Seaborn库的基本绘图操作
Seaborn库的基本绘图操作
#seaborn库可视化模板
#导库
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
# 设置中文字体
sns.set_style('whitegrid', {'font.sans-serif':['simhei', 'Arial']})
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
#加载数据
data = pd.read_csv('.../data.csv')
一、seaborn的绘图风格
1、主题样式
seaborn库中有darkgird(灰色背景+白网格)、whitegrid(白色背景+黑网格)、dark(仅灰色背景)、white(仅白色背景)、ticks(坐标轴带刻度)5种预设的主题。
个人推荐whitegrid或white
darkgrid与whitegrid主题有助于在绘图时进行定量信息的查找
dark与white主题有助于防止网格与表示数据的线条混淆
ticks主题有助于体现少量特殊的数据元素结构
set_style( )修改主题,默认主题为darkgrid
sns.set_style( style = None , rc = None)
set_style函数只能修改axes_style函数显示的参数,axes_style函数可以达到临时设置图形样式的效果。
x = np.arange(1, 10, 2)
y1 = x + 1
y2 = x + 3
y3 = x + 5
def showLine(flip=1):
sns.lineplot(x, y1)
sns.lineplot(x, y2)
sns.lineplot(x, y3)
pic = plt.figure(figsize=(12, 8))
with sns.axes_style('darkgrid'): # 使用darkgrid主题
pic.add_subplot(2, 3, 1)
showLine()
plt.title('darkgrid')
with sns.axes_style('whitegrid'): # 使用whitegrid主题
pic.add_subplot(2, 3, 2)
showLine()
plt.title('whitegrid')
with sns.axes_style('dark'): # 使用dark主题
pic.add_subplot(2, 3, 3)
showLine()
plt.title('dark')
with sns.axes_style('white'): # 使用white主题
pic.add_subplot(2, 3, 4)
showLine()
plt.title('white')
with sns.axes_style('ticks'): # 使用ticks主题
pic.add_subplot(2, 3, 5)
showLine()
plt.title('ticks')
sns.set_style(style='darkgrid', rc={'font.sans-serif': ['MicrosoftYaHei', 'SimHei'],
'grid.color': 'black'}) # 修改主题中参数
pic.add_subplot(2, 3, 6)
showLine()
plt.title('修改参数')
plt.show()

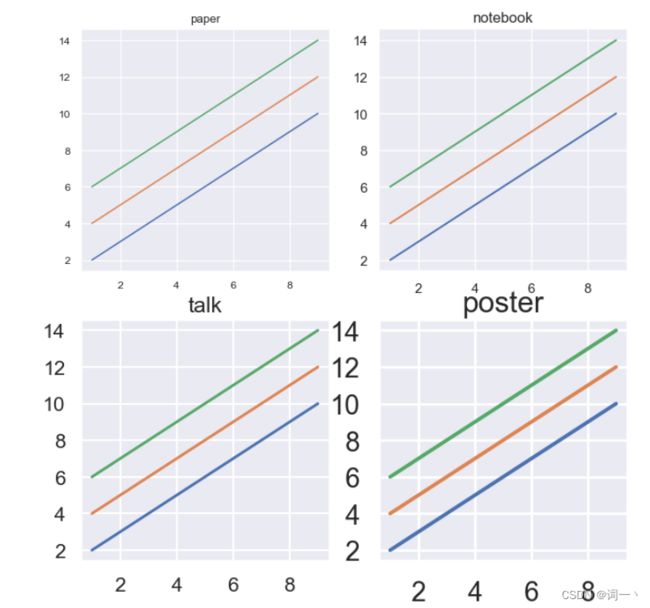
2、元素缩放
set_context( )可以设置输出图形的尺寸,默认为None
context参数可接收paper、notebook、talk、poster类型
paper < notebook < talk < poster
使用set_context函数只能修改plotting_context函数显示的参数,plotting_context函数通过调整参数来改变图中标签、线条或其他元素的大小,但不会影响整体样式
sns.set_context( context = None , font_scale = 1, rc = None )
sns.set()
x = np.arange(1, 10, 2)
y1 = x + 1
y2 = x + 3
y3 = x + 5
def showLine(flip=1):
sns.lineplot(x, y1)
sns.lineplot(x, y2)
sns.lineplot(x, y3)
pic = plt.figure(figsize=(8, 8))
# 恢复默认参数
pic = plt.figure(figsize=(8, 8), dpi=100)
with sns.plotting_context('paper'): # 选择paper类型
pic.add_subplot(2, 2, 1)
showLine()
plt.title('paper')
with sns.plotting_context('notebook'): # 选择notebook类型
pic.add_subplot(2, 2, 2)
showLine()
plt.title('notebook')
with sns.plotting_context('talk'): # 选择talk类型
pic.add_subplot(2, 2, 3)
showLine()
plt.title('talk')
with sns.plotting_context('poster'): # 选择poster类型
pic.add_subplot(2, 2, 4)
showLine()
plt.title('poster')
plt.show()
3、边框控制
despine( )可以移除任意位置的边框、调节边框的位置、修剪边框的长度
sns.despine( fig = None , ax = None , top = True , right = True , left = False , bottom = False , offset = None , trim = False )
| 参数 | 说明 |
|---|---|
| top | 接收boolean,表示删除顶部边框。默认为True |
| right | 接收boolean,表示删除右侧边框。默认为True |
| left | 接收boolean,表示删除左侧边框。默认为False |
| bottom | 接收boolean,表示删除底部边框。默认为False |
| offset | 接收int或dict,表示边框与坐标轴的距离。默认为None |
| trim | 接收boolean,表示将边框限制为每个非扭曲轴上的最小和最大主刻度。默认为False |
#无参数despine()
with sns.axes_style('white'):
showLine()
sns.despine() # 默认无参数状态,就是删除上方和右方的边框
plt.title('控制图形边框')
plt.show()

#边框与坐标轴的距离为10
with sns.axes_style('white'):
data = np.random.normal(size=(20, 6)) + np.arange(6) / 2
sns.boxplot(data=data)
sns.despine(offset=10, left=False, bottom=False)
plt.title('控制图形边框')
plt.show()

二、绘制关系图
1、散点图—sns.scatterplot( )
# 加载数据
hr = pd.read_csv('../data/hr.csv', encoding='gbk')
# 提取部门为产品开发部、离职为1的数据
product = hr.iloc[(hr['部门'].values=='产品开发部') & (hr['离职'].values==1), :]
ax = sns.scatterplot(x='评分', y='每月平均工作小时数(小时)', data=product)
plt.title('评价分数与平均工作时间散点图')
plt.show()

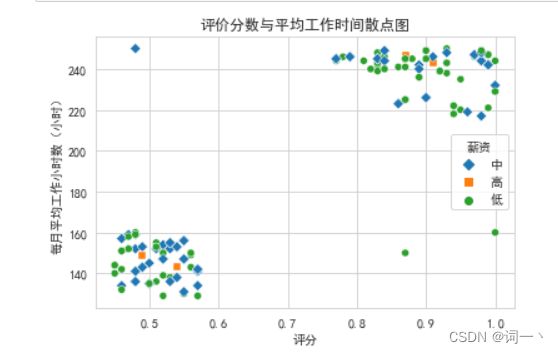
#通过对点着色和改变标记来突显类别
markers = {'低' : 'o', '中' : 'D', '高' : 's'}
sns.scatterplot(x='评分', y='每月平均工作小时数(小时)',hue='薪资',
style='薪资', markers=markers, data=product)
plt.title('评价分数与平均工作时间散点图')
plt.show()
2、折线图—sns.lineplot( )
主要参数:
estimator:接收pandas方法,可调用函数、None。表示y在同一x级别的聚合方法。默认为mean
ci:接收int、sd、None,表示使用estimator参数聚合的置信区间大小,sd表示数据标准差。默认为95
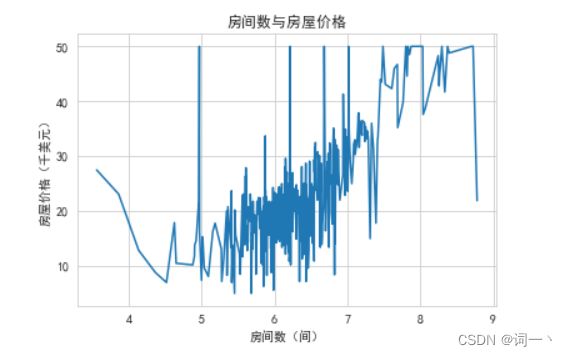
# 绘制房间数和房屋价格的折线图
boston = pd.read_csv('../data/boston_house_prices.csv', encoding='gbk')
sns.lineplot(x='房间数(间)', y='房屋价格(千美元)', data=boston, ci=0)
plt.title('房间数与房屋价格')
plt.show()
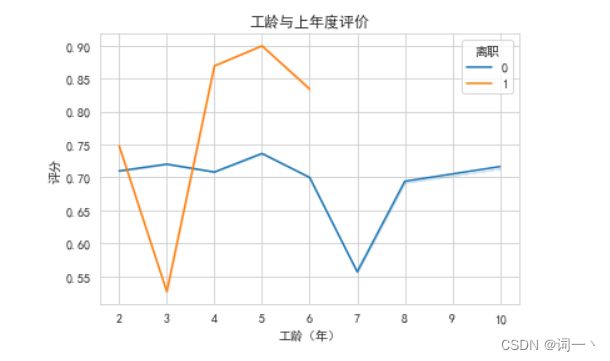
# 绘制工龄和评分折线图
IT = hr.iloc[hr['部门'].values=='IT部', :]
sns.lineplot(x='工龄(年)', y='评分', hue='离职', data=IT, ci=0)
plt.title('工龄与上年度评价')
plt.show()
3、热力图—heatmap( )
plt.rcParams['axes.unicode_minus'] = False
#plt.figure(figsize=(16, 12))
corr = boston.corr() # 特征的相关系数矩阵
sns.heatmap(corr)
plt.title('特征矩阵热力图')
plt.show()
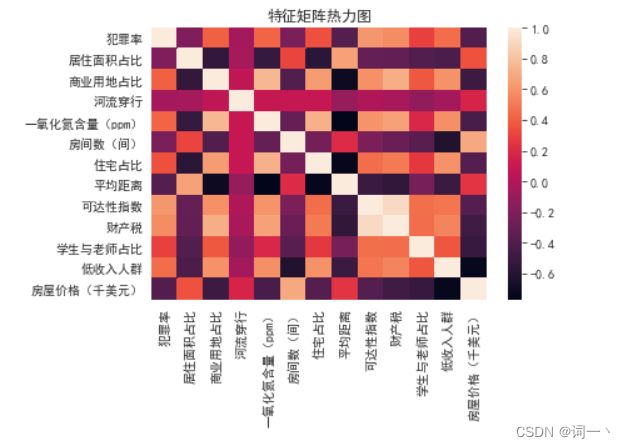
#添加数据标记
plt.figure(figsize=(10, 10))
sns.heatmap(corr, annot=True, fmt='.2f')
plt.title('特征矩阵热力图')
plt.show()

4、矩阵网格图—PairGrid( )
PairGrid( )可用于绘制数据关联程度的网格图
PairGrid( )将数据集中的每个变量映射到多个网格中的列和行,并可以使用不同的绘图函数绘制上三角和下三角的双变量图,显示数据集中变量的两两之间的关系。
#绘制犯罪率、一氧化氮含量、房间数与房屋价格两两之间的相关性网格图
g = sns.PairGrid(boston, vars=['犯罪率', '一氧化氮含量(ppm)', '房间数(间)', '房屋价格(千美元)'])
g = g.map(plt.scatter)
plt.suptitle('矩阵网格图', verticalalignment='bottom' , y=1)
plt.show()

# 绘制不同颜色的数据子集
sell = hr.iloc[(hr['部门'].values=='销售部') & (hr['离职'].values==1), :]
g = sns.PairGrid(sell,
vars=['满意度', '评分', '每月平均工作小时数(小时)'],
hue='薪资', palette='Set3')
g = g.map_diag(sns.kdeplot)
g = g.map_offdiag(plt.scatter)
plt.suptitle('不同颜色的矩阵网格图', verticalalignment='bottom' , y=1)
plt.show()

5、关系网格组合图—relplot( )
relplot( )可以实现统一访问scatterplot函数和lineplot函数以绘制关系网格组合图
#绘制单构面散点图
sns.relplot(x='满意度', y='评分', hue='薪资',
data=sell)
plt.title('满意度水平与上年度评价')
plt.show()

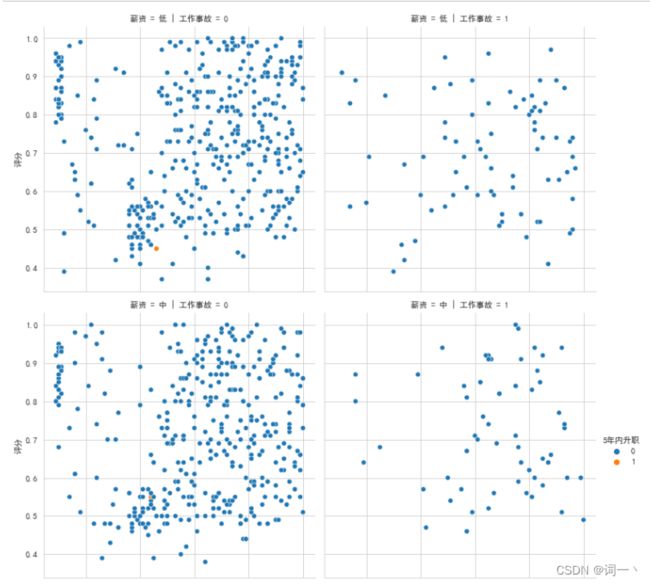
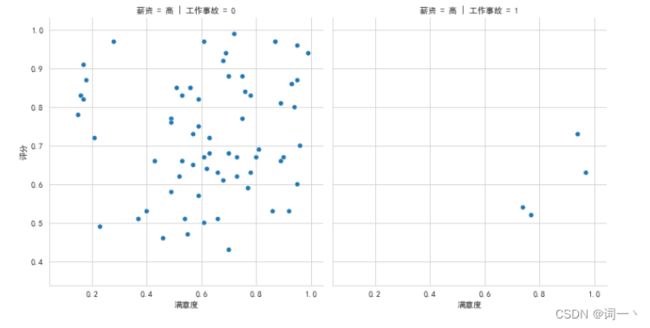
#绘制网格图
sns.relplot(x='满意度', y='评分', hue='5年内升职', row='薪资',
col='工作事故', data=IT)
plt.show()
sns.relplot(x='满意度', y='评分', hue='5年内升职', col='工作事故',
col_wrap=1, data=IT)
plt.show()

三、绘制分类图
1、条形图—barplot( )
from matplotlib import pyplot as plt
import pandas as pd
import seaborn as sns
import math
# 加载数据
boston = pd.read_csv('E:/桌面/源代码+实验数据/第4章/data/boston_house_prices.csv', encoding='gbk')
hr = pd.read_csv('E:/桌面/源代码+实验数据/第4章/data/hr.csv', encoding='gbk')
# 使用seaborn库绘图
sns.set_style('whitegrid', {'font.sans-serif':['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置正常显示负号
plt.rcParams['axes.unicode_minus']=False
# 绘制各部门人员总数条形图
count = hr['部门'].value_counts()
index = count.index
sns.barplot(x=count, y=index)
plt.xticks(rotation=70)
plt.xlabel('部门')
plt.ylabel('总数')
plt.title('各部门人数对比')
plt.show()

2、计数图—countplot( )
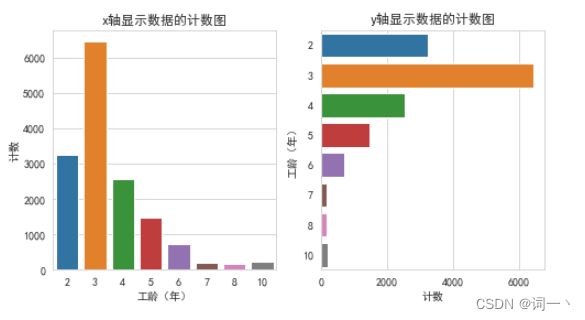
#绘制x轴与y轴显示数据的计数图
plt.figure(figsize=(8, 4))
plt.subplot(121) #画布分成一行二列,该子图表示为第一个
sns.countplot(x='工龄(年)', data=hr)
plt.title('x轴显示数据的计数图')
plt.ylabel('计数')
plt.subplot(122) #画布分成一行二列,该子图表示为第二个
sns.countplot(y='工龄(年)', data=hr)
plt.title('y轴显示数据的计数图')
plt.xlabel('计数')
plt.show()
# 绘制多分类嵌套的计数图
sns.countplot(x='5年内升职', hue='薪资', data=hr, palette='Set2')
plt.suptitle('多变量散点图')
plt.ylabel('总数')
plt.show()

3、绘制单变量分布图(直方图)—distplot( )
#绘制单变量分布图
sns.distplot(boston['财产税'], kde=False)
plt.title('单变量的分布图')
plt.ylabel('数量')
plt.show()

4、绘制分类散点图—stripplot( )、swarmplot( )
(1)stripplot( )
stripplot( )接收多种类型的传递数据,包括列表、Numpy阵列、数据框(DataFrame)、序列(Series)、数组或向量。
主要参数:
jitter:表示添加均匀随机噪声(仅改变图形)来优化图形显示。默认为True。
#绘制简单水平分布散点图
sale = hr.iloc[(hr['部门'].values=='销售部') & (hr['离职'].values==1), :]
sns.stripplot(x=sale['每月平均工作小时数(小时)'])
plt.title('简单水平分布散点图')
plt.show()

#添加随机噪声抖动
hr1 = hr.iloc[hr['离职'].values==1, :]
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.xticks(rotation=70)
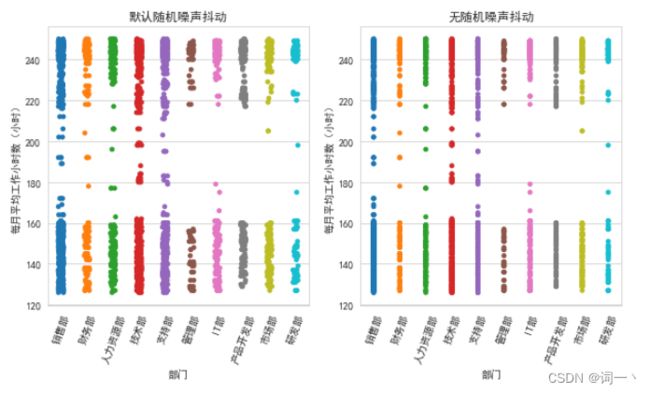
sns.stripplot(x='部门', y='每月平均工作小时数(小时)', data=hr1) # 默认添加随机噪声
plt.title('默认随机噪声抖动')
plt.subplot(122)
plt.xticks(rotation=70)
sns.stripplot(x='部门', y='每月平均工作小时数(小时)',
data=hr1, jitter=False) # 不添加随机噪声
plt.title('无随机噪声抖动')
plt.show()
#以颜色显示第二个分类条件
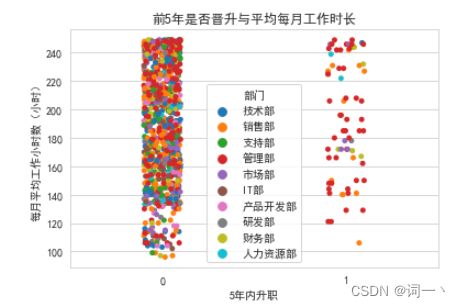
hr2 = hr.iloc[(hr['薪资'].values=='高') & (hr['离职'].values==0), :]
sns.stripplot(x='5年内升职', y='每月平均工作小时数(小时)',
hue='部门', data=hr2, jitter=True)
plt.title('前5年是否晋升与平均每月工作时长')
plt.show()
#使变量沿分类轴方向分类
plt.figure(figsize=(70, 13))
plt.subplot(211)
plt.xticks(rotation=70)
plt.title('不同部门的平均每月工作时长')
sns.stripplot(x='部门', y='每月平均工作小时数(小时)', hue='5年内升职', data=hr2)
plt.subplot(212)
plt.xticks(rotation=70)
sns.stripplot(x='部门', y='每月平均工作小时数(小时)', hue='5年内升职',
data=hr2, dodge=True)
plt.show()

(2)swarmplot( )
用stripplot函数添加随机噪声来增加图形抖动及将变量沿着分类轴绘制后,仍然有重叠的可能。
使用swarmplot函数可以避免这种情况,swarmplot函数能够绘制出具有非重叠点的分类散点图。
#绘制简单的分布密度散点图
sns.swarmplot(x='部门', y='每月平均工作小时数(小时)', data=hr2)
plt.xticks(rotation=70)
plt.title('不同部门的平均每月工作时长')
plt.show()
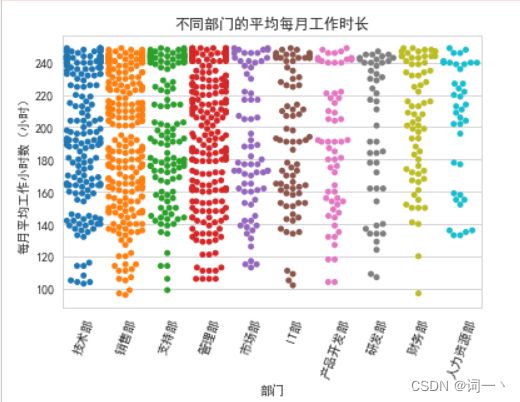
#添加多个嵌套分类变量
sns.swarmplot(x='部门', y='每月平均工作小时数(小时)',
hue='5年内升职', data=hr2)
plt.xticks(rotation=30)
plt.title('不同部门的平均每月工作时长')
plt.show()

5、绘制增强箱线图—boxenplot( )
#绘制普通箱线图与增强箱线图
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes[0].set_title('普通箱线图')
boston['房间数(取整)'] = boston['房间数(间)'].map(math.floor) # 对房间数取整
sns.boxplot(x='房间数(取整)', y='房屋价格(千美元)',
data=boston, orient='v', ax=axes[0]) # 普通
axes[1].set_title('增强箱线图')
sns.boxenplot(x='房间数(取整)', y='房屋价格(千美元)',
data=boston, orient='v', ax=axes[1]) # 增强
plt.show()

6、绘制分类网格组合图—pairplot( )
使用分类网格组合图可绘制出数据集中的成对关系
#绘制波士顿房价的多变量散点图
sns.pairplot(boston[['犯罪率', '一氧化氮含量(ppm)', '房间数(间)', '低收入人群', '房屋价格(千美元)']])
plt.suptitle('多变量散点图', verticalalignment='bottom', y=1)
plt.show()

#绘制指定分类变量的散点图
hr3 = sale[['满意度', '总项目数', '工龄(年)', '薪资']]
sns.pairplot(hr3, hue='薪资')
plt.suptitle('多变量分类散点图', verticalalignment='bottom')
plt.show()

四、绘制回归图
1、绘制线性回归拟合图—regplot( )
from matplotlib import pyplot as plt
import pandas as pd
import seaborn as sns
# 设置中文字体
sns.set_style('whitegrid', {'font.sans-serif':['simhei', 'Arial']})
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 加载数据
boston = pd.read_csv('../data/boston_house_prices.csv', encoding='gbk')
#绘制修改置信区间ci参数前后的线性回归拟合图
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes[0].set_title('修改前的线性回归拟合图')
axes[1].set_title('修改后的线性回归拟合图')
sns.regplot(x='房间数(间)', y='房屋价格(千美元)', data=boston, ax=axes[0])
sns.regplot(x='房间数(间)', y='房屋价格(千美元)', data=boston, ci=50, ax=axes[1])
plt.show()

2、绘制线性回归网格组合图—lmplot( )
#以河流穿行为类别绘制低收入人群与房屋价格两个变量的回归网格组合图
sns.lmplot(x='低收入人群', y='房屋价格(千美元)', col='河流穿行', data=boston)
plt.show()
‘…/data/boston_house_prices.csv’, encoding=‘gbk’)
#绘制修改置信区间ci参数前后的线性回归拟合图
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes[0].set_title(‘修改前的线性回归拟合图’)
axes[1].set_title(‘修改后的线性回归拟合图’)
sns.regplot(x=‘房间数(间)’, y=‘房屋价格(千美元)’, data=boston, ax=axes[0])
sns.regplot(x=‘房间数(间)’, y=‘房屋价格(千美元)’, data=boston, ci=50, ax=axes[1])
plt.show()
[外链图片转存中...(img-AgfMs08W-1664038679472)]
### 2、绘制线性回归网格组合图—lmplot( )
```python
#以河流穿行为类别绘制低收入人群与房屋价格两个变量的回归网格组合图
sns.lmplot(x='低收入人群', y='房屋价格(千美元)', col='河流穿行', data=boston)
plt.show()
