SSD目标检测算法的理解和记录
,ssd是之前看的论文,但记性太差理解力太差,忙一段时间别的事,之前看过的就差不多忘光了。。。故做一个记录贴,以便加深记忆和理解。
目前基于深度学习的目标检测算法主要分为两类,分别是one-stage和two-stage,其中,two-stage算法典型算法有R-CNN,先通过启发式方法或者CNN网络产生一系列稀疏的候选框,然后对这些候选框进行分类与回归;one-stage典型算法有SSD和yolo系列算法,很明显的可以从名字看出,是通过单个神经网络完成bounding box和class的预测,一步到位。相对的,two-stage的准确率就会较高,one-stage的速度会较快。
网络结构
SSD的基础网络部分采用了VGG16,并且在其基础上有进一步的改进,
(1)将全连接层FC6和FC7变成了两个分别为33和11的卷积层,
(2)后续层移除,新加了4个卷积层
(3)池化层pool5由原来的2×2−s2变成3×3−s1
(4)conv6层卷积层采用了空洞卷积
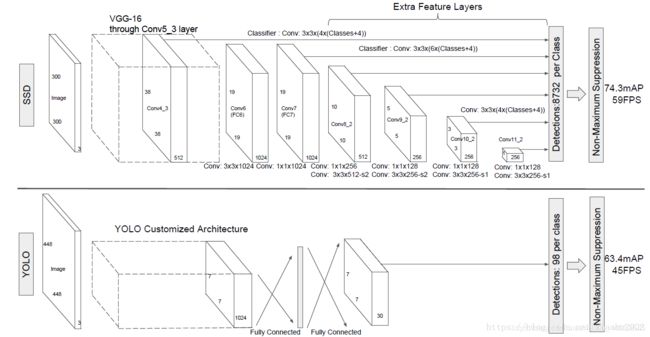
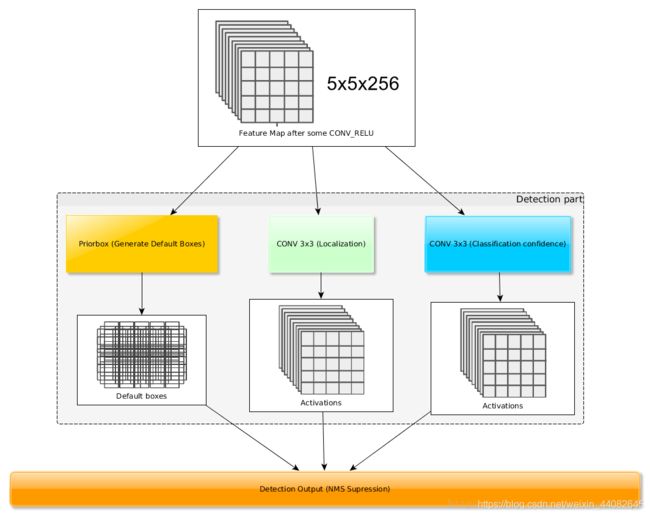
其中,将VGG16的6个层作为用于检测的6个特征图,都将用于对bounding box和class进行预测,分别为Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2,大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)。
大尺度特征图用于检测小目标,小尺度特征图用于检测大目标
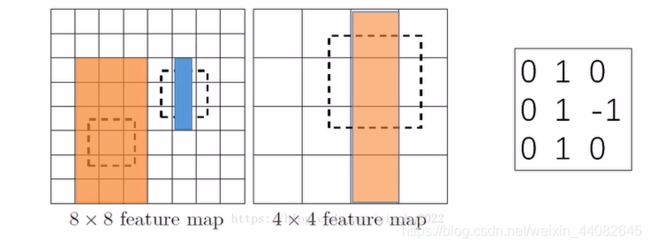
这个理解方法是从B站一个大佬的视频中学来的!
在如上图例中,目标为检测两个特征图中的长方形。
第一张图为8×8大小的特征图,其中有两个长方形;第二张图中为4×4大小的特征图,其中有一个长方形。现假设利用第三张图中的卷积核进行卷积,如果卷积结果为3,则认为检测到所需长方形。
若每个feature map中的每个小格中数为1,通过加权求和的卷积运算,在第一张图中,橙色的长方形与卷积核卷积后的结果为2;而蓝色长方形与卷积核卷积后的结果为3,因此在8×8的特征图中,检测到了相对较小的一个长方形。将8×8的特征图通过pooling操作得到第二张图中4×4的特征图,之前橙色的长方形变成图二中的长方形,与卷积核进行卷积后的结果为3,因此,在4×4的特征图中,检测到了相对较大的一个长方形。从这个例子中,可以很简单的理解大尺度检测特征图用于检测小目标,小尺度特征图用于检测大目标。
设置先验框
在SSD中,借鉴了anchor的理念,每个单元设置尺度,长宽比不同的先验框,预测的边界框是通过这些先验框得到的。在之前的6个feature map中,每一个特征图都会预先计算一个先验框,用于之后的训练和预测。
先验框的设置,包括尺度和长宽比两个方面。该公式用于计算先验框的尺度
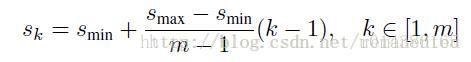
①Sk表示先验框大小相对于图片的比例,而不是直接就是先验框的尺度,Smin和Smax表示先验框大小相对于图片比例的最小值和最大值,分别取0.2和0.9。
(1)在6个特征图中,第一个特征图即Conv4_3是一个例外,它是单独设置的,(因此m不取6,m的取值为5)其先验框比例一般取Smin/2=0.1,故其尺寸为300×0.1=30
(2)在之后的5个特征图中,计算方法是,先将尺度比例,就是Sk,Smin,Smax放大100倍,可以求得分别为20,37,54,71,88。然后再除100,再乘以图片的大小,在SSD300中,乘300,因此可以得到60,111,162,213,264这五个特征图中产生先验框的尺度。再结合Conv4_3中的30,最后得到的30,60,111,162,213,264,即为各个特征图先验框的尺寸。
②先验框的长宽比,为
![]()
通过先验框的尺度和长宽比,利用如下公式,可以分别计算出先验框的宽度和高度。(这里的Sk是刚计算出的实际尺寸,即30,60,111,162,213,264.不是之前的先验框相对于图片的比例)
![]()
![]()
可以从上图中看出,默认情况下,每个特征图会有一个长宽比为1且尺度为Sk的先验框,除此之外,还会设置一个尺度为![]() 且长宽比也是1的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。
且长宽比也是1的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。
因此,每个feature map应该一共有6个先验框,(其中长宽比为1的有两个,见上图中的大小正方形),但在实际中,Conv4_3,Conv10_2和Conv11_2只有4个先验框,他们都不使用3,1/3这两个长宽比的先验框。每个先验框的中心点分布在每个小格,feature map cell的中心。
每个先验框,都输出特定的检测值,对应一个边界框。第一部分,输出的检测值是各个类别的置信度,在SSD中,背景也当作一个特殊的类别,即若有C个类别,则SSD检测C+1个类别,第一个置信度代表的是属于背景的评分。第二部分,输出的检测值是待检测物的位置信息,(cx,cy,w,h),分别表示边界框的中心坐标以及宽高。
在上图c中,先验框预测了loc的以及conf,先验框的位置用d表示,每个先验框对应的边界框用b表示,l代表边界框的预测值,l可以由b和d得出,该过程称为编码:
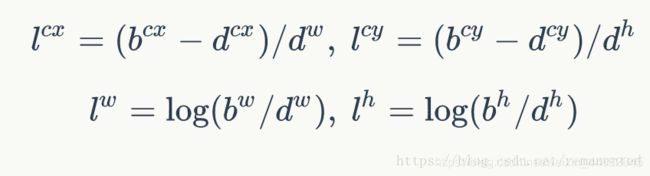
反之,在进行预测时,我们需要得到边界框的信息,即b,将上公式反过来表示,就可以从预测值l中得出所要求的b值,即解码。
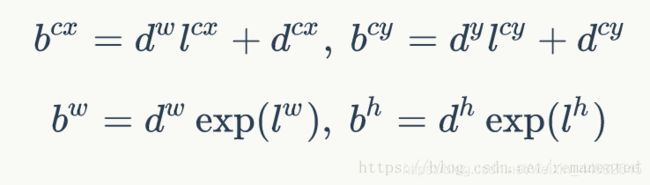
实际中还加入了4个variance值来帮助训练,如果存在variance,则解码公式如下有所改变:

因此,对一个大小为mn的特征图,共有个mn个feature map cell,(就是小格子…),每一个feature map cell设置的的先验框个数为k,那么每个feature map cell共有(c+4)k个预测值,而对一个大的feature map而言,就有(c+4)kmn个预测值。
所以SSD300一共可以预38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732个边界框,所以SSD本质上是密集采样。
对default box 和 prior box 的理解
这里我想说一下,我对default box 和 prior box 这两个点的理解,可能不是很准确,原论文中包括网上也都没有找到详细的解释,通过对网上很多大佬的介绍来看,只能自己理解,可能不是对的,但是死马当做活马医,用来强行理解了。。。
default box是每一个feature map cell中产生的框,而prior box是实际中从default box中所选择的框,对每个feature map cell中,不是全部k个default box都会取到。因此,default box可以理解为理论上的框,而prior box可以理解为实际中应用的框。
训练过程

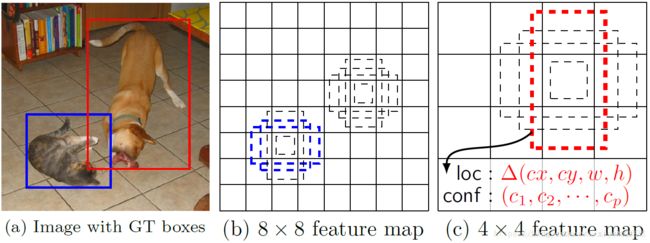
上图中,绿色框是真实框,即ground truth,红色和蓝色是default box,在进行先验框匹配时,计算ground truth与其它default box的IOU,若大于阈值0.5,则认为是正样本,反之,认为是负样本。
图中看出,一个ground truth对应多个default box,但,即使对应多个default box,groud truth相对于先验框少之又少,负样本数量远大于正样本的数量,所以对负样本进行抽样,抽样时按照置信度误差进行降序排列,选取误差的较大的top-k作为训练的负样本,使得正负样本比例接近1:3。
损失函数
损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
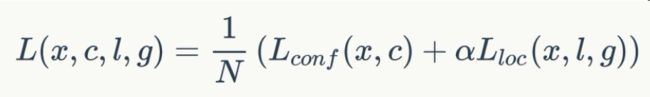
其中N是先验框的正样本数量。这里![]() 为一个指示参数,表示第i个先验框与第j个ground truth匹配,并且ground truth的类别为p。c为类别置信度预测值。l为先验框的所对应边界框的位置预测值,而g是ground truth的位置参数。对于位置误差,其采用SmoothL1 loss,定义如下:
为一个指示参数,表示第i个先验框与第j个ground truth匹配,并且ground truth的类别为p。c为类别置信度预测值。l为先验框的所对应边界框的位置预测值,而g是ground truth的位置参数。对于位置误差,其采用SmoothL1 loss,定义如下:
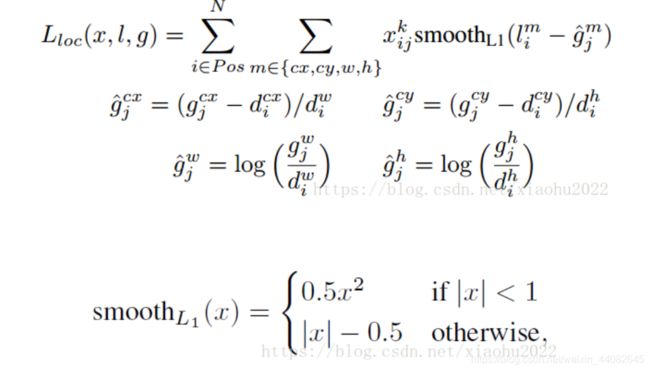
由于xpi存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的g进行编码得到g^,因为预测值l也是编码值,编码时要加上variance
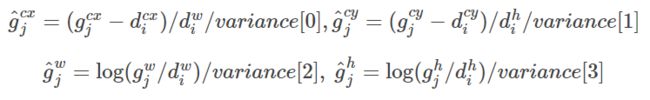
对于置信度误差,其采用softmax loss:
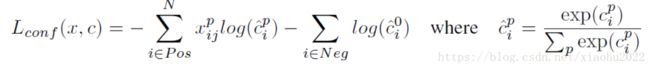
权重系数α通过交叉验证设置为1。
数据增广
增加数据量,使效果更好,主要有水平翻转,随机裁剪加颜色扭曲,随机采集块域(获取小目标训练样本),如下图所示:

预测
对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。