PERCEIVER-VL
文章目录
- PERCEIVER-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
- 一、Iterative Mapping to Low-Dim Latent Space
-
- 1.代码
- 2.实验
- 二、LayerDrop on Cross-Attention for Reducing Depth on Demand
-
- 1.代码
- 2.实验
- 三、Structured Decoding with Cross-Attention and Query Array
-
- 1.代码
PERCEIVER-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
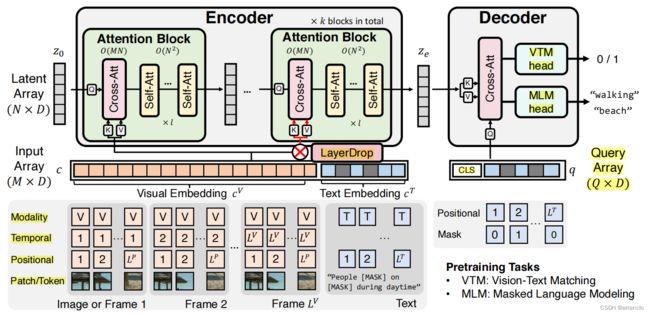
一、Iterative Mapping to Low-Dim Latent Space
latent array
cross attention(x和input)和self attention
1.代码
# Embedding Vision and Language Embedding
if image_embeds is not None: # Visual Embedding
inputs = self.co_norm(image_embeds) # LayerNorm
masks = image_masks
if video_embeds is not None: # Visual Embedding
inputs = self.co_norm(video_embeds) # LayerNorm
masks = video_masks
if text_embeds is not None: # Text Embedding
text_inputs = self.co_norm(text_embeds) # LayerNorm
inputs = torch.cat([inputs, text_inputs], 1) # cat Visual Embedding 和 Text Embedding Input Array(M*D) length M The encoder maps the input array c of length M to the latent array z of length N via iterative cross-attentions(Sec. 3.2).
masks = torch.cat([masks, text_masks], 1) #
# Embedding Vision and Language Embedding
# attention blocks Iterative Mapping to Low-Dim Latent Space
x = self.latents.unsqueeze(0).repeat(inputs.size(0), 1, 1) # latent_array:torch.randn
for i in range(self.depth): # CrossAttention和SelfAttention 一共depth 12层
if i in self.cross_layers_visual: # [0, 4, 8] # 0 1 2 3 4 5 6 7 8 9 10 11 三层attention block,每层一个CrossAttention 三个SelfAttention
# LayerDrop LayerDrop on Cross-Attention for Reducing Depth on Demand
if i in [0] or random.random() <= self.layer_drop: # 除了第0层,其他CrossAttention层有1-layer_drop的概率drop掉
x, _ = self.crossatt_blocks_visual[self.cross_layers_visual.index(i)](x, inputs, masks) # Block CrossAttention x作q,inputs(encoder的输入)作k、v inputs->inputs = torch.cat([inputs, text_inputs], 1)(self, x, context=None, mask=None) [0, 4, 8]
# LayerDrop LayerDrop on Cross-Attention for Reducing Depth on Demand
x, _ = self.blocks[i](x) # Block SelfAttention (self, x, mask=None)
# attention blocks Iterative Mapping to Low-Dim Latent Space
x = self.norm(x) # LayerNorm
class Block(nn.Module):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=False,
qk_scale=None,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
use_context=False,
post_norm=False,
):
super().__init__()
self.norm1 = norm_layer(dim)
if use_context:
self.attn = CrossAttention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
)
else:
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop,
)
self.post_norm = post_norm
if post_norm:
self.post_norm_layer = norm_layer(dim)
def forward(self, x, context=None, mask=None):
if context is None:
_x, attn = self.attn(self.norm1(x), mask=mask) # SelfAttention (self, x, mask=None)
else:
_x, x, attn = self.attn(self.norm1(x), context=context, mask=mask) # CrossAttention x做q,context做k、v (self, x, context=None, mask=None)
x = x + self.drop_path(_x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
if self.post_norm:
self.post_norm_layer(x)
return x, attn
class Attention(nn.Module):
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
):
super().__init__()
self.num_heads = num_heads
self.dim = dim
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, mask=None):
B, N, C = x.shape
qkv = (
self.qkv(x)
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
)
q, k, v = (
qkv[0],
qkv[1],
qkv[2],
) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
mask = mask.bool()
attn = attn.masked_fill(~mask[:, None, None, :], float("-inf"))
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # Dropout
x = (attn @ v).transpose(1, 2).reshape(B, N, C) #
x = self.proj(x) # nn.Linear
x = self.proj_drop(x) # Dropout
return x, attn
class CrossAttention(nn.Module):
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=True)
self.k = nn.Linear(dim, dim, bias=True)
self.v = nn.Linear(dim, dim, bias=True)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, context=None, mask=None):
skip_x = x
B, N, C = x.shape
q = self.q(x).reshape(B, x.size(1), self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # nn.Linear
k = self.k(context).reshape(B, context.size(1), self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # nn.Linear
v = self.v(context).reshape(B, context.size(1), self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # nn.Linear
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
mask = mask.bool()
attn = attn.masked_fill(~mask[:, None, None, :], float("-inf"))
attn = torch.tanh(attn)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # Dropout
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x) # nn.Linear
x = self.proj_drop(x) # Dropout
return x, skip_x, attn
2.实验
Scaling Input Array
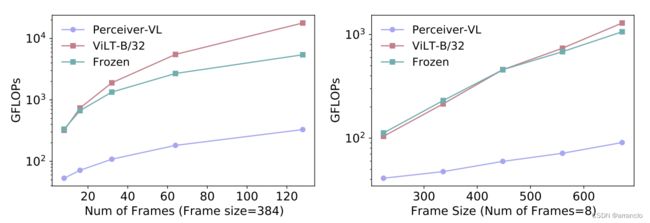
改变输入大小时,PERCEIVER-VL的性能与其他两种模型的比较。
Scaling Latent Array
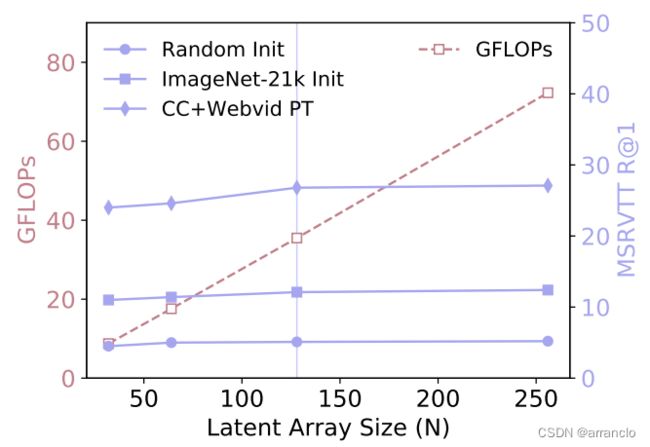
在finetuning期间增大latent array的大小,性能降低,精度提高。
二、LayerDrop on Cross-Attention for Reducing Depth on Demand
layer_drop越大,保留下来的Cross-Attention越多,第一层保留为了让encoder接收inputs
1.代码
# attention blocks Iterative Mapping to Low-Dim Latent Space
x = self.latents.unsqueeze(0).repeat(inputs.size(0), 1, 1) # latents:torch.randn
for i in range(self.depth): # CrossAttention和SelfAttention 一共depth 12层
if i in self.cross_layers_visual: # [0, 4, 8] # 0 1 2 3 4 5 6 7 8 9 10 11 三层attention block,每层一个CrossAttention 三个SelfAttention
# LayerDrop LayerDrop on Cross-Attention for Reducing Depth on Demand
if i in [0] or random.random() <= self.layer_drop: # 除了第0层,其他CrossAttention层有1-layer_drop的概率drop掉
x, _ = self.crossatt_blocks_visual[self.cross_layers_visual.index(i)](x, inputs, masks) # Block CrossAttention x作q,inputs(encoder的输入)作k、v inputs->inputs = torch.cat([inputs, text_inputs], 1)(self, x, context=None, mask=None) [0, 4, 8]
# LayerDrop LayerDrop on Cross-Attention for Reducing Depth on Demand
x, _ = self.blocks[i](x) # Block SelfAttention (self, x, mask=None)
# attention blocks Iterative Mapping to Low-Dim Latent Space
x = self.norm(x) # LayerNorm
2.实验
LayerDrop to Encoder Cross-Attentions

1.(123)Pretraining应用LayerDrop 会提高精度,p越低精度越高。
2.(467)Finetuning通过LayerDrop来增加Cross-Attention会提高精度,但直接增加损害精度。
3.(5678)Finetuning应用LayerDrop后,可以通过在Inference期间减少Cross-Attention来以很小的精度损失来换取较大的性能提升。
三、Structured Decoding with Cross-Attention and Query Array
两个任务:Vision-Text Matching (VTM)、Masked Language Modeling (MLM)
VTM query 和 MLM query
1.代码
text_feats = image_feats = video_feats = None
if self.use_decoder:
decoder_mask = torch.ones([1, 1]).repeat(x.size(0), 1).to(x.device)
# Query Array
decoder_feats = self.cls_token_decoder[:, :1].repeat(x.size(0), 1, 1) # torch.zeros
# Query Array
visual_output_length = 0
# VTM query 和 MLM query
if text_labels_mlm is not None:
# MLM query
position_ids = torch.arange(text_embeds.size(1)).expand((1, -1)).to(text_embeds.device) # torch.arange 一维张量
position_encodings = self.mlm_pos(position_ids) # nn.Embedding
# MLM query
# VTM query
type_ids = (text_labels_mlm==-100).to(text_embeds.device).long()
tpye_encodings = self.mlm_type(type_ids) # nn.Embedding
# VTM query
decoder_text_pos = position_encodings + tpye_encodings # VTM query 和 MLM query 相加
decoder_feats = torch.cat([decoder_feats, decoder_text_pos], 1) # Query Array 和 decoder_text_pos 连接
decoder_mask = torch.cat([decoder_mask, text_masks], 1)
# VTM query 和 MLM query
# single cross-attention
for i in range(len(self.decoder_block_text)): # for i in range(1)
if i == 0:
decoder_feats, _ = self.decoder_block_text[i](decoder_feats, x) # Block CrossAttention decoder_feats做q,x做k、v decoder_feats->decoder_feats = torch.cat([decoder_feats, decoder_text_pos], 1) x->x = self.norm(x) We use a decoder with a single cross-attentionfor i in range(1) (self, x, context=None, mask=None) do not apply LayerDrop to the first cross-attention layer, to ensure that the model always receives the signal from input.
else:
decoder_feats, _ = self.decoder_block_text[i](decoder_feats, mask=decoder_mask) # Block CrossAttention 走不到这里 for i in range(1) (self, x, context=None, mask=None)
# single cross-attention
decoder_feats = self.decoder_norm(decoder_feats) # LayerNorm
if image_embeds is not None:
image_feats = decoder_feats[:, 1:visual_output_length+1] # image_feats和video_feats一样 decoder_feats[:, 1:1]
if video_embeds is not None:
video_feats = decoder_feats[:, 1:visual_output_length+1] # image_feats和video_feats一样 decoder_feats[:, 1:1]
if text_embeds is not None:
text_feats = decoder_feats[:, 1+visual_output_length:] # decoder_feats[:, 1:]
return decoder_feats, text_feats, image_feats, video_feats