中文巨量模型“源1.0”的学习优化方法
最近,浪潮人工智能研究院发布了中文巨量模型“源1.0”,参数量达2457亿,超越美国OpenAI组织研发的GPT-3。“源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习(zero-shot)和小样本学习(few-shot)两类总榜冠军。在零样本学习榜单中,“源1.0”超越业界极佳成绩18.3%,在6项任务中获得冠军;在小样本学习的4项任务获得冠军。在成语阅读理解填空项目中,源1.0的表现已超越人类得分。
为了提高“源1.0”在不同下游任务的泛化性和精度,我们采用了多种小样本学习优化策略。本文介绍了标签扩充和校正相结合的小样本学习优化方法。该方法不仅能消除预训练语料中标签出现频率不同而带来偏置,而且通过空文本或数据集校正标签词和输入样本带来的偏置,可使巨量模型避免再训练,降低了内存需求和系统复杂性,而且大大提高了下游任务的准确率和稳定性。
根据在下游任务推理时提供的样本数目,我们进一步将表述专门化为“零样本”和“小样本”。
采用零样本和小样本学习的原因
人类可以仅通过一个或几个示例就可以轻松地建立对新事物的认知,而机器学习算法通常需要成千上万个有监督样本来保证其泛化能力。拥有从零样本、小样本中学习和概括的能力,是人工智能向人类智能发展的重要标志。简单来说,零样本学习就是训练的模型不仅仅能够识别出训练集中已有的数据类别,还可以对未见过的类别的数据进行区分;小样本学习就是使用远小于深度学习所需要的数据样本量,达到接近甚至超越大数据深度学习的效果,如图1。
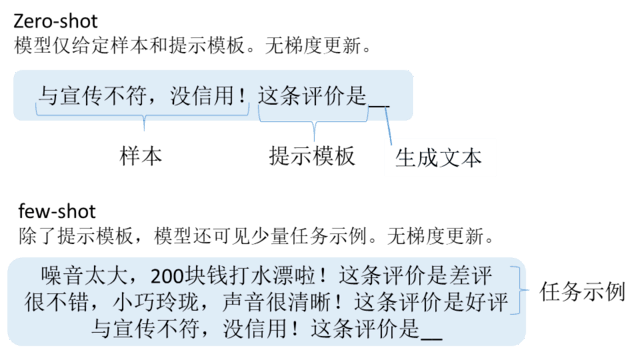
图1零样本学习和小样本学习示例
对“源1.0”这样的超大型模型进行微调比较困难而且成本很高,因此希望固定它们的模型参数,然后将不同的优化策略应用到不同下游任务上。新的研究成果也表明,在自然语言处理(NLP)领域通过增加模型规模、扩大预训练数据体量、使用更多的计算资源等方式,巨量模型可以在小样本学习甚至零样本学习任务中获得非常出色的性能表现。预训练好的巨量模型不必再经过复杂的“微调”过程,就可以为诸多应用任务泛化支持提供统一强大的算法支撑。
零样本和小样本学习优化方法
巨量模型核心的能力是零样本学习和小样本学习能力。但是基于巨量模型的零样本和小样本学习可能是非常不稳定的:提示模板格式的选择、训练样本、甚至训练样本顺序都可能导致准确性在接近偶然和接近先进水平之间漂移,这种不稳定性源于语言模型对预测某些答案的偏差,例如,那些被放在提示语末尾附近的答案,或在预训练数据中常见的答案,这些偏差往往会导致模型的输出分布发生变化。因此针对零样本和小样本学习任务,我们提出了一套校准和标签扩展方案来提升模型在下游任务上的性能表现。大量实验结果表明这套方案能够在多项语言处理NLP任务上稳定地提升模型的精度。以下内容以单句分类任务为例进行介绍。
提示模板设计 零样本学习
经过大量的实验对比,我们发现单句分类任务更适合基于概率生成方式,因此将提示模板设计成填空最后一个词的形式。

小样本学习
巨量模型的准确性在很大程度上取决于训练示例的选择和排列。因此我们从训练集中人工挑选三个不同类别(娱乐、文化、体育)示例进行测试排列测试。
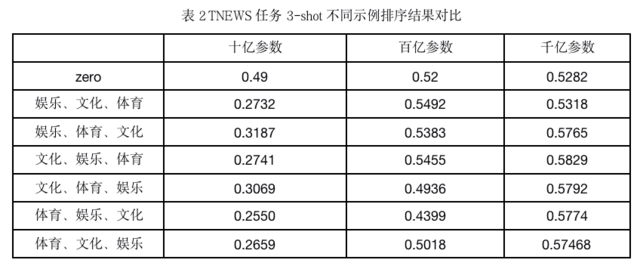
从实验数据可知,当模型参数量较小时,模型没有学到足够的知识,此时小样本示例对分类结果起负作用。随着模型参数量增大,小样本学习的效果越明显。
校准
巨量模型在预训练中会从语料库带来偏置,导致下游任务精度低或性能不稳定。例如,在零样本情感分类设置中,给定“N/A”作为输入,GPT-3倾向于预测为“positive”而不是“negative”,而本应该分配50/50的概率给这两个相反的标签。另一个问题是同一对象的不同表示(例如,“computer”和“PC”)可能会竞争概率质量,导致任务标签上的分布不理想。因此在实际应用中校正很有必要。具体可参考论文:CalibrateBefore Use: Improving Few-Shot Performance of LanguageModels(https://arxiv.org/abs/2102.09690)。
我们采用解决的方法是通过无文本输入对带偏置的标签词进行补偿,把它们校准为无偏状态,减少不同提示选择之间的差异。
具体实现:
输入无文本样例,即将无文本["N/A", " ", "[MASK]"]分别和2.1设计的提示模板组合,如"N/A"与EPRSTMT提示模板组成输入样例:“N/A。总体来说,该产品很__”;
将无文本样例输入语言模型,输出标签词位置对应的所有类别概率(logits),并取平均值后归一化得到 ;
;
将验证集样本与提示模板组合为验证集样例输入语言模型,输出校正前所有类别概率 。
。
根据公式
![]()
计算校正后类别概率。其中有两种方案:一、当通过
![]()
计算校正矩阵时,
![]()
;二、当通过
![]()
计算校正矩阵时,
![]()
。
需要特别注意的是,为了同时校正标签词和输入样本带来的偏置,我们还提出了将训练集或验证集样本替代无文本["N/A"," ", "[MASK]"]计算校正矩阵的方法,使得模型可以根据输入数据分布进行校正。实验结果如表3所示。
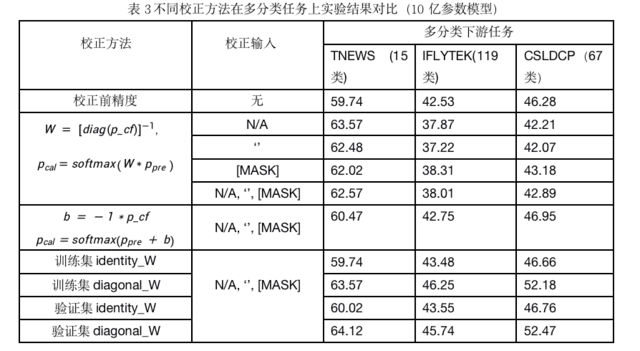
综合来看,通过数据集校正,效果更佳。
标签扩展
在理想状态下,所有标签在预训练语料中的出现频率应该大致相同。但是在实验中,我们发现标签在语料中出现的频率存在差异,使得模型对预测结果有偏好性。在实际应用中,人工从接近6万的词表空间中选择符合条件的标签映射词是非常困难的,而且通常会引入主观因素(参考论文KnowledgeablePrompt-tuning: Incorporating Knowledge into Prompt Verbalizer forText Classification)。因此我们采用word2vec算法和人工结合方式,扩展标签词步骤如下:
(1)通过word2vec初步筛选出与原标签相近,并在词表中的标签;
(2)在初步筛选候选集中再人工精选,删去稀有词,尽可能找先验分布相近的标签词对。
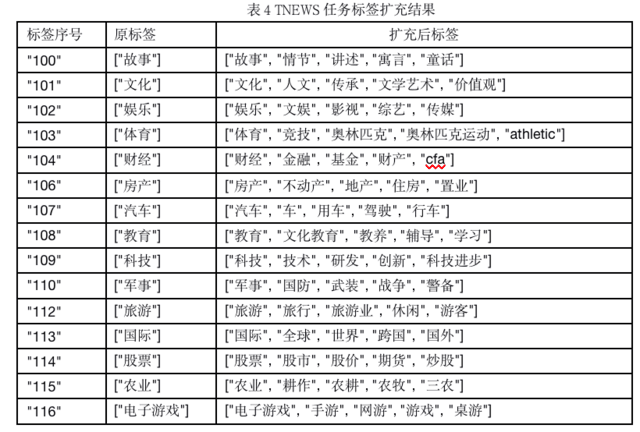
标签扩展与校准结合
将2.3扩展标签词与2.2校准相结合提出三种校正优化方案,在实际应用中可根据测试选择:
方法一:先通过模型对扩充后标签映射词计算其相应概率,然后按类别取平均,最后再校正;
方法二:先通过模型对扩充后标签映射词计算其相应概率,然后按类别取至大值,最后再校正;
方法三:先通过模型对扩充后标签映射词计算其相应概率,然后分别进行校正,最后按类别取平均。

“源1.0”在CLUE榜单单句分类任务上的应用方法举例
中文语言理解测评基准(CLUE,https://www.cluebenchmarks.com/)是目前公认权威的中文语言模型评估基准,提供了一个由语言学家创建的诊断评估数据集,覆盖多个不同程度的语言任务,具有广泛代表性。代码地址:https://github.com/chineseGLUE/chineseGLUE。
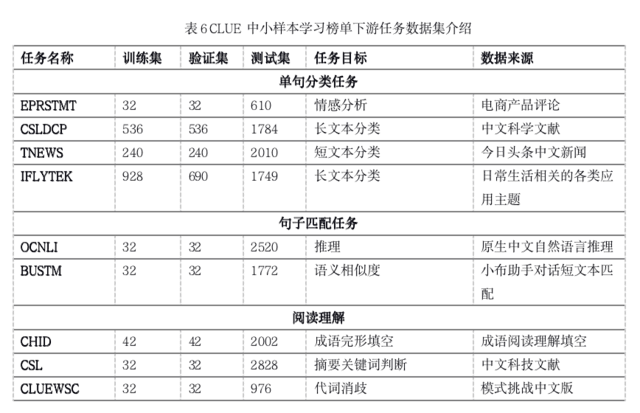
单句分类任务包括情感分类(Eprstmt:用于情感分析的电子商务产品评论数据集)、新闻标题分类(Tnews:ToutiaoShort Text Classificaiton forNews)、应用描述分类(Iflytek:长文本分类)和学科分类(Csldcp:中国科学文献学科分类)。Eprstmt是二分类任务,包括带有正面和负面产品评论。Tnews、Iflytek和Csldcp是多分类任务,分别有15、118和67个类别。如果标签为0 或1或是英文,我们会将标签转换为中文。如果标签长于一个标记,我们将标签转换为一个标记的长度,并确保其具有相同或相似的含义。对于所有文本分类任务,标签都附加在句子的末尾,句子和标签直接用提示词链接。我们的生成模型会根据给定的句子预测标签,并计算每个候选标签的概率P(label|sentence),其中概率至大的是模型预测结果。
预训练好的“源1.0”千亿参数模型,结合下游任务优化方法,在零样本学习榜单中,超越业界极佳成绩18.3%,并在文献分类、新闻分类,商品分类、原生中文推理、成语阅读理解填空、名词代词关系6项任务中获得冠军。

图2Zero榜单打榜结果
关于“源1.0”的更多信息,大家可以参照浪潮人工智能研究院发布在arxiv上的论文:https://arxiv.org/abs/2110.04725。