一个C语言的基本教程——结构体与联合篇
文章目录
- 11.自定义数据类型——结构体与联合
-
-
- (1). 先介绍一下typedef语句
- (2). 什么是面向对象程序设计
- (3). 终于来了,结构体!
-
- #1.新建一个结构体
- #2.定义结构体类型的变量
- #3.让结构体变得顺手一点
- (4). 结构体数组与结构体指针
-
- #1.结构体数组
- #2.结构体指针与结构体排序
- (5). 会自动变长的数组
-
- #1.先确定一下我们要干什么
- #2.先定义一下结构体
- #3.初始化函数(构造函数)
- #4.setter与getter函数
- #5.其它函数
- #6.综合代码
- #7.然后来看看C++和Java中的自动变长数组
- (6). 来做个链表试试看
-
- #1.什么是链表以及为什么是链表
- #2.我们要做点什么呢?
- #3.初始化和插入函数
- #4.删除函数
- #5.查找、打印和析构
- #6.综合代码
- (7). 结构体和内存占用
-
- #1.先来看看几个内存占用
- #2.怎么还会有不同?
- (8). 联合(union)
- 小结
-
11.自定义数据类型——结构体与联合
之前我们学习的各种知识已经够解决很多很多问题了,小明也是这么想,他每天都在OJ上刷题,不亦乐乎,然后有一天碰到了这样的问题:传入一组学生的学号和成绩,请按照平均成绩从大到小排序,然后一次一行输出“学号:成绩1 成绩2 成绩3 平均成绩”。
这个问题看起来很挺简单的,我写一个compare函数然后用qsort排一下序就好了,不过问题来了,首先这些数据用什么存呢?数组是一个不错的选择,不过排序的时候小明犯难了,就算我把三组成绩取个平均排序,成绩是排好了,但学号的数组没有变化啊,这可咋办?我们其实可以这么做:
#include 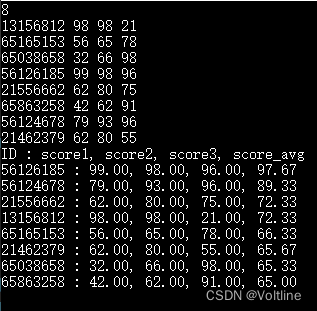
完成,这个程序完成了我们的需求。思路是这样的:既然我们没有办法一次性完成所有数组的排序,那就干脆不排序了,我们给每个学生分配一个索引,在排序的时候通过索引值访问平均成绩的数组获得成绩的值,再比较,之后我们就得到了有序的序号数组,输出的时候按照对应序号输出就行了。
不过你可能也发现了,这是不是有点太麻烦了,假设我们能够有一种数据类型就叫做Student,然后其中存储了学号、各科成绩和平均成绩,我们就不用开好几个数组了。C语言的确是提供了这种东西,我们马上就来介绍。
(1). 先介绍一下typedef语句
不知道大家有没有不想敲long long的时候,我总是有的,平时写一些题目的时候因为int和unsigned int不够就得开long long,但是它名字真的很长,有没有什么好用的办法呢?
C语言提供了一种语句叫做typedef,它可以让我们给已有的数据类型起别名,它的基本结构如下:
typedef 已有数据类型名 新名字;
例如我们可以这么写:
#include ![]()
一切正常,的确是很方便呢。
(2). 什么是面向对象程序设计
先不管它是什么,我觉得你应该听过这个名词,面向对象程序设计英文名叫做Object-Oriented-Programming,简称OOP,简单来说就是,我们可以把程序设计中用到的一类事物的属性和方法抽象出来形成一个类型,然后通过这个类型派生出许多对象,在程序设计中对对象进行一定的操作。
举个例子,人类就是一种类型,有这样一些属性:身高、体重、性别、体脂率等等,还有这样一些方法:走、跑、吃饭、抓、跳等等。假设我们程序中涉及了对人类的操作,通过人类派生一个对象的方式再去操作就很简单了,我们可以很快地批量产生一大堆人类的对象。
当然,上面这个例子有点吓人哈,我们回头看看开头说的那道题,假设有一个叫做Student的类,那么它就有:学号、各科成绩、平均成绩等属性,方法有没有其实无所谓,那这么一来,我们再创建一个个student对象,好像就能够做到之前说的把这些东西全部打包起来了呢!没错,面向对象程序设计的一大重要应用就是自定义数据类型。
面向对象程序设计的这种模式有三个特征:多态、继承和封装。在后续的各种支持面向对象的语言如Java、Python、C++等都完全支持了这三个特征,但是C语言没有,我们虽然可以以面向对象的思路在C中去设计程序,但是没有语言中原生的特性提供给我们,不过先不提那么多,我们可以先试试实现自定义数据类型这件事情,这就要用到struct(结构体) 了!
(3). 终于来了,结构体!
#1.新建一个结构体
现在我们就可以来介绍一下把数据打包起来成为新的数据类型的东西了,在C语言中,我们使用struct(结构体)完成这个过程。结构体的使用方式如下:
struct [Name] {
...
} [Object];
其中Name是这个结构体的名字,中间的部分你可以写各种不同类型的变量,这是你的自由,而Object是一个该结构体类型的变量,我们在定义结构体的时候就可以直接创建一个对象,这有什么好处呢?简单来说,假设你定义的结构体只需要用到一次,就可以直接在定义的时候赋给一个变量,并且此时[Name]是可以留空的,例如:
struct {
long long id;
double score1;
double score2;
double score3;
double score_avg;
} student;
那么就只有student属于这个结构体,后续我们没有办法再定义一个新的结构体变量:因为我们所定义的这个结构体变量没有名字。
#2.定义结构体类型的变量
当然,我们之前说的学生排序问题当中,还是要用到很多个student结构体变量的,如果我们要创建一个新的结构体变量,我们得这么做:
#include ![]()
这段代码中有好几个重点需要注意:
- 定义结构体的时候右半大括号要记得加分号
- 定义某结构体类型变量的时候不仅要加结构体名,还要加上struct关键字
- 给结构体变量赋初始值的时候可以采用类似数组赋初始值的方法
- 访问一个结构体对象的属性的时候使用"."加上属性的名字
#3.让结构体变得顺手一点
然后你注意到了,这个struct student s用的很不顺手啊,还记得我们之前说的typedef语句吗,这里就可以派上用场了:
#include 运行结果就不放了,你跑跑就会发现完全可以正常运行。当我们用typedef给struct赋别名的时候,我们就可以不用给struct起名字了,只要在结构体定义之后加上它的别名就好了。当然你要是想也是可以的,比如这样:
typedef struct student {
long long id;
double score1;
double score2;
double score3;
double score_avg;
} Student; // 注意最后要加分号!!
(4). 结构体数组与结构体指针
#1.结构体数组
我们自定义的结构体当然属于一种数据类型啦,所以当然可以创建一个结构体类型的数组:
#include 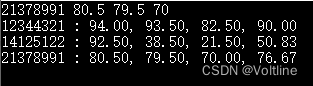
说到这里是不是感觉有点意思了?我们先来说说这个:
(Student){id, score1, score2, score3, score_avg};
这条语句可以把几个数据捆绑在一起然后转换成一个Student对象,然后其中的每个元素会按照结构体定义中的顺序赋值给一个结构体的id、score1、score2、score3、score_avg,当然也可以这么做:
(Student){.id = id, score1, .score2 = score3, .score3 = score2, score_avg};
这是利用初始化器进行结构体初始化的操作,假设我们要像数组那样指定某一位(在这里是指定某一个成员变量的值),需要使用.+成员变量名。
这个写法我也是第一次知道,之前一般都是创建一个temp变量用来存,然后再给students[i]赋值来实现。
#2.结构体指针与结构体排序
结构体指针可简单了,就是指向结构体的指针嘛,其实结构体指针的确没什么特别的,不过有这么个东西要注意一下:我们访问结构体变量的成员变量的时候一般是用.,比如对于Student的变量就是s.score1。
假设我们面对的是一个结构体指针,那我们访问的时候就需要(*s).score1了,看起来还有点麻烦,所以我们有一个新的符号 “->”,没错就是一个减号加一个大于号组成的右箭头,我们可以直接s->score1来访问结构体指针对应的结构体中的成员变量,还挺形象的。
有了指针就有了动态内存分配,对于结构体的动态内存分配也是一样,非常简单:
Student* students = (Student*)malloc(n * sizeof(Student));
sizeof(Student)的大小有可能不是你想象的大小,我们之后再来讲讲这个问题,不过现在,你知道怎么用就好了。
那么有了结构体数组和结构体指针那可不就能用qsort了嘛!接下来的问题在于cmp函数怎么写,好写,看我的:
int cmp(const void* s1, const void* s2)
{
double delta = ((student*)s1)->score_avg - ((student*)s2)->score_avg;
if (fabs(delta) < 0.001) return 0;
else if (delta > 0) return -1;
else if (delta < 0) return 1;
}
这样,我们就可以把之前的按学生平均成绩排序改成这个样子了:
#include 
大功告成!我们的想法终于实现了!
(5). 会自动变长的数组
人总是贪婪的,我们之前利用VLA和动态内存分配实现了不在编译器确定大小的数组,不过假设有的时候连数据规模都不确定了,你可能就不能用VLA或者动态内存分配了——因为他们至少都要有一个n呀。
如果用过python,你可能知道:python的list和数组差不多,但是list是不限定大小的,我们平时用的python一般是cpython,也就是用C语言完成的python解释器,那它都能实现,我们是不是也能试试看实现一下呢?
当然,python的list太特殊了,我们换其他语言看看,在Java中,有内置的ArrayList可以自动变长,而在C++中,我们也有STL中的vector可以自动变长,所以,我们来试试手写一个vector吧!
请注意,如果你有想法了,就请自己先实现一下,这样对你的学习是非常有利的!假设你没什么想法,你可以看完我之后的内容,然后再自己模仿着实现一个自己的vector。
我们这次写一个int类型的vector,其他类型的也可以类似地实现。
#1.先确定一下我们要干什么
一个自动变长的数组应该有这样一系列特性:
- void init_empty(vector* v) : 初始化一个空的vector
- void init_value(vector* v, int* array, uint64 n) : 用一个数组去初始化vector,n为传入数组的大小
- void init_memory(vector* v, uint64 n) : 初始化一个容纳n个元素的vector
- void set(vector* v, uint64 index, int value) : 在已经开辟空间后,可以设置某个位置的数据为特定值
- int get(vector* v, uint64 index) : 与正常数组一样的按下表访问,返回值
- int* get_ptr(vector* v, uint64 index) : 获取数组中某个下标对应元素的指针,返回指针的值
- uint64 size(vector* v) : 获取数组的大小,返回大小
- int empty(vector* v) : 判断是否为空,返回1为是,0为否
- int push_back(vector* v, int value) : 无论是否超过了数组的容量,都在数组最后插入指定的数字,过程中可能涉及扩容等等问题,有一定挑战性,返回插入结果(1成功/0失败)
- void sort(vector* v, int ascending) : 将数组排序,ascending为1为升序,0为降序
- void clear(vector* v) : 释放掉整个数组的内存
每个函数中我们都要向其中传入vector指针,不然传入的只是vector的值,不能对其进行更改!接下来我们来做做看吧,要实现的东西真多啊,我们一步步来。
#2.先定义一下结构体
#include 这个结构体定义的还是很简单的,size是数组当前的容量(通过push_back设置后的值的数量),data就是C语言原生的数组(指针)
#3.初始化函数(构造函数)
这一部分我们要写
void init_empty(vector* v);
void init_value(vector* v, int* array, uint64 n);
void init_memory(vector* v, uint64 n);
首先是init_empty,这个很好写:
void init_empty(vector* v)
{
v->size = 0;
v->capacity = 0;
v->data = NULL;
}
把长度定义为0,数组为NULL
然后是init_value,这个有点麻烦,不过我们可以这么实现:
void init_value(vector* v, int* array, uint64 n)
{
// 利用memcpy完成数组数据拷贝更快
v->size = n;
v->capacity = n + 32;
v->data = (int*)malloc(v->capacity * sizeof(int));
if (v->data != NULL) {
memcpy(v->data, array, n * sizeof(int));
}
else {
printf("Initialize Failed!\n");
}
}
在这个函数中我们做了两件事情,首先是给data数组分配内存,然后再用memcpy函数完成原数组到data数据的拷贝,malloc函数在分配失败时会返回NULL即空指针,这时候我们就要多判断一步了。
然后是init_memory,这个实现起来也很简单:
void init_memory(vector v, uint64 n)
{
v.size = n;
v.capacity = n+32;
v.data = (int*)malloc(v.capacity * sizeof(int));
}
用C语言写这个构造函数需要起三个不同的名字,还是有点麻烦的呢,在C++中我们可以通过函数重载的方式实现不同参数的同名函数,同时在C++中我们还可以实现一些不一样的构造函数,像是移动构造函数。
#4.setter与getter函数
setter和getter是设置器和获取器的意思,这里我们要实现
void set(vector* v, uint64 index, int value);
int push_back(vector* v, int value);
int get(vector* v, uint64 index);
int* get_ptr(vector* v, uint64 index);
uint64 size(vector* v);
首先是set函数:
void set(vector* v, uint64 index, int value)
{
if (index < v->capacity) {
if (index >= v->size) {
v->size = index-1;
}
v->data[index] = value;
}
else {
printf("Set Failed! Index out of range!\n");
}
}
set函数首先要判断index是否超过了上限,如果超过了当然设置失败,如果小于上限的容量,就存入,这时,加入index在size之内,直接修改就行,如果在size之外,就要把size扩大了。
然后是push_back函数,这个函数是把某个数字push到vector的最后:
int push_back(vector* v, int value)
{
// 增长模式:满了就把容量+32
if (v->size == v->capacity) {
v->capacity += 32;
int* temp = v->data;
v->data = (int*)malloc(v->capacity * sizeof(int));
if (v->data != NULL) {
memcpy(v->data, temp, v->size * sizeof(int));
free(temp);
temp = NULL;
}
else {
printf("Push Back Failed\n");
return 0;
}
}
if (v->data != NULL) {
v->data[v->size] = value;
v->size++;
return 1;
}
else return 0;
}
这个函数相对要比较复杂,因为push_back函数是无论是否填满都会向后添加的,因此我们要考虑扩容的问题。
首先确定是否已经填满,如果填满了,就把最大容量增加32,通过malloc重新分配内存,然后再用memcpy复制原数组的数据(中间要记得判断malloc是否成功分配内存),之后再把数字加上去就好了,这样push_back就完成了。
接下来是get函数:
int get(vector* v, uint64 index)
{
if (index < v->size) {
return v->data[index];
}
else {
printf("Index out of range!\n");
return 0;
}
}
get函数只要确定index是否在size范围内就好了,然后返回数字即可。
接下来是get_ptr函数:
int* get_ptr(vector* v, uint64 index)
{
if (index < v->size) {
return &v->data[index];
}
else return NULL;
}
get_ptr函数与get差不多,返回index对应的地址。
size函数是返回容纳元素的个数:
uint64 size(vector* v)
{
return v->size;
}
然后setter和getter的函数就写完了,这一部分的函数是有一定难度的,大家应该先自己写一写尝试一下。 事实上,vector毕竟是一个存储数据用的容器,那么setter和getter函数应该是相当重要的,不过实际上真正的vector还有insert等等操作,如果学有余力,完全可以尝试一下。
#5.其它函数
接下来写完剩下的所有函数:
int empty(vector* v);
void sort(vector* v, int ascending);
void clear(vector* v);
empty函数相当简单:
int empty(vector* v)
{
if (v->size == 0) return 1;
else return 0;
}
之后来看看sort,我们会利用qsort函数完成sort,所以需要提前写好compare函数:
int cmp_1(const void* i1, const void* i2)
{
// 升序
return *(int*)i1 - *(int*)i2;
}
int cmp_2(const void* i1, const void* i2)
{
// 降序
return *(int*)i2 - *(int*)i1;
}
void sort(vector* v, int ascending)
{
if (ascending) {
qsort(v->data, v->size, sizeof(int), cmp_1);
}
else {
qsort(v->data, v->size, sizeof(int), cmp_2);
}
}
其实只要注意一下cmp函数的写法就行,难度也不大。
最后就是clear函数了:
void clear(vector* v)
{
free(v->data);
v->data = NULL;
v->capacity = 0;
v->size = 0;
}
这个函数也叫作析构函数,在vector的对象v生命期结束的时候因为我们手动分配了内存,所以需要释放掉,我们把释放内存的函数包装一下成为clear就好了。
#6.综合代码
#include 以上的代码就是整个vector的定义了,之后的main函数中有三段测试代码,我基本把所有的函数都测试了一下,应该可以保证没有出现什么明显错误,如果大家发现了什么bug,希望可以在评论区指出,谢谢啦。
如果你从头到尾写了一遍然后能正常运行并且实现所有的功能,那你太棒了,虽然造轮子听起来是一件没有那么必要的事情,但事实上,这也是能够帮助你学习到很多的过程。
我们学习计算机不应该那么功利,不是说别人做好的我拿来用就什么都不用管了,或许别人的代码中也有什么问题,你看出来了,可以进行适当的修改让它更好地运行。
#7.然后来看看C++和Java中的自动变长数组
先来看看C++
#include 这段代码需要C++11及以上标准才能正常编译

用起来可是相当自然啊,再来看看Java
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Random;
public class Main {
public static void main(String[] args) {
ArrayList<Integer> array = new ArrayList<Integer>();
Random r = new Random();
int n = 30;
for (int i = 0; i < n; i++) {
array.add(r.nextInt(1, 100));
}
for (int i : array) {
System.out.printf("%d ", i);
}
System.out.println();
array.sort(Comparator.naturalOrder());
for (int i : array) {
System.out.printf("%d ", i);
}
System.out.println();
}
}

用起来的确是要稍微麻烦一点,不过相比C语言还是要方便很多的。
(6). 来做个链表试试看
#1.什么是链表以及为什么是链表
我们前面做的vector有这么一个特性,一旦存储的容量超过了最大的容量就会自动申请一片新的连续内存。一般来说,我们这种小数据量的操作其实不会有什么太大的问题。
但是在代码中其实也有写,要判断v.data是不是NULL,有的时候malloc可能也会失败,即内存中分配不了那么大的一片连续区域。这就是堆内存容易产生的问题——堆内存中存在很多内存碎片,很有可能可用空间足够,但并不连续。所以假设我们要存储很多东西,连续空间不足了,我们能不能充分利用一下离散的空间呢?
#2.我们要做点什么呢?
链表就可以完成利用离散空间的过程,一个链表的结构如下:

链表是由一个个节点(Node) 组成的,我们用结构体来定义Node:
typedef struct _node {
int value;
struct _node* next;
} Node;
typedef Node* List;
这里要给struct一个名字的原因是:我们在结构体定义内部还要用到一次struct _node,因此如果直接写Node* next的话,就会在编译的时候报错。然后我们还要把节点指针(Node*)再命名为List。
链表的结构其实很简单,就是一个值和一个节点指针(Node *)next,这个next指向下一个节点,这样一来一个接一个,就可以把一串节点全都连接起来了,所以叫做“链表”,还是很形象的对吧,接下来我们要实现这个链表就得实现以下函数:
- void init(List list, int num) : 用一个值初始化链表
- void add_head(List* ListPtr, int num) : 在链表头部添加一个数字
- void add_tail(List list, int num) : 在链表尾部添加一个数字
- void insert(List list, int index, int num) : 在链表某个索引的位置插入一个值
- void print(List list) : 把整个链表打印出来
- Node* search(List list, int num) : 找到值为num的节点,返回其地址
- int remove_head(List* listPtr) : 删除链表中头部的元素,返回删除结果
- int remove_tail(List* listPtr) : 删除链表中尾部的元素,返回删除结果
- int remove_num(List* ListPtr, int num) : 删除链表中第一个值为num的元素,返回删除结果
- int remove_index(List* ListPtr, int index) : 删除链表中索引为index的元素,返回删除结果
- void all_free(List* listPtr) : 释放掉所有节点的内存
还是一样,到这里我希望你可以自己先去试着写一写,自己完成的能够收获更多东西。
#3.初始化和插入函数
这一部分我们完成:
void init(List list, int num);
void add_head(List* ListPtr, int num);
void add_tail(List list, int num);
void insert(List list, int index, int num);
首先是init:
void init(List list, int num)
{
list->value = num;
list->next = NULL;
}
初始化一下就好了,然后看add_head:
void add_head(List* ListPtr, int num)
{
Node* new = (Node*)malloc(sizeof(Node));
new->next = *ListPtr;
new->value = num;
*ListPtr = new;
}
我们每个节点都需要通过动态内存分配的方式分配一下。在头部插入一个元素的过程应该是这样:

将New Head节点的next指向原来的next,再把list赋值为New Head节点
add_tail的过程也是类似:
void add_tail(List list, int num)
{
Node* next = (Node*)malloc(sizeof(Node));
next->next = NULL;
next->value = num;
Node* temp = list;
while (temp->next) {
temp = temp->next;
}
temp->next = next;
}
不过add_tail这里要用到一个技巧:我们需要找到尾节点,那么就是判断某一个节点是不是next==NULL,这里就可以用一个while循环来完成(for循环也可以,之后来看)
那么insert函数其实就有点复杂了,首先它的过程应该是这样:
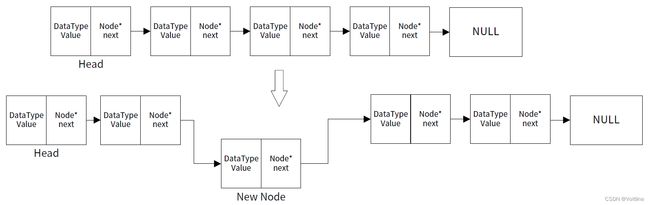
让对应位置的Node_index的next指向New Node,然后New Node的next指向变化之前的Node_index的next:
void insert(List list, int index, int num)
{
int cnt = 0, check = 0;
Node* NodePtr = list;
while (NodePtr) {
if (cnt != index) {
cnt++;
NodePtr = NodePtr->next;
}
else {
Node* temp = (Node*)malloc(sizeof(Node));
temp->value = num;
temp->next = NodePtr->next;
NodePtr->next = temp;
check = 1;
break;
}
}
if (!check) {
printf("Insert Failed! Index out of range!\n");
}
}
我们在这里还要判断一下索引index是否超出了范围,不能插入。
#4.删除函数
这一部分也是相对复杂的,我们要实现:
int remove_head(List* listPtr);
int remove_tail(List* listPtr);
int remove_num(List* ListPtr, int num);
int remove_index(List* ListPtr, int index);
在链表中删除一个节点的过程是这样的:

我们让被删除的节点Node_delete前的节点Node_before连接Node_delete的下一项Node_after,然后我们再把Node_delete给释放掉就可以了,不过这样的过程中还有一些小问题,比如怎么找到Node_delete的前一个节点呢?
所以让我们来看看代码吧!首先是remove_head,其实就是前面add_head的逆过程:
int remove_head(List* listPtr)
{
if ((*listPtr)->next != NULL) {
Node* temp = (*listPtr);
(*listPtr) = (*listPtr)->next;
free(temp);
return 1;
}
else {
printf("Remove Error! Head Node is the only Node!\n");
return 0;
}
}
这里的参数是一个List*,因为我们设计到对当前指针的改动,如果不传指针就会出现list本身没有发生变化,但是头元素的节点已经被释放的问题。
remove_tail函数也是类似:
int remove_tail(List* listPtr)
{
Node* NodePtr = *listPtr;
if (NodePtr->next != NULL) {
while (NodePtr->next->next) {
NodePtr = NodePtr->next;
}
free(NodePtr->next);
NodePtr->next = NULL;
return 1;
}
else {
printf("Delete Failed!\n");
return 0;
}
}
接下来看看按照数字删除的remove_num:
int remove_num(List* ListPtr, int num)
{
int check = 0;
for (Node* it = *ListPtr; it->next != NULL; it = it->next) {
if (it->next->value == num) {
Node* temp = it->next->next;
free(it->next);
it->next = temp;
check = 1;
break;
}
}
if (!check) {
printf("Delete Failed!\n");
return 0;
}
return 1;
}
这里我们用了for循环完成链表的遍历,for中的三个表达式一个是让it为list的头节点,第二个是终止条件——如果it的next为空指针,第三个是类似i++的操作,让it变为it的下一项。
remove_index函数就要更复杂一些了:
int remove_index(List* ListPtr, int index)
{
int cnt = 0, check = 0;
if (index != 0) {
for (Node* it = *ListPtr; it != NULL; it = it->next) {
if (cnt + 1 == index) {
Node* temp = it->next->next;
free(it->next);
it->next = temp;
check = 1;
break;
}
cnt++;
}
}
else {
check = remove_head(ListPtr);
}
if (!check) {
printf("Delete Failed!\n");
return 0;
}
return 1;
}
在这里我们取了个巧,如果index是0那就正好是删除头节点,直接调用remove_head函数完成。然后之后就要解决我们之前说的要找到Node_delete节点的上一个节点的问题,在这里我采用cnt+1 == index进行判断,这样这样我们直接就可以定位到Node_delete的前一个节点,之后再做我们需要的操作就好了。
这一部分的代码复杂程度比较大,你需要比较熟悉链表的正常操作方式,这样才能更好地理解我到底是在干什么。
#5.查找、打印和析构
这部分我们实现一下剩余的几个函数:
Node* search(List list, int num);
void print(List list);
void all_free(List* listPtr);
首先是search函数:
Node* search(List list, int num)
{
for (Node* it = list; it != NULL; it = it->next) {
if (it->value == num) {
return it;
}
}
printf("Search Failed! Not Found!\n");
return NULL;
}
其实这个函数的难度就不大了,本质上跟add函数和remove函数中的查找类似,当然我也是写完了才想起来好像可以调用search函数完成add和remove哈哈哈哈。
然后我们看看print:
void print(List list)
{
for (Node* it = list; it != NULL; it = it->next) {
printf("%d ", it->value);
}
printf("\n");
}
轻轻松松,看看all_free:
void all_free(List* listPtr)
{
Node* p = *listPtr;
Node* q = (*listPtr)->next;
while (q->next) {
free(p);
p = q;
q = p->next;
}
free(q);
}
这个代码我稍微解释一下,p和q是一前一后两个节点,我们要做的就是让p先释放,然后p再指向q,再让q指向q的下一个,然后就这样一个个释放掉。本质就是用一个q保证能够连续向后完成释放的过程。
到这里,一个链表的实现就基本上完成了!
#6.综合代码
#include 其实我当时想着链表的代码量应该不会比vector还多,结果实现完之后代码有180来行。可能是有点难度吧,大家理解起来应该会有一些障碍,不过多敲敲代码,看看我之前提供的几张图,自己心里好好思考一下链表的各种过程究竟应该怎么样完成。 这两个小节的代码我都只提供了很少的说明,目的就是希望你能自己完成在这些代码的编写,写完了之后,我不用多说什么你自然就理解了。
(7). 结构体和内存占用
#1.先来看看几个内存占用
我们在一个结构体中可以声明好几个成员变量,因此他们也是需要一片内存来存储的,假设我们有一个这样的结构体:
typedef struct {
int a;
int b;
int c;
} s1;
我们来看看s1的内存占用:
#include ![]()
这看起来还挺正常,三个int都是4字节,加起来就是12字节,我们改改这个s1,把c变为unsigned long long,再看看内存大小:
#include ![]()
这个看起来也正常,4+4+8=16,那假设我们把c和b换个位置呢?按理说也应该是16对吧?
#include 
诶诶诶?怎么换个顺序就从16变成24了?24算起来应该是8+8+8=24吧大概。我们来解释解释这个事情。
#2.怎么还会有不同?
事实上,结构体的内存占用不是简单的把其中所有变量的内存相加,它遵循一个内存对齐的原则。
内存对齐的基本规则如下:
- 1.第一个成员在结构体变量偏移量为0的地址处,如结构体s1位于0x0010ff12,则第一个成员从地址0x0010ff12开始
- 2.从第二个成员开始,在自身对齐数的整数倍开始存储,对齐数=min{编译器的默认对齐数, 成员变量的字节数}
- 3.结构体变量所用的总内存数是最大对齐数的整数倍
- 4.遇到嵌套结构体时,嵌套结构体先依照上述规则对齐,再将嵌套结构体作为一般的变量,依照上述规则对齐。
在了解了规则之后,我们再来看看前面的三个例子(以下假设结构体都存在地址0的位置):
(1).结构体s1:
typedef struct {
int a;
int b;
int c;
} s1;
开始,a从0开始存储,b的对齐数为4,因为a占用了0,1,2,3四个位置,b正好从4开始存储,之后c也是类似,这样就占用了0~11共12个地址,整个结构体的最大对齐数是4,能容纳12的4的最小整数倍正好是12,因此s1占用的空间就是12。
(2).结构体s2:
typedef struct {
int a;
int b;
unsigned long long c;
} s2;
开始,a从0开始存储,b的对齐数为4,因为a占用了0,1,2,3四个位置,b正好从4开始存储,之后c是8字节,c的对齐数为8,c正好也从8开始存储,这样就占用了0~15共16个地址,整个结构体的最大对齐数是8,能容纳16的8的最小整数倍正好是16,因此s2占用的空间就是16。
(3).结构体s3:
typedef struct {
int a;
unsigned long long c;
int b;
} s3;
开始,a从0开始存储,b的对齐数为4,因为a占用了0,1,2,3四个位置。c的对齐数是8,这时要从8的最小整数倍8开始存储,因此c从8开始存储,从8起占用8个地址到15
之后b就从16开始存储,占用4个字节到19,这样就占用了0~19共20个地址,整个结构体的最大对齐数是8,能容纳20的8的最小整数倍为24,因此s3占用的空间就是24。
这样一来你就能明白为什么同样的成员内存大小也不一样了吧?因为内存对齐规则的存在,我们的结构体有可能会浪费一部分空间,就如上述的结构体s3一样,因此之后设计结构体的成员时尽可能这么做:将占用小的变量放在前面,占用相同的变量放在一起,比如有三个int, 两个char和四个double的结构体,我们最好这么写:
struct s {
char c1, c2;
int i1, i2, i3;
double d1, d2, d3, d4;
};
那么这个结构体的内存占用是多少呢?你可以思考一下。
(8). 联合(union)
联合(union)是另一种把数据打包的方式,一个联合也可以存储好几个成员变量。
但是联合的内存不是像结构体一样互不干扰,而是所有变量共享同一片内存空间,一个联合占用的字节数是联合中所有成员占用字节数的最大值,比如一个int,一个double,一个char,那么这个联合的size应该是8,即sizeof(double)。
在同一时间内,只有一个成员拥有对这片内存的读写权。我们来看看下面的代码:
#include 
三次赋值之后得到的都是不同的值,你也可以自己尝试一下。
小结
这一章的内容代码量非常大,无论是链表还是vector,这一章的内容我希望你都能自己尝试实现一下,这样对于你现在学习结构体,乃至未来你学习例如Java,Python或者C++之类支持面向对象的编程范式的语言的时候,都能够有比较深刻的理解,同时也能够有一个比较清晰的程序设计思路。
这一章中的所有代码我都已经测试过了,基本运行应该不会出错,但是难以保证在所有情况下都可以正常运行,所以如果你自己输入的样例会报错或只是不能正常运行的话,麻烦在评论区中指出,我也一定会尽快修复,感谢你的支持!
在我们学习完了结构体之后,关于文件指针的内容我们也就很方便解释了,因此下一章我们来讲讲把数据永久存储——文件篇。