NeRF学习
《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》,ECCV2020,将场景表示为用于视图合成的神经辐射场。
NeRF(Neural Radiance Fields)其实是一种三维场景表示(scene representation),而且是一种隐式的场景表示(implicit scene representation),因为不能像point cloud、mesh、voxel一样直接看见一个三维模型。
NeRF将场景表示为空间中任何点的volume density 和颜色值 。 有了以NeRF形式存在的场景表示后,可以对该场景进行渲染,生成新视角的模拟图片。论文使用经典体积渲染(volume rendering)的原理,求解穿过场景的任何光线的颜色,从而渲染合成新的图像。
相关知识
渲染,就是利用已经建立好的三维模型,重构出物体的表面点,再根据相机投影关系,生成任意视角的2D图像,也就是模拟人眼对物体的观察过程。
体绘制(Volume Rendering)
为了渲染三维数据集的二维投影,首先需要定义相机相对于几何体的空间位置。另外,需要定义每个点即体素的不透明性以及颜色,这通常使用RGBA(red, green, blue, alpha)传递函数定义每个体素可能值对应的RGBA值。
Ray Marching(光线步进)
原理:从摄像机位置向屏幕每一个像素点发射一条光线,光线按照一定步长前进,并检测当前光线是否位于物体表面,据此调整光线前进幅度,直到抵达物体表面,再按照一般光线追踪的方法计算颜色
详细知识点击链接
笔记中的颜色相当于R、G、B三种颜色的混合,因为积分中的C(r(t))表示的是R、G、B的向量,通过上图中的表达式可以求出不同角度下的颜色。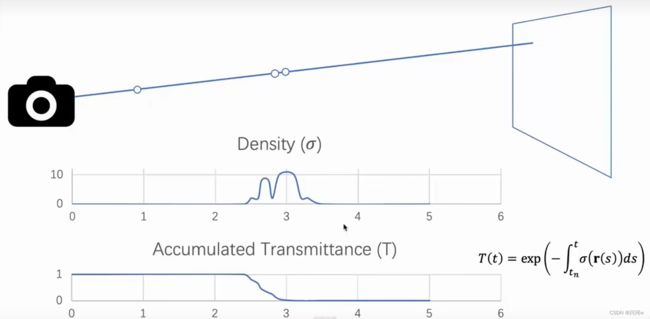
由上图可以看出,虽然第一个体密度较小,但它处于光线首先接触的位置,所以该位置吸收光线的更多,后面虽然体密度更大,但是已经被吸收了很多光线,所以该处吸收的光线较少。下图表示光线吸收的多少,一开始没有被吸收为1,后面逐渐被吸收所以降低到0。
从T的公式可以看出:当体密度为0时,也就是相机到物体之间的这一段距离(空气),积分为0,exp0 也就是1,T=1表示没有光线的减少,当接触物体前面的表面时,体密度有值,积分大于0,这个时候exp就会降低小于1,这时候T的值就会小于1,表示剩余的光线,减少的值就是当前表面(这一小段区域)吸收的光。
摘要
我们提出一种方法,使用较少的视图(view)作为输入,对一个连续、隐含的体积场景函数(volumetric scene function)进行优化,从而实现了关于复杂场景的新视图合成的最先进的结果。
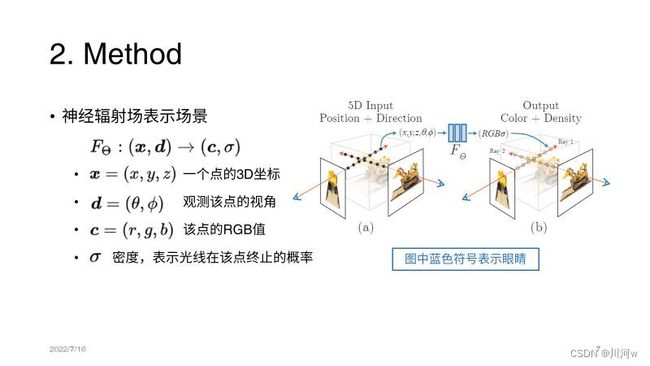
我们的算法用全连接深度网络来表示场景,其输入是 5D 坐标:空间位置 (x,y,z) 和视角方向(viewing direction) (θ,ϕ);其输出是体积密度(volume density)和该空间位置上发射出来的辐射亮度(radiance,与视角相关)。
通过沿着相机光线(camera rays)获取 5D 坐标,使用经典的立体渲染(volume rendering)技术,我们将输出的颜色和密度投影到图像上,从而实现视图合成。
由于立体渲染是可导的,神经网络的优化,只需要提供一系列确定相机位姿的图像。
流程如下图
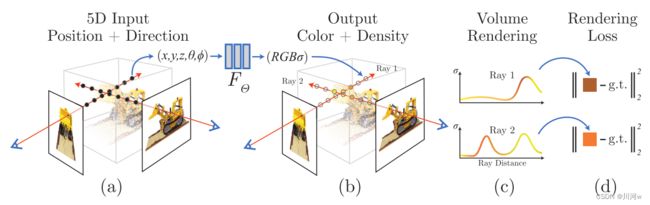
(1)对于给定的相机光线,在这条光线上采样
(2)使用采样的点和光线进入的方向等参数,计算该点的密度和颜色
(3)通过volume rendering,聚集光路上的点的颜色和密度,生成最终的2D图像
(4)生成的2D图像和ground truth比较,最小化误差,并且优化颜色和密度
对于复杂的场景,用简单的方法优化 NeRF 效果不理想。所以后面提出了一些提升方法。
网络结构
首先输入坐标,经过残差网络之后输出密度,再输入视角,把视角信息加入进来,经过MLP之后输出RGB,这样,密度信息是视角无关的。如下图
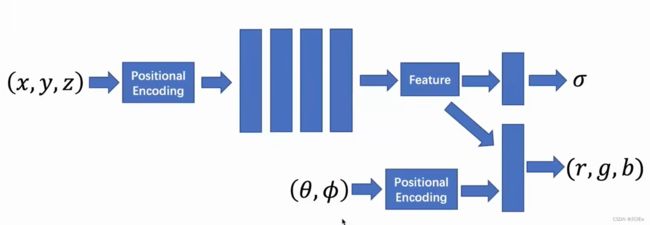
在具体实现上,MLP FΘ 首先用 8 层的全连接层(使用 ReLU 激活函数,每层有 256 个通道),处理 3D 坐标 x,得到 σ 和一个 256 维的特征向量。
这个 256 维的特征向量,与视角方向一起拼接起来,喂给另一个全连接层(使用 ReLU 激活函数,每层有 128 个通道),输出方向相关的 RGB 颜色。
以上操作就是5D神经辐射场,把场景表示为:任意空间点上的体积密度和有方向的辐射亮度。
立体渲染
由上面介绍的立体渲染可知,通过该操作可以渲染出任意射线穿过场景的颜色。在最近和最远边界为 tn 和 tf 的条件下,相机光线 r(t)=o+td 的颜色 C® 为:

函数 T(t) 表示沿着光线从 tn 到 t 所累积的透明度(accumulated transmittance),即光线从 tn 出发到 t,穿过该路径的概率。视图的渲染需要求这个积分 C®,它是就是虚拟相机穿过每个像素的相机光线,所得到的颜色。
MLP不适合积分计算,将积分进行离散操作,将物体区间分成均匀分布的小区段,再接着对每个小区段进行均匀采样
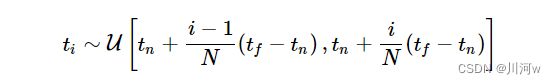
得到如下公式

提升方法
1、用一个位置编码(positional encoding)对输入 5D 坐标进行变换,使得 MLP 可以表示高频函数。
该位置编码类似傅里叶变换,将x、y、z进行变换在输入网络中。
2、提出层次化的采样流程(hierarchical sampling procedure),减少重复采样。这里优化两个网络:粗糙网络和精细网络。粗糙网络采用均匀采样的方式,每一小区段内随机采样,进行计算输出;根据粗糙网络的输出,沿着光线生成更明智的采样点,主要选择集中在光线有变化的地方的点,这类点是主要计算密度颜色的区域,再将第一个网络的采样点加上,通过这种精细网络可以计算最终的光线颜色。
总结下来,本文的贡献如下:
1、包含复杂几何和材质的连续场景的表示方法:使用参数化为 MLP 的 5D 神经辐射场;
2、基于立体渲染技术的可导的渲染流程,用于网络的优化。其中还包括层次化的采样策略,专注于可见的场景内容(visible scene content),充分利用了 MLP 的容量。
3、使用位置编码,将输入 5D 坐标映射到更高维的空间,让 NeRF 可以学习表示高频的场景内容。
代码复现
这里复现的是pytorch版本:https://github.com/yenchenlin/nerf-pytorch
首先需要新建虚拟环境
conda create -n nerfpy37 python=3.7
conda activate nerfpy37
下载依赖
pip install -r requirements.txt
没有进行训练,直接使用预训练模型进行测试。
https://drive.google.com/drive/folders/128yBriW1IG_3NJ5Rp7APSTZsJqdJdfc1
需要下载这两个文件,放到data文件中。
再下载该链接中的全部文件https://drive.google.com/drive/folders/1jIr8dkvefrQmv737fFm2isiT6tqpbTbv
将下载的的文件存放在logs目录中,就不需要修改config.txt中的参数路径了。
目录如下图
运行下面命令:
python run_nerf.py --config configs/{DATASET}.txt --render_only
替换 {DATASET} 用 trex | horns | flower | fortress | lego | etc.

测试结束可以再该目录下得到输出
以及一个video
学习参考
https://www.cnblogs.com/noluye/p/14547115.html
https://zhuanlan.zhihu.com/p/542377272
https://blog.csdn.net/YuhsiHu/article/details/124292026?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-124292026-blog-122664056.pc_relevant_3mothn_strategy_recovery&spm=1001.2101.3001.4242.2&utm_relevant_index=4
https://blog.csdn.net/BIT_HXZ/article/details/127260532?spm=1001.2014.3001.5506