BP单隐层神经网络 代码实现 以及 详细步骤
在上一篇博客的基础上,研究了下单隐层神经网络,下面详细的说下步骤:
上一篇博客中,不管是加没加激励函数,都是输入后直接输出.
而单隐层神经网络就是输入和输出中间有一个隐层,
即 输入层的输出是隐层的输入 ,隐层的输出和对应权重的乘积是输出层的输入 ,输出层的输出才是最终的输出.
有点拗口,下面理一下上面的话: (以下加粗变量都是向量)
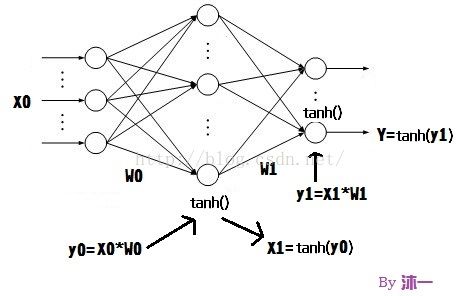
如上图
输入层的输入 就是 N个样本的Hog特征维度(A) : 记做 X0
输入层的输出(隐层的输入) 就是 X0 和W0 的乘积: 记做 y0
通过隐层的激励函数 tanh(), 隐层的输出 为 tanh(y0) : 记做X1
输出层的输入 就是 隐层的输出和对应权重的乘积,即X1*W1 : 记做 y1
通过对输出层的输入进行挤压后即为输出层的输出 tanh(y1) : 记做Y
总计下就是:
y0 = X0 * W0
X1 = tanh(y0)
y1 = X1 * W1
Y = tanh(y1)
损失函数公式不变:

因为单层神经网络有两个权重W0和W1,所以这两个权重都是要更新的,
更新权重是从右往左更新,先更新W1再更新W0,下面是更新两个权重的公式:
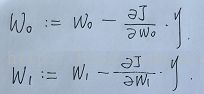
当然,重点就是求这两个  ,
,
这两个求起来也不是很难,上面说了先更新W1然后W0,下面是简单的步骤:


这两个结果,因为要分别和W1,W2的矩阵维度对应,所以根据各个之间的相乘相减什么的,
得出下面两个式子:
上面的式子有2点要注意的:
1. 符号 * 相乘是矩阵相乘, 符号 · 是矩阵点乘,其中平方也是矩阵点乘
2. 矩阵相乘是有左右顺序的,所以就是上图的顺序.
这样求出的结果才是和W0,W1的维度相对应的,才能进行两个权重的更新,不然会报错.
详细步骤说差不多了,更新2个权重的式子也都求出来了,下面上代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define PI 3.14
#define FILE_NVM 4
#define MaxLearnRate 0.00008 // 定义的学习速率, 这个数字不一定是最合适你的样本的
#define BIN_SIZE 20
#define BIN_NVM 9
#define NORM_WIDTH 22
#define NORM_HEIGHT 22
#define CELL_SIZE 2
#define BLOCK_SIZE 2
#define PIC_CELL_WH 50
#define HIDE_NVM 400 // 隐层定义的为 400个, 这个可以手动修改
#define CELL_W_NVM ((NORM_WIDTH-2) / CELL_SIZE)
#define CELL_H_NVM ((NORM_HEIGHT-2) / CELL_SIZE)
#define BLOCK_W_NVM (CELL_W_NVM - BLOCK_SIZE + 1)
#define BLOCK_H_NVM (CELL_H_NVM - BLOCK_SIZE + 1)
#define CELL_NVM (CELL_W_NVM * CELL_H_NVM)
#define BLOCK_NVM (BLOCK_W_NVM * BLOCK_H_NVM)
#define ARRAY_ALL (BLOCK_W_NVM * BLOCK_H_NVM * BLOCK_SIZE * BLOCK_SIZE * BIN_NVM)
typedef struct _SampleInfo // 每个样本对应的 data 以及目标值, 图片缩放到20*20
{
float iTarget[FILE_NVM];
float pdImageData[ARRAY_ALL];
}SampleInfo;
static SampleInfo pstTrainSampleInfo[3942]; // 存放样本的数组,一共1770个样本
static SampleInfo pstTestSampleInfo[9249]; // 存放样本的数组,一共3981个样本
static int iTotalTrainSample; //所有训练样本的数量
static int iTotalTestSample; //所有测试样本的数量
static int iTotalIteNvm = 1000; // 训练的轮数
static double pdLearnRate = MaxLearnRate; // 学习速率
void func(int i_x, int i_y, int i_w, IplImage* Img_in, float* fbin)
{
memset(fbin, 0, 9*sizeof(float));
float f_x = 0.0f, f_y = 0.0f, f_Nvm = 0.0f, f_theta = 0.0f;
for (int ii = i_y; ii < i_y + i_w; ii++)
{
for (int jj = i_x; jj < i_x + i_w; jj++)
{
uchar* pData = (uchar*)(Img_in->imageData + ii * Img_in->widthStep + jj);
f_x = pData[1] - pData[-1];
f_y = pData[Img_in->widthStep]- pData[-Img_in->widthStep];
f_Nvm = pow( f_x*f_x + f_y*f_y, 0.5f);
float fAngle = 90.0f;
if (f_x == 0.0f)
{
if (f_y > 0)
{
fAngle = 90.0f;
}
}
else if (f_y == 0.0f)
{
if (f_x > 0)
{
fAngle == 0.0f;
}
else if (f_x < 0)
{
fAngle == 180.0f;
}
}
else
{
f_theta = atan(f_y/f_x); atan() 范围为 -Pi/2 到 pi/2 所有9个bin范围是 0~180°
fAngle = (BIN_SIZE*BIN_NVM * f_theta)/PI;
}
if (fAngle < 0)
{
fAngle += 180;
}
int iWhichBin = fAngle/BIN_SIZE;
fbin[iWhichBin] += f_Nvm;
}
}
}
static void sigmoid(CvMat* pResult)
{
float* pfData = pResult->data.fl;
for (int ii=0; iirows * pResult->cols; ii++)
{
*pfData = tanh( *pfData );
pfData++;
}
}
static void InitWeight(CvMat* pWeight)
{
float* pfData = pWeight->data.fl;
for(int ii = 0; ii < pWeight->rows*pWeight->cols; ii++)
{
*pfData = ( rand() % 1000 ) / 10000.0 - 0.05;
pfData++;
}
}
static int GetTrainSumNvm(char* pSrcPath, int iFlag) // 获取所有样本个数
{
char pSrcSubFilePath[256];
struct _finddata_t FileInfo;
IplImage* pImgSrc = NULL;
intptr_t lHandle;
int ii, iTrainNvm=0;
IplImage* pResizeImage = cvCreateImage(cvSize(NORM_WIDTH,NORM_HEIGHT), 8, 1);
uchar* pucImgData = (uchar*)pResizeImage->imageData;
for (ii=0; iiheight; tt+=CELL_SIZE)
{
for (int dd = 1; dd + CELL_SIZE < pResizeImage->width; dd+=CELL_SIZE)
{
func(dd, tt, CELL_SIZE, pResizeImage, f_bin_out[i_binNvm++]);
}
}
归一化每个block 并输出一个表示特征的大数组
int iBlockWhichCell = 0;
int uu = 0;
float f_max = 0.0f;
float f_Ether_Block[BLOCK_SIZE*BLOCK_SIZE][BIN_NVM];
float f_Last_Array[ARRAY_ALL];
for (int tt = 0; tt < BLOCK_W_NVM; tt++ )
{
for (int dd = 0; dd < BLOCK_H_NVM; dd++)
{
for (int kk = 0; kk < BIN_NVM; kk++ )
{
f_Ether_Block[0][kk] = f_bin_out[tt*CELL_W_NVM+dd][kk];
f_Ether_Block[1][kk] = f_bin_out[tt*CELL_W_NVM+dd+1][kk];
f_Ether_Block[2][kk] = f_bin_out[tt*CELL_W_NVM+dd+ CELL_W_NVM][kk];
f_Ether_Block[3][kk] = f_bin_out[tt*CELL_W_NVM+dd+ CELL_W_NVM+1][kk];
}
for (int ss = 0; ss < BLOCK_SIZE * BLOCK_SIZE; ss++ )
{
for (int mm = 0; mm < BIN_NVM; mm++)
{
f_max = (f_Ether_Block[ss][mm] > f_max) ? f_Ether_Block[ss][mm] : f_max;
}
}
for (int ss = 0; ss < BLOCK_SIZE * BLOCK_SIZE; ss++ )
{
for (int mm = 0; mm < BIN_NVM; mm++)
{
if (f_max < 0.000001f)
{
f_Ether_Block[ss][mm] = 0.0f;
}
else
{
f_Ether_Block[ss][mm] /= f_max;
}
if (iFlag == 1)
{
pstTrainSampleInfo[iTrainNvm].pdImageData[uu++] = f_Ether_Block[ss][mm];
for (int gg = 0; gg < FILE_NVM; gg++)
{
pstTrainSampleInfo[iTrainNvm].iTarget[gg] = -1.0f;
}
pstTrainSampleInfo[iTrainNvm].iTarget[ii] = 1.0f;
}
else
{
pstTestSampleInfo[iTrainNvm].pdImageData[uu++] = f_Ether_Block[ss][mm];
for (int gg = 0; gg < FILE_NVM; gg++)
{
pstTestSampleInfo[iTrainNvm].iTarget[gg] = -1.0f;
}
pstTestSampleInfo[iTrainNvm].iTarget[ii] = 1.0f;
}
}
}
}
}
iTrainNvm++;
cvReleaseImage(&pImgSrc);
}
} while ( _findnext( lHandle, &FileInfo ) == 0 );
}
return iTrainNvm;
cvReleaseImage(&pResizeImage);
}
int GradientDescend()
{
// 样本个数 N ; Hog数组维度 A
CvMat* cmTrainData = cvCreateMat(iTotalTrainSample, ARRAY_ALL+1, CV_32FC1); // N * A
CvMat* cmTrainDataT = cvCreateMat(ARRAY_ALL+1, iTotalTrainSample, CV_32FC1); // A * N
CvMat* cmTrainTarget = cvCreateMat(iTotalTrainSample, FILE_NVM, CV_32FC1); // N* 4
CvMat* cmWeight = cvCreateMat(ARRAY_ALL+1, HIDE_NVM, CV_32FC1); // A* 400
CvMat* cmWeightT = cvCreateMat(HIDE_NVM, ARRAY_ALL+1, CV_32FC1); // 400 * A
CvMat* cmResult = cvCreateMat(iTotalTrainSample, HIDE_NVM, CV_32FC1); // N * 400
CvMat* cmResultT = cvCreateMat(HIDE_NVM, iTotalTrainSample, CV_32FC1); // 400 * N
CvMat* cmHideWeight = cvCreateMat(HIDE_NVM, FILE_NVM, CV_32FC1); // 400 * 4
CvMat* cmHideWeightT = cvCreateMat(FILE_NVM, HIDE_NVM, CV_32FC1); // 4 * 400
CvMat* cmHideResult = cvCreateMat(iTotalTrainSample, FILE_NVM, CV_32FC1); // N * 4
CvMat* cmHideResultT = cvCreateMat(FILE_NVM, iTotalTrainSample, CV_32FC1); // 4 * N
CvMat* cmHResultTarSub = cvCreateMat(iTotalTrainSample, FILE_NVM, CV_32FC1); // N * 4
CvMat* cmHideDerivation = cvCreateMat(HIDE_NVM, FILE_NVM, CV_32FC1); // N * 4
CvMat* cmOneDerivation = cvCreateMat(ARRAY_ALL+1, HIDE_NVM, CV_32FC1); // N * 4
CvMat* cmHideTempResult = cvCreateMat(iTotalTrainSample, HIDE_NVM, CV_32FC1); // N * 4
// 初始化权重
InitWeight(cmWeight);
InitWeight(cmHideWeight);
// 将样本中的数据转化到矩阵中
for (int mm=0; mmdata.fl + mm *( ARRAY_ALL+1), sizeof(float)*ARRAY_ALL, pstTrainSampleInfo[mm].pdImageData, sizeof(float)*ARRAY_ALL);
//cmTrainTarget->data.fl[mm] = pstTrainSampleInfo[mm].iTarget;
cmTrainData->data.fl[mm*(ARRAY_ALL+1) + ARRAY_ALL] = 1.0f; // 将所有样本中的 b 赋值成 1
for(int qq = 0; qq < FILE_NVM; qq++)
{
cmTrainTarget->data.fl[mm*FILE_NVM + qq] = pstTrainSampleInfo[mm].iTarget[qq];
}
}
int iPosError = 0, iNegError = 0, iLastErrorSum=0;
//cvTranspose(cmWeight, cmWeightT);
for (int ii = 0; ii < iTotalIteNvm; ii++)
{
iPosError = iNegError = 0;
下面的步骤就是更新权重,
cvMatMul(cmTrainData, cmWeight, cmResult); // 求出隐层输入
sigmoid(cmResult);
cvMatMul(cmResult, cmHideWeight, cmHideResult); // 隐层输入 * W1 求出输出层的输入
sigmoid(cmHideResult);
cvTranspose(cmResult, cmResultT); // Y0(T)
cvTranspose(cmTrainData, cmTrainDataT); // X(T) cmHideWeight
cvTranspose(cmHideWeight, cmHideWeightT); // W1(T)
更新 W1 = W1 - 1/N*MaxLearnRate * ( Y0(T) x (Y1 - T)(1 - Y1^2) )
更新 W0 = W0 - 1/N*MaxLearnRate * ( X(T) x ( ( (Y1 - T)(1 - Y1^2) x W1(T) ) * ( 1 - Y0^2 ) ) )
cvSub(cmHideResult, cmTrainTarget, cmHResultTarSub); // (Y1 - T)
for (int yy = 0; yy < iTotalTrainSample *FILE_NVM ; yy++)
{
// (Y1 - T)(1 - Y1^2)
cmHideResult->data.fl[yy] = (1 - cmHideResult->data.fl[yy] * cmHideResult->data.fl[yy]) * cmHResultTarSub->data.fl[yy];
}
// Y0(T) x (Y1 - T)(1 - Y1^2)
cvMatMul(cmResultT, cmHideResult,cmHideDerivation);
// (Y1 - T)(1 - Y1^2) x W1(T)
cvMatMul(cmHideResult, cmHideWeightT, cmHideTempResult);
for (int yy = 0; yy < iTotalTrainSample*HIDE_NVM; yy++)
{
// ( (Y1 - T)(1 - Y1^2) x W1(T) ) * ( 1 - Y0^2 )
cmHideTempResult->data.fl[yy] = (1 - cmResult->data.fl[yy] * cmResult->data.fl[yy] ) * cmHideTempResult->data.fl[yy];
}
// X(T) x ( ( (Y1 - T)(1 - Y1^2) x W1(T) ) * ( 1 - Y0^2 ) )
cvMatMul(cmTrainDataT, cmHideTempResult, cmOneDerivation);
cvConvertScale(cmHideDerivation, cmHideDerivation, pdLearnRate, 0);
cvConvertScale(cmOneDerivation, cmOneDerivation, pdLearnRate, 0);
cvSub(cmHideWeight, cmHideDerivation, cmHideWeight, NULL); // 更新权重 W1
cvSub(cmWeight, cmOneDerivation, cmWeight, NULL); // 更新权重 W0
// (训练集) 更新完的W0和W1权重再从左到右进行输出,其结果与目标值进行比较得出错误样本的个数
cvMatMul(cmTrainData, cmWeight, cmResult);
sigmoid(cmResult);
cvMatMul(cmResult, cmHideWeight, cmHideResult);
sigmoid(cmHideResult);
// 求出的实际值 和 目标值进行比较, 得出训练集的错误样本的个数
for (int mm=0; mmdata.fl[mm*FILE_NVM + zz] > cmHideResult->data.fl[mm*FILE_NVM + iWhichNvm] )
{
iWhichNvm = zz;
}
}
if ( cmTrainTarget->data.fl[mm*FILE_NVM + iWhichNvm] != 1 )
{
iPosError++;
}
}
printf("train %d ------ %d -> %d -> %f \n", ii, iTotalTrainSample, iPosError, ((float)(iPosError+iNegError))/(float)iTotalTrainSample);
//这一轮训练的误差比上一轮大,此时应该降低学习速率。
if ( ii!=0 && (iPosError+iNegError)>=iLastErrorSum)
{
pdLearnRate = (pdLearnRatedata.fl + mm *( ARRAY_ALL+1), sizeof(float)*ARRAY_ALL, pstTestSampleInfo[mm].pdImageData, sizeof(float)*ARRAY_ALL);
cmTestData->data.fl[mm*(ARRAY_ALL+1) + ARRAY_ALL] = 1.0f; // 将所有样本中的 b 赋值成 1
for(int qq = 0; qq < FILE_NVM; qq++)
{
cmTestTarget->data.fl[mm*FILE_NVM + qq] = pstTestSampleInfo[mm].iTarget[qq];
}
}
cvMatMul(cmTestData, cmWeight, cmTestResult);
sigmoid(cmTestResult);
cvMatMul(cmTestResult, cmHideWeight, cmTestHideResult);
sigmoid(cmTestHideResult);
int iPosError_t = 0, iNegError_t = 0;
iPosError_t = iNegError_t = 0;
// 求出的实际值 和 目标值进行比较, 得出错误样本的个数
for (int mm=0; mmdata.fl[mm*FILE_NVM + zz] > cmTestHideResult->data.fl[mm*FILE_NVM + iWhichNvm] )
{
iWhichNvm = zz;
}
}
if ( cmTestTarget->data.fl[mm*FILE_NVM + iWhichNvm] != 1 )
{
iPosError_t++;
}
}
printf("Test ------ %d -> %d -> %f \n",iTotalTestSample, iPosError_t, ((float)(iPosError_t+iNegError_t))/(float)iTotalTestSample );
return 0;
}
int main()
{
// 样本放在桌面
iTotalTrainSample = GetTrainSumNvm("C:\\Users\\Administrator\\Desktop\\Train", 1);
iTotalTestSample = GetTrainSumNvm("C:\\Users\\Administrator\\Desktop\\Test", 0);
srand((int)time(0));
GradientDescend();
system("pause");
return 0;
} 下面是训练结果,和上一篇博客( C 实现最小二乘,步骤以及代码)中训练样本是一样的,虽然这次的速度慢,
但是和上篇博客中后面几次的效果比起来,还是有很大优势的~
因为速度慢,所以就训练1000次,也是很费时间,后面基本上好久都不收敛一下...
一开始的收敛效果:
训练集1000次效果: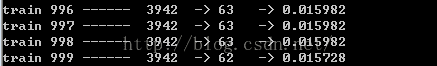
因为写测试集训练代码的时候,粗心,把矩阵的维度给弄错了一个,所以到这就崩掉了,
所以说上面提到的矩阵相乘和矩阵点乘,还有位置啥的,必须注意!
后来改了后运行起来就搁那吃饭去了,就上一个训练集和测试集的结果图吧: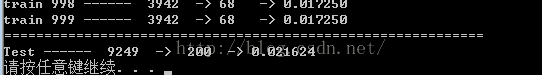
可以和上一篇博客中的效果对比一下,还是很不错的~