CBIR:图像检索初阶入门指南
Content-based Image Retrieval
图像检索入门指南
文章主要参考自李中梁大佬翻译的图像检索领域的经典综述SIFT与CNN的碰撞,本文中对一些论文中没有多加说明的基本概念加以解释并附带部分个人的见解,希望给跟我一样初次接触图像检索的朋友一些入门的参考方向,文中有不当之处还望指出。
原论文地址:arxiv
无监督图像检索:SPQ算法理解
文章目录
- Content-based Image Retrieval
-
-
- 图像检索入门指南
- 1. 概述
-
- 2. 基于SIFT特征的图像检索
-
- 2.1 局部特征提取
- 2.2 编码
-
- 2.2.1 Bag of Features
- 2.2.2 Fisher Vector
- 2.2.3 Vector of Locally Aggregated Descriptors
- 2.3 检索
- 3. 基于CNN的图像检索
-
- 3.1 使用预训练CNN模型的图像检索
-
- 3.1.1 特征提取
- 3.1.2 特征编码与池化
- 3.2 使用微调CNN模型的图像检索
-
- 3.2.1 用于微调网络的数据集
- 3.2.2 有监督微调
- 参考文献
-
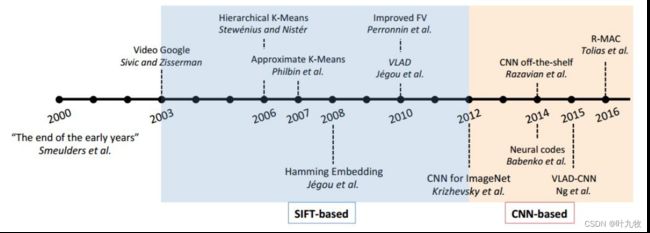
Fig1.1 图像检索里程碑
1. 概述
什么是图像检索?给定一个包含特定实例(例如特定目标、场景、建筑等)的查询图像,图像检索旨在从数据库图像中找到包含相同实例的图像。跟许多CV任务一样,图像检索任务有两个重要的时间节点(图1.1):
- 2003年,BoW(词袋模型)与SIFT(尺度不变特征变换)被应用于图像检索任务,代表着大部分传统方法的结束。
- 2012年,CNN卷积神经网络喜闻乐见的展现出了令人赞叹的性能。
围绕这两个节点,图像检索社区提出了各种各样的方法提升算法性能,但是大体上都可以归类为基于SIFT和CNN特征的两类主要方法。
2. 基于SIFT特征的图像检索
尺度不变特征转换(Scale-invariant Feature Transform, SIFT)是一种用来侦测与描述图像局部特征的算法,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量[1]。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等,SIFT特征可视化结果如图2.1所示。

Fig2.1 SIFT特征
含有位置、尺度和方向的关键点即是该图像的SIFT特征点。
词袋模型(Bag-of-Words, BoW)最初是为解决文档建模问题而提出的,它通过累加单词响应到一个全局向量来给文档建立单词直方图。词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的[2]。
在图像领域,尺度不变(SIFT)特征的引入使得BoW模型变得可行,局部特征通过SIFT算法被量化表示为视觉词汇,一张图片能够被表示成类似文档的形式,这样就可以使用经典的权重索引方案。

Fig2.2 图像检索流程
基于SIFT与CNN特征的图像检索流程。
基于SIFT的方法一般可以分为三个部分:局部特征提取、编码本训练特征编码(图2.3)。

Fig2.3 图像检索方法
基于SIFT与CNN特征的图像检索流程。
2.1 局部特征提取
局部检测器(Local detector)。局部不变特征针对精准匹配图像局部结构而提出。基于SIFT的方法和大多特征提取步骤类似,都是由特征检测器和描述符组成。检测器旨在于在多样的图像场景中定位出一系列特征稳定的局部区域,检测器类型有很多种类,这里主要介绍其中最重要的两种:关键点为中心的海森检测器(Hessian detector),以寻找尺度不变区域为目标的高斯差分检测器(DoG detector),一个经典的高斯差分金字塔如图2.4所示。
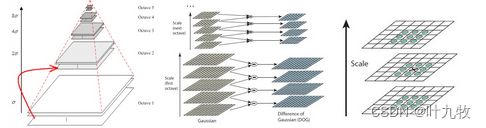
Fig2.4 高斯差分金字塔
为了让尺度体现其连续性,高斯金字塔在简单降采样的基础上加上了高斯滤波。金字塔每层只有一组图像,组数和金字塔层数相等。 为了寻找DoG函数的极值点,每一个像素点要和它所有的相邻点比较,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。
而目前的首选方案是寻找图像仿射协变区域的仿射检测器,它之所以称之为“协变的”是因为检测区域随着仿射变化而改变,因此区域描述符具有不变性,大名鼎鼎的海森仿射检测器就是这个类型。
海森检测器是海森矩阵的一个重要的应用,那么什么是海森矩阵?海森矩阵实际上就是空间中一点处的二阶导数[3]。在二维图像中,假设图像像素值关于坐标 ( x , y ) (x,y) (x,y)的函数是 f ( x , y ) f(x,y) f(x,y),那么将 f ( x + d x , y + d y ) f(x+dx, y+dy) f(x+dx,y+dy)在 f ( x 0 , y 0 ) f(x_0,y_0) f(x0,y0)处进行泰勒展开可以得到如下公式(舍去了皮亚诺余项)。
f ( x , y ) ≈ f ( x 0 , y 0 ) + [ δ x δ y ] [ f x ( x 0 , y 0 ) f y ( x 0 , y 0 ) ] + 1 2 ! [ δ x δ y ] [ f x x ( x 0 , y 0 ) f x y ( x 0 , y 0 ) f y x ( x 0 , y 0 ) f y y ( x 0 , y 0 ) ] [ δ x δ y ] f(x,y) \approx f(x_0,y_0)+ \begin{bmatrix} \delta x&\delta y \end{bmatrix} \begin{bmatrix} f_x(x_0, y_0) \\ f_y(x_0, y_0) \end{bmatrix} + \frac{1}{2!} \begin{bmatrix} \delta x&\delta y \end{bmatrix} \begin{bmatrix} f_{xx}(x_0,y_0)&f_{xy}(x_0,y_0)\\ f_{yx}(x_0,y_0)&f_{yy}(x_0,y_0)\\ \end{bmatrix} \begin{bmatrix} \delta x \\ \delta y \end{bmatrix} f(x,y)≈f(x0,y0)+[δxδy][fx(x0,y0)fy(x0,y0)]+2!1[δxδy][fxx(x0,y0)fyx(x0,y0)fxy(x0,y0)fyy(x0,y0)][δxδy]
众所周知,二阶导数表示的导数的变化规律,如果函数是一条曲线,且曲线存在二阶导数,那么二阶导数表示的是曲线的曲率,曲率越大,曲线越是弯曲。以此类推,多维空间中的一个点的二阶导数就表示该点梯度下降的快慢。以二维图像为例,一阶导数是图像灰度变化即灰度梯度,二阶导数就是灰度梯度变化程度,二阶导数越大灰度变化越不具有线性性(即这里灰度梯度改变越大,不是线性的梯度)。
在二维图像中,海森矩阵是二维正定矩阵,有两个特征值和对应的两个特征向量。两个特征值表示出了图像在两个特征向量所指方向上图像变化的各向异性。如果利用特征向量与特征值构成一个椭圆,长轴与短轴分别对应海森矩阵最小特征值和最大特征值的特征向量的方向,其轴长与特征值的平方根成反比,这个椭圆就标注出了图像变化的各向异性[6]。

Fig2.5 海森矩阵与各向异性
圆具有最强的各项同性,线性越强的结构越具有各向异性。
利用海森矩阵的特性,我们就可以找出图像中的点状结构,滤除其他信息。
局部描述符(Local Descriptor)。由局部检测器对图像中一系列区域进行检测之后的结果,可以由局部描述符进行编码。SIFT描述符一直以来都是大家默认使用的描述符,这种128维的向量在匹配准确率上从众多描述符中脱颖而出。具体来说,先对每个特征点取8x8邻域,然后把这8x8区域又分成四个4x4区域,每个4x4区域生成一个有8个方向向量信息的种子,这样对一个特征点就有 4 × 8 = 32 4\times8=32 4×8=32维向量信息了。
更进一步地,PCA-SIFT描述符将特征向量的维度从128维减少到36维,除了SIFT之外,SURF描述符也被广泛应用。SURF描述符结合了海森-拉普拉斯检测器和局部梯度直方图,并使用积分图技巧加速特征的计算。
2.2 编码
当得到描述符之后,就需要对其编码以进行索引,实现图像检索。常见的编码算法有BOF、FV以及VLAD。
BoF(Bag of Features) 算法源自BoW词袋模型,建立码本时采用K-means,在映射时,利用视觉词袋量化图像特征,统计的词频直方图,该词频直方图即为编码后的特征向量,损失的信息较多。
FV(Fisher Vector):FV是对特征点用GMM建模,GMM实际上也是一种聚类,只不过它是考虑了特征点到每个聚类中心的距离,也就是用所有聚类中心的线性组合去表示该特征点,在GMM建模的过程中也有损失信息。
VLAD(vector of locally aggregated descriptors):VLAD像BOF那样,只考虑离特征点最近的聚类中心,VLAD保存了每个特征点到离它最近的聚类中心的距离; 像Fisher vector那样,VLAD考虑了特征点的每一维的值,对图像局部信息有更细致的刻画; 而且VLAD特征没有损失信息。
2.2.1 Bag of Features
Bag-of-Features模型仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合[4]。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
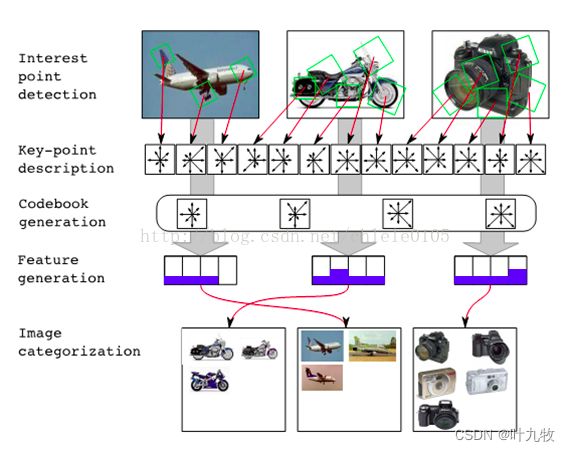
Fig2.6 Bag of Features Codebook Generation by Self-Organisation
图像中的每个特征都将被映射到视觉词典的某个词上,然后统计每个视觉词的出现次数或频率,图像可描述为一个维数相同的直方图向量即BoF特征。
更进一步,在原始的BoF特征基础上,还可以引入TF-IDF权值:词语的重要性随着它在文件中出现的频率成正比增加,但同时会随着它在文件数据库中出现的频率成反比下降。换句话说,如果某个关键词在一篇文章中出现的频率高,说明该词语能够表征文章的内容,该关键词在其它文章中很少出现,则认为此词语具有很好的类别区分度,对分类有很大的贡献。
2.2.2 Fisher Vector
对于一副图像X,提取T个D维的描述子,那么可以用 X = { x t , t = 1... T } X=\lbrace x_t,t=1...T\rbrace X={xt,t=1...T}来描述这张图片。假设这T个描述子独立同分布则有:
p ( X ∣ λ ) = ∏ t = 1 T p ( x t ∣ λ ) p(X|\lambda)= \prod^{T}_{t=1}p(x_t|\lambda) p(X∣λ)=t=1∏Tp(xt∣λ)
取对数之后可以得到:
L ( X ∣ λ ) = ∑ t = 1 T log p ( x t ∣ λ ) \mathcal{L}(X|\lambda)=\sum^T_{t=1}\log p(x_t|\lambda) L(X∣λ)=t=1∑Tlogp(xt∣λ)
此处的lamda为描述独立同分布的参数。现在要用一组K个高斯分布的线性组合(即GMM混合高斯模型)来逼近这个分布,其参数即为lamda。GMM模型可以用下式描述:
p ( x t ∣ λ ) = ∑ i = 1 N w i p i ( x t ∣ λ i ) p(x_t|\lambda)=\sum_{i=1}^Nw_ip_i(x_t|\lambda_i) p(xt∣λ)=i=1∑Nwipi(xt∣λi)
p i p_i pi是GMM中的第 i i i个多元高斯分布, w i w_i wi是其权值,并且有 ∑ i = 1 N w i = 1 \sum_{i=1}^Nw_i=1 ∑i=1Nwi=1, p i p_i pi的表达式如下:
p i ( x ∣ λ ) = exp { − 1 2 ( x − μ i ) ′ Σ i − 1 ( x − μ i ) } ( 2 π ) D 2 ∣ Σ i ∣ 1 2 p_i(x|\lambda)=\frac{\exp\lbrace{-\frac{1}{2}(x-\mu_i)^{'}\Sigma^{-1}_i(x-\mu_i)}\rbrace}{(2\pi)^{\frac{D}{2}}|\Sigma_i|^{\frac{1}{2}}} pi(x∣λ)=(2π)2D∣Σi∣21exp{−21(x−μi)′Σi−1(x−μi)}
参数 λ \lambda λ在计算Fisher Vector时是已知量,是预先通过GMM求解得到的先验值:
λ = { w i , μ i , Σ i , i = 1... N } \lambda=\lbrace{w_i,\mu_i,\Sigma_i,i=1...N}\rbrace λ={wi,μi,Σi,i=1...N}
w i w_i wi为系数,另外两个参数为高斯分布中的平均值和标准差。
而事实上,Fisher Vector的本质就是对于高斯分布的变量求偏导,即:
U X = [ ∂ L ( X ∣ λ ) ∂ w i , ∂ L ( X ∣ λ ) ∂ μ i d , ∂ L ( X ∣ λ ) σ i d ] T , i = 1... N U_X = [\frac{\partial L(X|\lambda)}{\partial w_i},\frac{\partial L(X|\lambda)}{\partial \mu_i^d},\frac{\partial L(X|\lambda)}{\sigma_i^d}]^T,i=1...N UX=[∂wi∂L(X∣λ),∂μid∂L(X∣λ),σid∂L(X∣λ)]T,i=1...N
再定义特征 x t x_t xt由第i个高斯分布生成的概率为:
γ t ( i ) = p ( i ∣ x t , λ ) = w i p i ( x t ∣ λ ) ∑ j = 1 N w j p j ( x t ∣ λ ) \gamma_t(i)=p(i|x_t,\lambda)=\frac{w_ip_i(x_t|\lambda)}{\sum^N_{j=1}w_jp_j(x_t|\lambda)} γt(i)=p(i∣xt,λ)=∑j=1Nwjpj(xt∣λ)wipi(xt∣λ)
代入其中得到:
∂ L ( X ∣ λ ) ∂ w i = ∑ t = 1 T [ γ t ( i ) w i − γ t ( 1 ) w 1 ] f o r i ≥ 2 , ∂ L ( X ∣ λ ) ∂ μ i d = ∑ t = 1 T γ t ( i ) [ x t d − μ i d ( σ i d ) 2 ] , ∂ L ( X ∣ λ ) σ i d = ∑ t = 1 T γ t ( i ) [ ( x t d − μ i d ) 2 ( σ i d ) 3 − 1 σ i d ] \frac{\partial L(X|\lambda)}{\partial w_i}=\sum_{t=1}^T{\lbrack{\frac{\gamma_t(i)}{w_i}-\frac{\gamma_t(1)}{w_1}}\rbrack} \quad for \ i \geq 2, \\ \frac{\partial L(X|\lambda)}{\partial \mu_i^d}=\sum^T_{t=1}\gamma_t(i)[\frac{x_t^d-\mu_i^d}{(\sigma_i^d)^2}], \\ \frac{\partial L(X|\lambda)}{\sigma_i^d}=\sum^T_{t=1}\gamma_t(i)[\frac{(x^d_t-\mu^d_i)^2}{(\sigma^d_i)^3}-\frac{1}{\sigma^d_i}] ∂wi∂L(X∣λ)=t=1∑T[wiγt(i)−w1γt(1)]for i≥2,∂μid∂L(X∣λ)=t=1∑Tγt(i)[(σid)2xtd−μid],σid∂L(X∣λ)=t=1∑Tγt(i)[(σid)3(xtd−μid)2−σid1]
这里i指的是第i个高斯分布,d指特征 x t x_t xt的第d维,偏导对每个分布的每个维度都要计算,所以 U X U_X UX的维度时 ( 2 D + 1 ) × N (2D+1)\times N (2D+1)×N,由于 w i w_i wi存在约束 ∑ i w i = 1 \sum_iw_i=1 ∑iwi=1,所以少了一个自由变量,最终维度是 ( 2 D + 1 ) × N − 1 (2D+1)\times N -1 (2D+1)×N−1
上述结果归一化后即为求得的Fisher Vector。
2.2.3 Vector of Locally Aggregated Descriptors
由Jegou et al.在2010年提出,其核心思想是aggregated(积聚),主要应用于图像检索领域。
VLAD算法可以看做是一种简化的FV,其主要方法是通过聚类方法训练一个小的码本,对于每幅图像中的特征找到最近的码本聚类中心,随后所有特征与聚类中心的差值做累加,然后得到一个 k × d k \times d k×d的矩阵,其中 k k k是聚类中心的个数,d是特征维数。随后将该矩阵扩展成为一个 k × d k \times d k×d维的向量并进行L2归一化,所得的向量即为VLAD。
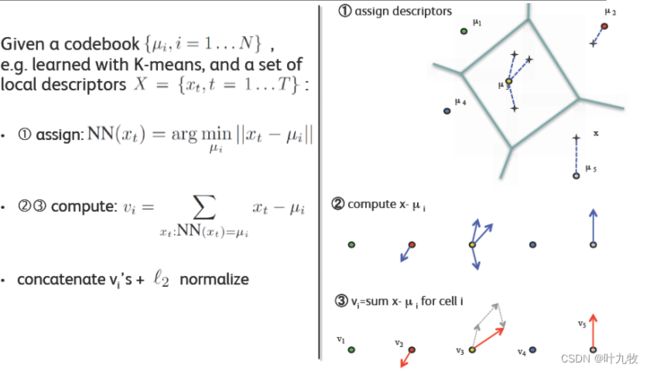
Fig2.7 Vector of Linearly Agregated Descriptors
图像中的每个特征都将被映射到视觉词典的某个词上,然后统计每个视觉词的出现次数或频率,图像可描述为一个维数相同的直方图向量即BoF特征。
2.3 检索
由于VLAD/FV嵌入的维度相当高,因此研究人员提出了高效的压缩和最似最近邻检索(ANN)算法。例如,主成分分析(PCA)算法常适用于降维任务,特别是使用PCA降维后检索的准确度甚至会提高。
对于基于哈希的最似最近邻方法,Perronnin等人使用标准二值编码方法,如局部敏感哈希(LSH)和谱哈希(spectral hashing)。然而,在使用SIFT和GIST特征数据库进行测试时,谱哈希方法被证明要优于乘积量化方法。在这些基于量化的最似最近邻算法中,PQ算法表现得最为出色。
同样,PQ算法后来也被不断改进。Douze等人提出对聚类中心重新排序,使得相邻的中心具有较小的汉明距离。该方法与基于汉明距离的最似最近邻检索相兼容,这为PQ算法提供了显著的加速[5]。
3. 基于CNN的图像检索
在特征工程时代(即前深度学习时代),该领域被里程碑式的手工工程特征描述符所主导,如尺度不变特征变换(SIFT)。近几年,CNN这种层次结构模型在许多视频相关的任务上取得的成绩远好于手工特征,基于SIFT特征的模型的风头似乎被CNN盖过了。
基于CNN的检索模型通常计算出紧密的图像表示向量,并使用欧氏距离或ANN(approximate nearest neighbor)查找算法进行检索。最近的文献可能会直接使用预训练好的CNN模型或微调后应用于特定的检索任务。这些方法大多只将图像输入到网络中一次就可以获取描述符(Fig3.1)。
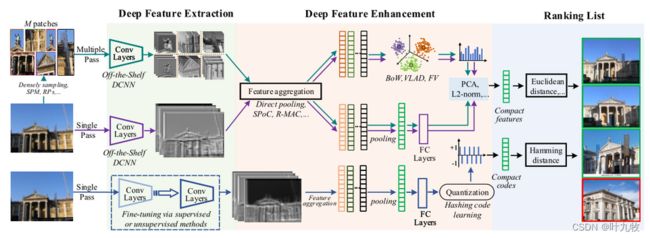
Fig3.1 Deep Image Retrieval
深度学习图像检索由图中所示的几个关键阶段组成,以下几个问题一直在驱动该领域的研究 1) 仅用现成的模型,深度特征如何超越手工特征? 2) 在跨数据集的域迁移问题上,我们该如何利用现成模型来保持甚至于提升检索性能? 3) 由于深度特征通常是高维的,我们该如何利用它们进行高效的图像检索,尤其是在大规模数据集上?
基于CNN的方法主要被分为三类:使用预训练的CNN模型,使用微调的CNN模型以及使用混合模型[7]。
3.1 使用预训练CNN模型的图像检索
在深度学习领域,一个容易想到的策略是:针对分类和识别训练出深度模型,然后直接将其保存为现成的(off-the-shelf)特征提取器来进行图像检索任务。也即:可以将分类模型的预训练权重冻结,然后在此基础上进行图像检索。
理所当然的,这种方法有一些限制,比如当两个任务间存在着模型迁移或者域变化的问题,在分类任务上训练的模型不一定能提取出非常适合图像检索的特征。因此,使用现成的预训练模型进行图像检索需要一些特别的策略来提高特征表达。
3.1.1 特征提取
我们常用网络的全连接层作为图像检索的描述符,然而,全连接层会缺乏几何不变性以及空间信息,因此,可以考虑使用最后一个卷积层来代替。使用卷积特征的研究重点是提高其判别能力,代表性的策略图如图3.2所示:
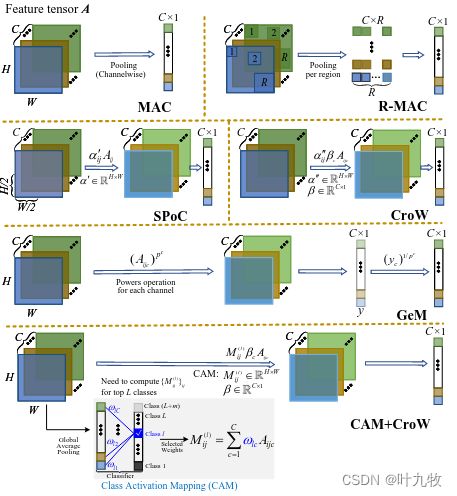
Fig3.2 DCNN特征表达方法
将feature maps中的不同区域视为不同的子向量,因此将所有feature maps中的子向量联合起来就可以表示整个图像。
卷积运算后等到的激活图层可以看做是特征的集成,例如,在AlexNet中第一层有 n = 96 n=96 n=96个滤波器,这些滤波器产生了 n = 96 n=96 n=96张大小为 27 × 27 27 \times 27 27×27的热力图(heat map)。热力图中的每个像素点具有大小为 19 × 19 19 \times 19 19×19的感受野,同时记录了图像对滤波器的响应。则列特征的大小是 1 × 1 × 96 1 \times 1 \times 96 1×1×96,它可以看作是对原始图像中某个图像块的描述。这个描述符的每个维度表示相应滤波器的激活程度,并且在某种程度上类似于SIFT描述符。
3.1.2 特征编码与池化
当提取列特征时,图像由一组描述符表示。为了将这些描述符聚合为全局表示,目前采用了两种策略:编码和直接池化合并(图2.2)。
编码。上一节中提到,一组列特征类似于一组SIFT特征,因此可以直接使用标准编码方案。常用的方法就是VLAD和FV算法,两个算法的简介可以参考第二节。
CNN特征与SIFT的主要区别在于前者在每个维度上都有明确的含义,也就是对输入图像的特定区域的滤波器响应。因此,除了上面提到的编码方案之外,直接使用池化技术也可以产生具有区分度的特征。
这一方面的里程碑工作是Tolias等人提出的最大卷积激活(Maximum Activation of Convolutions,MAC)[8]。如图3.3所示:
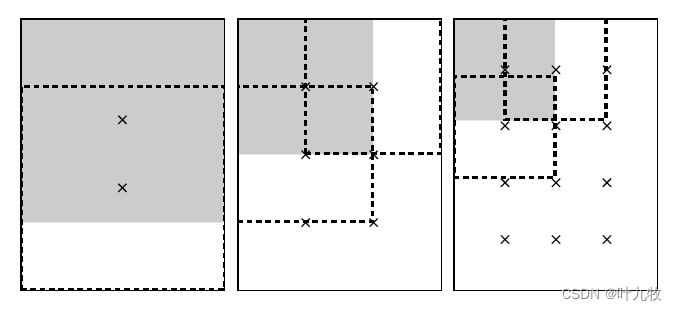
Fig3.3 R-MAC
R-MAC的regions产生在feature maps上,而不是在原图上。
在L个不同的尺度上产生正方形regions。在最大的尺度(l=1)上,region的尺寸最大。如图所示,依次为l=1,2,3。在某一个尺度 l 上,类似于滑动窗口,只需保证连续的两个region之间的重叠率接近于40%。
采样时,regions的正方形边长 w = h = 2 min ( w , h ) l + 1 w=h=\frac{2\min(w,h)}{l+1} w=h=l+12min(w,h),共采样 l × ( l + 1 ) l\times (l+1) l×(l+1)个regions。假设卷积网络结构中,提取特征的layer产生的feature map大小为WHK。以产生的region R1为例,其中的每一层d(1<=d<=K)均会产生一个大小位置与R1相同的regions。
以产生的region R i R_i Ri为例,从d层的每个region中找到其最大的激活值 f ( R i , d ) f(R_i,d) f(Ri,d),以该最大值代表这个region。所以若特征图大小为 w ∗ h ∗ k w*h*k w∗h∗k则 R i R_i Ri的特征向量可以表示为:
f ( R i ) = [ f ( R i , 1 ) , . . . , f ( R i , d ) , . . . , f ( R i , k ) ] f(R_i)=[f(R_i,1), ..., f(R_i,d), ..., f(R_i,k)] f(Ri)=[f(Ri,1),...,f(Ri,d),...,f(Ri,k)]
是一个 1 ∗ k 1*k 1∗k向量,整张图像的描述记为:
f = ∑ i = 1 N f R i f=\sum_{i=1}^Nf_{R_i} f=i=1∑NfRi
最后一层卷积层(如VGGNet的pool5)在池化后达到的准确率要高于FC描述符以及其他卷积层。其他方案还有层级特征融合,深度哈希编码以及采用注意力机制等等方案[7]。
3.2 使用微调CNN模型的图像检索
虽然预先训练的CNN模型已经取得了令人惊叹的检索性能,但在指定训练集上对CNN模型进行微调也是一个热门话题。当采用微调的CNN模型时,图像级的描述符通常以端到端的方式生成,那么网络将产生最终的视觉表示,而不需要额外的显式编码或合并步骤[5]。
3.2.1 用于微调网络的数据集
用于微调的数据集的性质是学习更具辨别性的CNN特征的关键。ImageNet只提供带有类标签的图像。因此,使用ImageNet预训练的CNN模型虽然有能力区分不同的物体以及场景,但是在区分属于统一类别(如建筑)但描述不同实例的图像(比如埃菲尔铁塔和巴黎圣母院)时可能效果不佳。因此在面向任务的数据集上对CNN模型进行微调非常重要。
用于微调网络的数据集主要集中于建筑物和普通物体中。微调网络方向一个里程碑式的工作是《Neural codes for image retrieva》。这篇文章通过一个半自动化的方法收集地标数据集:在Yandex搜索引擎中自动地爬取流行的地标,然后手动估计排名靠前的相关图像的比例。该数据集包含672类不同的地标建筑,微调网络在相关的地标数据集,如Oxford5k和假日数据集上表现优异,但是在Ukbench数据集(包含有普通物体)上性能降低了。
常用的用于微调网络方法数据集如下图所示:

Table 3.1 微调数据集
用于CNN网络微调的数据集,大部分集中于地标建筑上。
3.2.2 有监督微调
基于分类的微调。使用监督学习进行微调的一个方法是从一个预训练的DCNN模型开始,在一个单独的数据集上训练。训练后该DCNN网络就会在交叉熵损失的基础上通过优化参数进行微调:
L C E ( p i ^ , y i ) = − ∑ i c ( y i × log ( p i ^ ) ) L_{CE}(\hat{p_i}, y_i)=-\sum_i^c(y_i\times \log(\hat{p_i})) LCE(pi^,yi)=−i∑c(yi×log(pi^))
基于分类的微调方法提高了模型对新数据集的适应性,但在学习区分特定物体的类内差异方面存在一定的困难。为此,将基于验证的微调方法与分类方法相结合,可以进一步提高网络容量。
基于验证的模型微调。通过指示相似和不相似对的亲和信息,基于验证的微调方法学习一个最优度量,该度量可以最小化或最大化对的距离,以验证和保持它们的相似性。与基于分类的学习相比,基于验证的学习既关注类间样本,也关注类内样本。基于验证的学习涉及两种类型的信息:
- 一个成对约束,对应于图3.4©所示的Siamese网络,其中输入图像是由正或负样本组成的对;
- 一个三联体约束,与三联体网络相关联,如图3.4(e)所示,其中锚点图像与相似和不相似的样本配对。

Fig3.4 supervised fine-tuning
具体来说就是:设一个mini batch中存在三元集和 X = { ( x a , x p , x n ) } X=\lbrace{(x_a, x_p, x_n)}\rbrace X={(xa,xp,xn)},其中 ( x a , x p ) (x_a, x_p) (xa,xp)表示相似的对, ( x a , x n ) (x_a, x_n) (xa,xn)表示不相似的对。使用参数为 θ \theta θ的网络从图像中提取的特征为 f ( x ; θ ) f(x; \theta) f(x;θ),则每个相似和不相似对的亲和信息可以表示为:
D i j = D ( x i , x j ) = ∣ ∣ f ( x i ; θ ) − f ( x j ; θ ) ∣ ∣ 2 2 D_{ij}=D(x_i, x_j)=||f(x_i; \theta) - f(x_j; \theta)||_2^2 Dij=D(xi,xj)=∣∣f(xi;θ)−f(xj;θ)∣∣22
具体的微调过程主要有三种形式:
a. 通过变换矩阵微调
学习输入样本之间的相似性可以通过优化一个线性变换矩阵的权值来实现,这些对的相似性得分可以通过一个子网络:
S W ( x i , x j ) = f W ( f ( x i ; θ ) ∪ f ( x i ; θ ) ; W ) S_W(x_i, x_j)=f_W(f(x_i; \theta)\cup f(x_i; \theta); W) SW(xi,xj)=fW(f(xi;θ)∪f(xi;θ);W)
来预测,其中 W ∈ R 2 d × 1 W \in \mathbb{R}^{2d \times 1} W∈R2d×1,d为特征维度。换句话说,子网络 f w f_w fw预测了特征对的相似程度。给出特征对的亲和信息 S i j = S ( x i , x j ) ∈ { 0 , 1 } S_{ij}=S(x_i, x_j)\in \lbrace{0, 1}\rbrace Sij=S(xi,xj)∈{0,1},则函数 f W f_W fW可通过回归如下损失函数来进行:
L W ( x i , x j ) = ∣ S W ( x i , x j ) − S i j ( s i m ( x i , x j ) + m ) − ( 1 − S i j ( s i m ( x i , x j ) − m ) ) ∣ L_W(x_i, x_j)=|S_W(x_i, x_j)-S_{ij}(sim(x_i, x_j)+m)-(1-S_{ij}(sim(x_i, x_j)-m))| LW(xi,xj)=∣SW(xi,xj)−Sij(sim(xi,xj)+m)−(1−Sij(sim(xi,xj)−m))∣
其中 s i m ( x i , x j ) sim(x_i, x_j) sim(xi,xj)可以为余弦相似度,m为间隔距离(margin)。
b. 通过孪生(Siamese)网络微调
Siamese网络的输入是成对的,同样由相似性 S ( x i , x j ) ∈ { 0 , 1 } S(x_i, x_j) \in \lbrace{0, 1}\rbrace S(xi,xj)∈{0,1}的图相对(x_i, x_j)组成,具体可公式化为:
L S i a m ( x i , x j ) = 1 2 S ( x i , x j ) D ( x i , x j ) + 1 2 ( 1 − S ( x i , x j ) ) max ( 0 , m − D ( x i , x j ) ) L_{Siam}(x_i, x_j)=\frac{1}{2}S(x_i, x_j)D(x_i, x_j)+\frac{1}{2}(1-S(x_i, x_j))\max(0, m-D(x_i, x_j)) LSiam(xi,xj)=21S(xi,xj)D(xi,xj)+21(1−S(xi,xj))max(0,m−D(xi,xj))
c. 使用三联(Triplet)网络进行微调
Triplet网络同时优化相似和不相似的对,普通Triplet网络采用ranking loss进行训练:
L T r i p l e t ( x a , x p , x n ) = max ( 0 , m + D ( x a , x p ) − D ( x a , x n ) ) L_{Triplet}(x_a, x_p, x_n)=\max(0, m+D(x_a, x_p)-D(x_a,x_n)) LTriplet(xa,xp,xn)=max(0,m+D(xa,xp)−D(xa,xn))
大多数基于验证的监督学习方法依赖于基本的Siamese或triplet网络。后续研究的重点是探索进一步提高其鲁棒特征相似度估计能力的方法。一般来说,网络结构、损失函数和样本选择是验证方法成功的重要因素。
参考文献
[1] SIFT算法详解
[2] 词向量之词袋模型(BOW)详解
[3] 图像处理-海森矩阵
[4] Bag of Features (BOF)图像检索算法
[5] SIFT Meets CNN: A Decade Survey of Instance Retrieval
[6] Harris角点检测原理及C++实现
[7] Deep Learning for Instance Retrieval: A Survey
[8] R-MAC(Regional Maximum Activation of Convolutions)