NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
目录
1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264)
2.工作过程
2.1输入
2.2过程
3.实际效果
书接上回,在 NCDC气象数据的提取与处理(一)中,
我们得到了研究区内,且观测时间满足一定要求的站点列表,形式如下:
接下来,我们要根据这个站点列表,从全国的站点数据中筛选指定站点,并将isd-lite格式的数据转化为其他形式(本教程以转化为 .xlsx 为例)
闲言少叙,先放代码,再将工作过程:
1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264)
import os
import pandas as pd
import numpy as np
"""
工作原理:
输入/指定:工作路径,指定年份(时间范围),输入站点列表
过程:指定工作路径下的文件夹全部以“china_isd_lite_”+“年份”命名,
根据输入的时间范围,创建对应年份的文件夹列表,
根据输入的站点列表,创建文件名称列表,
在每个文件夹列表元素下,顺序读取文件名称列表对应文件,并完成数据写入
"""
def trans_isd2excel(station_list,work_dir= r"D:\A_NCDC_test",period= [1980,1981]): # 工作路径,指定年份(时间范围),站点列表
datadir_list = []
for i in os.listdir(work_dir):
if os.path.splitext(i)[-1]=="" and period[0]<=int(os.path.split(i)[-1][-4:])<=period[1]: # 判断是否是文件夹,并指定时间范围
datadir_list.append(work_dir + os.sep + i) # 年份文件夹 路径,如:'D:\\A_NCDC_test\\china_isd_lite_1980'
erro_list = []
for datadir in datadir_list:
dataname_list = []
for item in station_list: # 文件名称形式:"D:\\A_NCDC_test\\china_isd_lite_1980\\450070-99999-1980"
dataname_list.append(datadir + os.sep + item + "-99999-" +os.path.split(datadir)[-1][-4:] )
for name in dataname_list:
try:
data = pd.read_table(name,header=None)
'''
原始数据中以空格分隔的12列数据,分别为:
年、月、日、小时、温度、露点温度、气压、风向、风速、云量、1小时降雨量和6小时降雨量。
'''
# 构建空列表用于存放提取出来的各列数据
data_list = []
for line in data.values:
line_temp = [int(x) for x in line[0].split(' ') if x != '']
data_list.append(line_temp)
df = pd.DataFrame(data_list,columns=['年','月','日','小时','温度','露点温度','气压','风向','风速','云量','1小时雨量','6小时雨量'])
# 对数据中-9999的缺失值进行NaN替换
df = df.replace(-9999,np.nan)
# 数据说明文档中表示原始数据中温度、露点温度、气压、风速、降雨量的换算系数为10,所以要对原始数据中的对应数据除以10,进行换算。
df['温度'] = df['温度']/10
df['露点温度'] = df['露点温度']/10
df['气压'] = df['气压']/10
df['风速'] = df['风速']/10
df['1小时雨量'] = df['1小时雨量']/10
df['6小时雨量'] = df['6小时雨量']/10
# 为了便于后续重采样分析数据,给数据增加一个DataFrame列
df['Date'] = pd.PeriodIndex(year=df['年'],month=df['月'],day=df['日'],hour=df['小时'],freq='H')
df = df.set_index(df['Date'])
df.drop(columns= 'Date',inplace=True)
# 保存为同名excel
out_folder = f'{work_dir}_trans_isd2excel\\{os.path.split(name)[-1][-4:]}' # 输出到工作文件夹同级的 "工作文件夹名称 + _trans_isd_2excel"下
if not os.path.exists(out_folder):
os.makedirs(out_folder) # 如果文件夹不存在,就创建
df.to_excel(f'{out_folder}\\{os.path.split(name)[-1]}.xlsx')
except FileNotFoundError:
print("Error: 没有找到文件或读取文件失败",name)
erro_list.append(name)
else:
print("/"*10,"成功!",name)
return erro_list # 返回一个列表(储存未找到的文件名称)2.工作过程
上述代码定义了一个名为“trans_isd2excel”的函数
要求输入:station_list,站点列表,[455001,455002,…]
work_dir, 工作文件夹路径
period, 处理时间范围,[起始年份,结束年份]
2.1输入
~工作文件夹路径,就是包含各年份文件夹的上级文件夹路径

本例中 ,包含年份文件夹的 "D:\A_NCDC_test"就是工作文件夹work_dir;
~处理时间范围,这个也好理解,我工作文件夹下有1980-2022,但我只想要1980-2018,那么就设置period=[1980,2018];
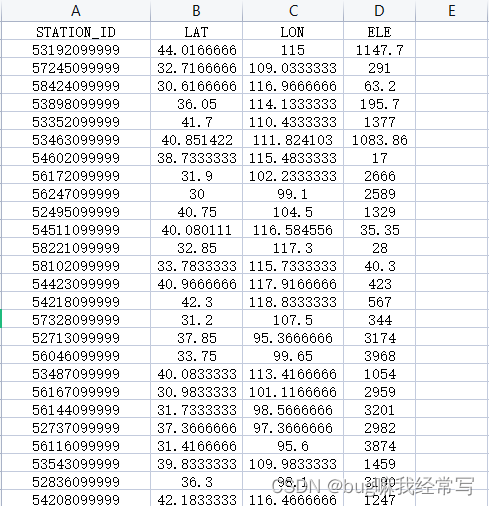
~需要说明的是,站点列表station_list在上一篇文章里没有处理到位,这里要多做一步;

红框中只有前6位是站编号,后面一串9需要去除,代码中的
stations = pd.read_excel('../Desktop/station_ID.xlsx')
station_list = [str(x)[:6] for x in stations["STATION_ID"]] # 有效站点列表就是负责做这个的
2.2过程
step1. 根据输入的时间范围,创建对应的年份文件夹列表
datadir_list = ['D:\\A_NCDC_test\\china_isd_lite_1980',…]
step2.根据输入的站点列表,创建文件名称列表,
dataname_list = ["D:\\A_NCDC_test\\china_isd_lite_1980\\450070-99999-1980",…]step3.顺序读取文件名称列表对应文件,完成数据折算及写入
对于step1中每一个年份文件夹,都执行step2和step3,转换后的文件最终输出到工作文件夹同级的 "工作文件夹名称 + _trans_isd_2excel"下,如本例中,工作文件夹为D:\\A_NCDC_test,输出文件夹就为D:\\A_NCDC_testtrans_isd_2excel。
3.实际效果
调用函数
trans_isd2excel(station_list,work_dir= r"D:\A_NCDC_test",period= [1980,1981])
输出文件位置,