saleNum = resultSet.getLong(6);
}
}
Mapper.java(不需要做任何的操作,只需要输出即可)
注意:
key为LongWritable类型,表示数据的记录行号,从0开始。
value为DBWritable类型,表示该行数据对应的对象类型。
package mysql_MR_read;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class mapper extends Mapper<LongWritable,GoodsBean,LongWritable, Text> {
LongWritable outputKey = new LongWritable();
Text outputValue = new Text();
@Override
protected void map(LongWritable key, GoodsBean value, Context context) throws IOException, InterruptedException {
outputKey.set(key.get());
outputValue.set(value.toString());
context.write(outputKey,outputValue);
}
}
driver.java
package mysql_MR_read;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DBConfiguration.configureDB(
conf,
"com.mysql.jdbc.Driver",
"jdbc:mysql://node1/test",
"root",
"123456"
);
Job job = Job.getInstance(conf, driver.class.getSimpleName());
job.setJarByClass(driver.class);
job.setInputFormatClass(DBInputFormat.class);
Path out = new Path("E:\\InAndOut\\hadoop\\Output\\readMysql");
FileOutputFormat.setOutputPath(job,out);
//判断输出路径是否存在
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)){
fs.delete(out,true);
}
job.setMapperClass(mapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
DBInputFormat.setInput(
job,
GoodsBean.class,
"select goodsId,goodsSn,goodsName,marketPrice,shopPrice,saleNum from itheima_goods",
"select count(goodsId) from itheima_goods"
);
//提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag?0:1);
}
}
2.2 mysql数据库写入
DBOutputFormat类:
- DBOutputFormat ,它将reduce输出发送到SQL表。
- DBOutputFormat接受
键值对,其中key必须具有扩展DBWritable的类型。
使用jdbc创建数据库表:
package mysql_MR_write;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class CreateTable {
private static final String CreateSQL = "CREATE TABLE `itheima_goods_mr_write` (\n" +
" `goodsId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',\n" +
" `goodsSn` varchar(20) NOT NULL COMMENT '商品编号',\n" +
" `goodsName` varchar(200) NOT NULL COMMENT '商品名称',\n" +
" `marketPrice` decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '市场价',\n" +
" `shopPrice` decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '门店价',\n" +
" `saleNum` int(11) NOT NULL DEFAULT '0' COMMENT '总销售量',\n" +
" PRIMARY KEY (`goodsId`)\n" +
" ) ENGINE=InnoDB AUTO_INCREMENT=115909 DEFAULT CHARSET=utf8";
public static void main(String[] args) throws Exception {
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection(
"jdbc:mysql://node1/test", "root", "123456"
);
Statement stmt = conn.createStatement();
stmt.execute(CreateSQL);
stmt.close();
conn.close();
}
}
mapper.java
package mysql_MR_write;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// 在使用DBoutputFormat的时候,要求输出的key必须是DBWritable的实现,因为只会把key写入数据库
public class mapper extends Mapper<LongWritable,Text,GoodsBean,NullWritable> {
NullWritable outputKey = NullWritable.get();
GoodsBean outPutValue = new GoodsBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//设置两个计数器来记录写入是否成功
final Counter sc = context.getCounter("mr_sql_counters", "SUCCESS");
final Counter fc = context.getCounter("mr_sql_counters", "FAILED");
//解析输入数据
String[] sl = value.toString().split("\\s+");
if(sl.length == 7){
outPutValue.set(
Long.parseLong(sl[1]),
sl[2],
sl[3],
Double.parseDouble(sl[4]),
Double.parseDouble(sl[5]),
Long.parseLong(sl[6])
);
context.write(outPutValue,outputKey);
sc.increment(1);
}else fc.increment(1);
}
}
Driver.java
package mysql_MR_write;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DBConfiguration.configureDB(
conf,
"com.mysql.jdbc.Driver",
"jdbc:mysql://node1/test?useUnicode=true&characterEncoding=utf8",
"root",
"123456"
);
Job job = Job.getInstance(conf, Driver.class.getSimpleName());
job.setJarByClass(Driver.class);
//mapper设置
job.setMapperClass(mapper.class);
job.setMapOutputKeyClass(GoodsBean.class);
job.setMapOutputValueClass(NullWritable.class);
//reducer设置
job.setNumReduceTasks(0);
//设置输入
FileInputFormat.setInputPaths(job,new Path("E:\\InAndOut\\hadoop\\Input\\part-m-00000"));
//设置输出的类型
job.setOutputFormatClass(DBOutputFormat.class);
DBOutputFormat.setOutput(
job,
"itheima_goods_mr_write",
"goodsId", "goodsSn", "goodsName", "marketPrice", "shopPrice","saleNum"
);
//提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag?0:1);
}
}
3 MapReduce Join操作
概述:
- 在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时就可以使用SQL语句中的连接(JOIN),在两个或多个数据表中查询数据。
- 在使用MapReduce框架进行数据处理的过程中,也会涉及到从多个数据集读取数据,进行join关联的操作,只不过此时需要使用java代码并且根据MapReduce的编程规范进行业务的实现。
- 由于MapReduce的分布式设计理念,对于MapReduce实现join操作具备了一定的特殊性。
- 特殊主要体现在:究竟在MapReduce中的什么阶段进行数据集的关联操作,是mapper阶段还是reducer阶段,之间的区别又是什么?
- 基于此,整个MapReduce的join分为两类:Map Side Join、Reduce Side Join。
3.1 Reduce side join
概述:
- reduce side join,顾名思义,在reduce阶段执行join关联操作。
- 这也是最容易想到和实现的join方式。因为通过shuffle过程就可以将相关的数据分到相同的分组中,这将为后面的join操作提供了便捷。
步骤:
- mapper分别读取不同的数据集;
- mapper的输出中,通常以join的字段作为输出的key;
- 不同数据集的数据经过shuffle,key一样的会被分到同一分组处理;
- 在reduce中根据业务需求把数据进行关联整合汇总,最终输出。
弊端:
- reduce端join最大的问题是整个join的工作是在reduce阶段完成的,但是通常情况下MapReduce中reduce的并行度是极小的(默认是1个),这就使得所有的数据都挤压到reduce阶段处理,压力颇大。虽然可以设置reduce的并行度,但是又会导致最终结果被分散到多个不同文件中。
- 并且在数据从mapper到reducer的过程中,shuffle阶段十分繁琐,数据集大时成本极高。
问题:有两份结构化的文件:itheima_goods(商品信息)、itheima_order_goods(订单信息)。要求使用MapReduce统计出每笔订单中对应的具体的商品名称信息。
数据说明:
- itheima_goods(商品信息)字段:goodsId(商品id)、goodsSn(商品编号)、goodsName(商品名称)
- itheima_order_goods(订单信息)字段: orderId(订单ID)、goodsId(商品ID)、payPrice(实际支付价格)。
实现思路:
- 使用mapper处理订单数据和商品数据,输出的时候以goodsId号作为key。相同goodsId的商品和订单会到同一个reduce的同一个分组,在分组中进行订单和商品信息的关联合并。
- 在MapReduce程序中可以通过context获取到当前处理的切片所属的文件名称。根据文件名来判断当前处理的是订单数据还是商品数据,以此来进行不同逻辑的输出。
- join处理完之后,最后可以再通过MapReduce程序排序功能,将属于同一笔订单的所有商品信息汇聚在一起。
mapper.java
- 重点:因为输入文件为多个,而每个文件map规则不同,需要获取该文件为哪个文件。可以使用Mapper类的setup方法,它是在map方法处理前运行的。因此通过重写该方法获取当前要处理的切片的文件名称。代码如下:
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取当前处理的切片所属的文件名字
FileSplit inputSplit = (FileSplit)context.getInputSplit();
filename = inputSplit.getPath().getName();
System.out.println("当前处理的文件是"+filename);
}
- 技巧:由于涉及的变量不多,省去使用封装变量的方法,直接使用字符串拼接来合并多个变量,可以使用stringbuilder类的append方法。
- 该代码中还涉及到stringbuilder类的insert方法,两个参数,一个是插入位置,第二个是插入的字符或字符串。
package Join.reduceJoin;
import org.apache.commons.lang.text.StrBuilder;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class mapper extends Mapper<LongWritable, Text,Text,Text> {
Text outKey = new Text();
Text outValue = new Text();
StrBuilder sb = new StrBuilder();
String filename = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取当前处理的切片所属的文件名字
FileSplit inputSplit = (FileSplit)context.getInputSplit();
filename = inputSplit.getPath().getName();
System.out.println("当前处理的文件是"+filename);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清楚字符串的数据
sb.setLength(0);
String[] sl = value.toString().split("\\|");
//判断处理的是哪个文件
if (filename.contains("itheima_goods.txt")){
outKey.set(sl[0]);
sb.append(sl[1]).append("\t").append(sl[2]);
outValue.set(sb.insert(0,"goods#").toString());
context.write(outKey,outValue);
}else{
outKey.set(sl[1]);
sb.append(sl[0]).append("\t").append(sl[2]);
outValue.set(sb.insert(0,"order#").toString());
context.write(outKey,outValue);
}
}
}
reducer.java
在reduce端进行的join操作,主要是通过一些简单逻辑实现的,理解不难,直接看源码。
package Join.reduceJoin;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class reducer extends Reducer<Text,Text,Text,Text> {
//用来存放 商品编号、商品名称
List<String> goodsList = new ArrayList<>();
//用来存放 订单编号 实际支付价格
List<String> orderList = new ArrayList<>();
Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//判断相同key的value的值是
for (Text value:values){
if (value.toString().startsWith("goods#")){
String s = value.toString().split("#")[1];
goodsList.add(s);
}
if (value.toString().startsWith("order#")){
String s = value.toString().split("#")[1];
orderList.add(s);
}
}
System.out.println();
//获取2个集合的长度
int goodsize = goodsList.size();
int ordersize = orderList.size();
//两两组合,全部写出
for (int i = 0;i<ordersize;i++){
for (int j = 0;j<goodsize;j++){
outValue.set(orderList.get(i)+"\t"+goodsList.get(j));
context.write(key,outValue);
}
}
orderList.clear();
goodsList.clear();
}
}
driver.java
由于是提交的是多个文件,因此只需要将其放进同一个文件夹中,路径写到改为文件夹即可。
package Join.reduceJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class driver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
//创建作业实例
Job job = Job.getInstance(conf, driver.class.getSimpleName());
//设置作业驱动类
job.setJarByClass(driver.class);
//设置作业mapper reducer类
job.setMapperClass(mapper.class);
job.setReducerClass(reducer.class);
//设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置作业reducer阶段的输出key value数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//配置作业输入路径
FileInputFormat.addInputPath(job,new Path("E:\\InAndOut\\hadoop\\Input\\join"));
//配置作业输出路径
Path out = new Path("E:\\InAndOut\\hadoop\\Output\\join");
FileOutputFormat.setOutputPath(job,out);
//判断输出路径是否存在
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)){
fs.delete(out,true);
}
//提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag?0:1);
}
}
3.2 MapReduce 分布式缓存使用
概述:
- DistributedCache是MapReduce框架提供的一种机制,可以将job指定的文件,在job执行前,先行分发到各个task执行的机器上,并有相关机制对cache文件进行管理(比如读取缓存)。
- DistributedCache能够缓存应用程序所需的各种文件,包括text文本,Archive档案文件,jar包等。
- MapReduce框架在作业所有task执行之前会把指定的分布式缓存文件拷贝到各个Task运行的节点上。
使用方式:
- step1:添加缓存文件:可以使用MapReduce的API添加需要缓存的文件。
//添加归档文件到分布式缓存中
job.addCacheArchive(URI uri);
//添加普通文件到分布式缓存中
job.addCacheFile(URI uri);
- Step2:MapReduce程序中读取缓存文件:在Mapper类或者Reducer类的setup方法中,用BufferedReader获取分布式缓存中的文件内容。BufferedReader是带缓冲区的字符流,能够减少访问磁盘的次数,提高文件读取性能;并且可以一次性读取一行字符
protected void setup(Context context) throw IOException,InterruptedException{
FileReader reader = new FileReader("myfile");
BufferReader br = new BufferedReader(reader);
......
}
3.3 map side join
概述:
- map side join,其精髓就是在map阶段执行join关联操作,并且程序通常也没有了reduce阶段,避免了shuffle时候的繁琐。
- 实现Map端join的关键是使用MapReduce的分布式缓存。
实现思路:
- 首先分析处理的数据集,使用分布式缓存技术将小的数据集进行分布式缓存。
- MapReduce框架在执行的时候会自动将缓存的数据分发到各个maptask运行的机器上。
- 在mapper初始化的时候从分布式缓存中读取小数据集数据,然后和自己读取的大数据集进行join关联,输出最终的结果。
优势:
- 整个join的过程没有shuffle,没有reducer,减少shuffle时候的数据传输成本。
- 并且mapper的并行度可以根据输入数据量自动调整,充分发挥分布式计算的优势。
问题:有两份结构化的文件:itheima_goods(商品信息)、itheima_order_goods(订单信息)。要求使用MapReduce统计出每笔订单中对应的具体的商品名称信息。
数据说明:
- itheima_goods(商品信息)字段:goodsId(商品id)、goodsSn(商品编号)、goodsName(商品名称)
- itheima_order_goods(订单信息)字段: orderId(订单ID)、goodsId(商品ID)、payPrice(实际支付价格)。
思路分析:
- Map-side Join是指在Mapper任务中加载特定数据集,此案例中把商品数据进行分布式缓存,使用Mapper读取订单数据和缓存的商品数据进行连接。
- 通常为了方便使用,会在mapper的初始化方法setup中读取分布式缓存文件加载的程序的内存中,便于后续mapper处理数据。
- 因为在mapper阶段已经完成了数据的关联操作,因此程序不需要进行reduce。需要在job中将reducetask的个数设置为0,也就是mapper的输出就是程序最终的输出。
mapper.java
package Join.mapJoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
public class mapper extends Mapper <LongWritable, Text,Text, NullWritable>{
Map<String,String> goodsMap = new HashMap();
Text outputkey = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//读取缓存文件,注意,文件名要写成缓存文件的文件名而不是路径
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("")));
String line = null;
//将读取到的信息保存在Map集合中
while ((line = br.readLine())!=null){
String[] fileds = line.split("\\|");
goodsMap.put(fileds[0],fileds[1]+"\t"+fileds[2]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] sl = value.toString().split("\\|");
//获取缓存文件中相同key值的数据
String goodsInfor = goodsMap.get(sl[1]);
//将两个文件的数据进行拼接、输出
outputkey.set(value.toString()+"\t"+goodsInfor);
context.write(outputkey,NullWritable.get());
}
}
driver.java
注意:分布式缓存的使用必须使用MapReduce的yarn模式运行。
package Join.mapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class driver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
//创建作业实例
Job job = Job.getInstance(conf, driver.class.getSimpleName());
//设置作业驱动类
job.setJarByClass(driver.class);
//设置作业mapper reducer类
job.setMapperClass(mapper.class);
//设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
// 添加分布式缓存文件
job.addCacheFile(new URI("/data/join/itheima_goods.txt"));
//配置作业输入路径
FileInputFormat.addInputPath(job,new Path("/data/join/input"));
//配置作业输出路径
Path out = new Path("/data/join/MR_result");
FileOutputFormat.setOutputPath(job,out);
//判断输出路径是否存在
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)){
fs.delete(out,true);
}
//提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag?0:1);
}
}
3.4 yarn模式运行步骤:
step1:在工程的pom.xml文件中指定程序运行的主类全路径

step2:执行mvn package命令生成jar包
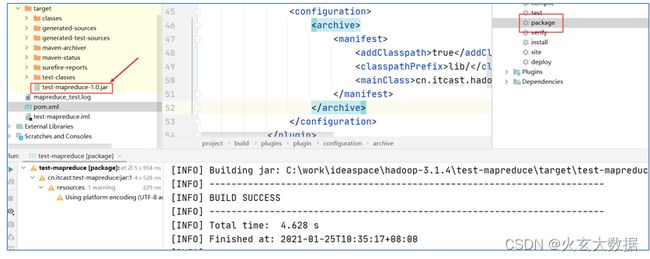
step3:将jar包上传集群执行命令:hadoop jar xxxx.jar
注意:保证yarn集群提前启动成功,以及输入文件是否存在。
4 MapReduce 工作流
概述:
- 有时候应用程序,往往需要多个MR作业,先后依次执行来计算得出最终结果。
- 比如一些数据挖掘类的作业,常常需要迭代组合好几个作业才能完成,这类作业类似于DAG的任务,各个作业之间是具有先后,或相互依赖的关系,比如说,这一个作业的输入,依赖上一个作业的输出等等。
需求分析:
- 针对MapReduce reduce join方式处理订单和商品数据之间的关联,需要进行两步程序处理,首先把两个数据集进行join操作,然后针对join的结果进行排序,保证同一笔订单的商品数据聚集在一起。
- 两个程序带有依赖关系,可以使用工作流进行任务的设定,依赖的绑定,一起提交执行。
代码实现:
step1:两个MapReduce Job准备
根据需求编写两个MapReduce程序,用于join操作和join之后结果排序操作。
step2:编写作业流程控制类
public class MrJobFlow {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//第一个作业的配置
Job job1 = Job.getInstance(conf, ReduceJoinDriver.class.getSimpleName());
……..
// 将普通作业包装成受控作业
ControlledJob ctrljob1 = new ControlledJob(conf);
ctrljob1.setJob(job1);
//第二个作业的配置
Job job2 = Job.getInstance(conf, ReduceJoinSortApp.class.getSimpleName());
……
// 将普通作业包装成受控作业
ControlledJob ctrljob2 = new ControlledJob(conf);
ctrljob2.setJob(job2);
//设置job的依赖关系
ctrljob2.addDependingJob(ctrljob1);
// 主控制容器
JobControl jobCtrl = new JobControl("myctrl");
// 添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
// 在线程启动,记住一定要有这个
Thread t = new Thread(jobCtrl);
t.start();
while(true) {
if (jobCtrl.allFinished())
System.out.println(jobCtrl.getSuccessfulJobList());
jobCtrl.stop();
break;
}
}
运行:
- 直接在驱动类中右键运行main方法,使用MapReduce的本地模式执行。
- 也可以将程序使用maven插件打包成jar包,提交到yarn上进行分布式运行。
-----------------------------------根据黑马程序员学习所总结