从零开始基于PaddleDetection的目标检测模型训练
gitee地址:https://gitee.com/paddlepaddle/PaddleDetection
github地址:https://github.com/PaddlePaddle/PaddleDetection
任选一个下载项目
官方文档:https://paddledetection.readthedocs.io/
安装
- 安装PaddlePaddle
# CUDA10.1
python -m pip install paddlepaddle-gpu==2.2.0.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
# CPU
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
- 安装其他依赖
pip install -r requirements.txt
- 编译安装paddledet
python setup.py install
安装后确认测试通过:
python ppdet/modeling/tests/test_architectures.py
测试通过后会提示如下信息:
.......
----------------------------------------------------------------------
Ran 7 tests in 12.816s
OK
数据集
本项目是用的数据集格式是VOC格式,标注工具为labelimg,图像数据是手动拍摄获取。
labelimg工具下载:https://download.csdn.net/download/get_py/85089156
数据标注
-
点击
Open Dir,打开文件夹,载入图片 -
点击
Create RectBox,即可在图像上画框标注 -
输入标签,点击
OK -
点击
Save保存,保存下来的是XML文件

XML文件内容如下:

整理成VOC格式的数据集: 创建三个文件夹:Annotations、ImageSets、JPEGImages

将标注生成的XML文件存入Annotations,图片存入JPEGImages,训练集、测试集、验证集的划分情况存入ImageSets。 在ImageSets下创建一个Main文件夹,并且在Mian文件夹下建立label_list.txt,里面存入标注的标签。 此label_list.txt文件复制一份与Annotations、ImageSets、JPEGImages同级位置放置。 其内容如下:

运行该代码将会生成trainval.txt、train.txt、val.txt、test.txt,将我们标注的600张图像按照训练集、验证集、测试集的形式做一个划分。
import os
import random
trainval_percent = 0.95 #训练集验证集总占比
train_percent = 0.9 #训练集在trainval_percent里的train占比
xmlfilepath = 'F:/Cola/Annotations'
txtsavepath = 'F:/Cola/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('F:/Cola/ImageSets/Main/trainval.txt', 'w')
ftest = open('F:/Cola/ImageSets/Main/test.txt', 'w')
ftrain = open('F:/Cola/ImageSets/Main/train.txt', 'w')
fval = open('F:/Cola/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
以下代码可根据在Main文件夹中划分好的数据集进行位置索引,生成含有图像及对应的XML文件的地址信息的文件。
import os
import re
import random
devkit_dir = './'
output_dir = './'
def get_dir(devkit_dir, type):
return os.path.join(devkit_dir, type)
def walk_dir(devkit_dir):
filelist_dir = get_dir(devkit_dir, 'ImageSets/Main')
annotation_dir = get_dir(devkit_dir, 'Annotations')
img_dir = get_dir(devkit_dir, 'JPEGImages')
trainval_list = []
train_list = []
val_list = []
test_list = []
added = set()
for _, _, files in os.walk(filelist_dir):
for fname in files:
print(fname)
img_ann_list = []
if re.match('trainval.txt', fname):
img_ann_list = trainval_list
elif re.match('train.txt', fname):
img_ann_list = train_list
elif re.match('val.txt', fname):
img_ann_list = val_list
elif re.match('test.txt', fname):
img_ann_list = test_list
else:
continue
fpath = os.path.join(filelist_dir, fname)
for line in open(fpath):
name_prefix = line.strip().split()[0]
print(name_prefix)
added.add(name_prefix)
#ann_path = os.path.join(annotation_dir, name_prefix + '.xml')
ann_path = annotation_dir + '/' + name_prefix + '.xml'
print(ann_path)
#img_path = os.path.join(img_dir, name_prefix + '.jpg')
img_path = img_dir + '/' + name_prefix + '.jpg'
assert os.path.isfile(ann_path), 'file %s not found.' % ann_path
assert os.path.isfile(img_path), 'file %s not found.' % img_path
img_ann_list.append((img_path, ann_path))
print(img_ann_list)
return trainval_list, train_list, val_list, test_list
def prepare_filelist(devkit_dir, output_dir):
trainval_list = []
train_list = []
val_list = []
test_list = []
trainval, train, val, test = walk_dir(devkit_dir)
trainval_list.extend(trainval)
train_list.extend(train)
val_list.extend(val)
test_list.extend(test)
#print(trainval)
with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval:
for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'train.txt'), 'w') as ftrain:
for item in train_list:
ftrain.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'val.txt'), 'w') as fval:
for item in val_list:
fval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest:
for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')
if __name__ == '__main__':
prepare_filelist(devkit_dir, output_dir)
最终创建完成的VOC数据集如下:
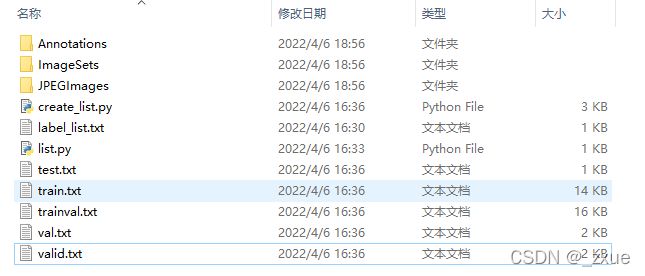
在./PaddleDetection/dataset目录下新建wo_voc目录,把创建完成的VOC数据集拷贝进来
配置文件
PaddleDetection的模型都在configs目录下,选择适合自己的就行,我这里用的picodet
首先指定数据集
在PaddleDetection/configs/datasets目录新建wo_voc.yml, 内容:
metric: VOC
map_type: integral
num_classes: 6 # 检测分类个数
TrainDataset:
!VOCDataSet
dataset_dir: dataset/wo_voc # 训练数据集
anno_path: train.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
!VOCDataSet
dataset_dir: dataset/wo_voc # 验证数据集
anno_path: val.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
!ImageFolder
anno_path: dataset/wo_voc/label_list.txt
修改配置
我们使用configs/picodet/picodet_s_320_voc.yml配置进行训练
配置需要依赖其他的配置文件, 如下图所示
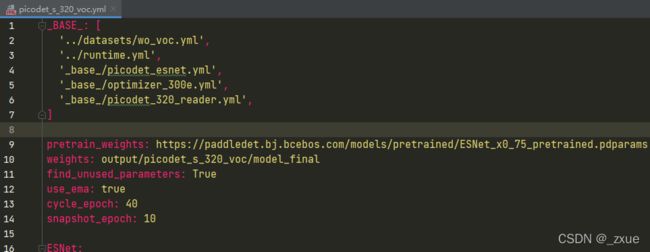
wo_voc.yml 主要说明了训练数据和验证数据的路径
runtime.yml 主要说明了公共的运行参数,比如说是否使用GPU、每多少个epoch存储checkpoint等
picodet_esnet.yml 主要说明模型、和主干网络的情况。
optimizer_300e.yml 主要说明了学习率和优化器的配置。
picodet_320_reader.yml 主要说明数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等
训练
- GPU单卡训练
python tools/train.py -c configs/picodet/picodet_s_320_voc.yml
- GPU多卡训练
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/picodet/picodet_s_320_voc.yml
- CPU训练
python tools/train.py -c configs/picodet/picodet_s_320_voc.yml -o use_gpu=false
- 其他参数
# 从之前训练的地方继续训练
-r output/picodet_s_320_voc/1000
# 可视化日志
--use_vdl=true --vdl_log_dir=vdl_dir/scalar
# 是否在训练中进行评估
--eval
训练可视化
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址
visualdl --logdir vdl_dir/scalar/
效果如下:

预测
# test目录下存放需要预测的图片
python tools/infer.py -c configs/picodet/picodet_s_320_voc.yml --infer_dir=test --output_dir=infer_output/ --draw_threshold=0.5 -o weights=output/picodet_s_320_voc/best_model use_gpu=false --use_vdl=Ture
预测结果会保存在infer_output目录
模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 在PaddleDetection中提供了tools/export_model.py脚本来导出模型
python -u tools/export_model.py -c configs/picodet/picodet_s_320_voc.yml --output_dir=./inference_model_final -o weights=output/picodet_s_320_voc/best_model
预测模型会导出到inference_model_final/picodet_s_320_voc目录下,分别为infer_cfg.yml, model.pdiparams, model.pdiparams.info,model.pdmodel 如果不指定文件夹,模型则会导出在output_inference
将inference模型转化为Paddle-Lite优化模型
执行一下代码
# 引用Paddlelite预测库
from paddlelite.lite import *
# 1. 创建opt实例
opt=Opt()
# 2. 指定输入模型地址
# opt.set_model_dir("../../output/picodet_s_320_voc/")
opt.set_model_file("../../inference_model_final/picodet_s_320_voc/model.pdmodel")
opt.set_param_file("../../inference_model_final/picodet_s_320_voc/model.pdiparams")
# 3. 指定转化类型: arm、x86、opencl、npu
opt.set_valid_places("arm")
# 4. 指定模型转化类型: naive_buffer、protobuf
opt.set_model_type("naive_buffer")
# 4. 输出模型地址
opt.set_optimize_out("picodet_s_320_voc_wo")
# 5. 执行模型优化
opt.run()
当前目录会生成picodet_s_320_voc_wo.nb模型文件
Paddle-Lite优化模型使用方法我就不介绍了,参考文档:Paddle-Lite 2.3 中文文档