Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 3——逻辑回归、过拟合与正则化
此系列为 Coursera 网站机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
参考资料:http://blog.csdn.net/scut_arucee/article/details/49889405
一、Classification and Representation
1.1 分类问题(classification)
在第一讲中我们提到监督学习分为两类:回归问题和分类问题,之前描述的房价问题就属于回归问题,因为要预测的变量是连续的,接下来我们会介绍另一种——分类问题(classification)。分类问题中要预测的变量是离散的。
现在有一些肿瘤大小和相应性质( 0 代表良性,1代表恶性)的训练数据,如下图红色叉点。若仍以线性回归进行学习,则可以学习出如下黄色的假设函数 hθ(x) ,对于新的输入 x ,可按下列阈值分类器预测y:

如果在图中加上一点(如上图绿色叉点),仍符合上述分类器的判定,但是按线性回归,最后的分类器如图中绿色直线所示,说明线性回归不适于用以解决分类问题。我们可以选择逻辑回归(logistic regression)来解决分类问题。
1.2 逻辑回归的假设函数 hθ(x) 的定义
对于两类分类问题, y=0,or,1 ,但之前线性回归中 hθ(x)=θTx 的定义可能使 hθ(x) 大于 1 或者小于0。
逻辑回归中, 0⩽hθ(x)⩽1 ,要使得 hθ(x) 满足上述要求,定义:
其中, g(z)=11+e−z ,被称为 logistic function(sigmoid function)。设 z=θTx ,逻辑回归的假设函数表达式为:
因为logistic function的图像在 −∞ 渐进于 0 而在 +∞ 渐进于 1 ,如下图,故其刚好满足了逻辑回归对hθ(x)的取值范围要求。

-
下面我们就来解释一下 hθ(x) 的含义。
“probability that y=1,given x,parameterized by θ ”
对于二类分类问题, y 只有两个输出0和 1 ,hθ(x)给出了输出 y=1 的概率。
用数学表达式表示:
1.3 决策边界(Decision Boundary)
当得到一个新的x,我们如何通过上面的假设函数 hθ(x) 预测输出 y ?
根据hθ(x)的含义,我们可以做出如下假设:
根据上面logistic函数的图像我们可以看出,当 g(z)≥0.5 , z≥0 ,而 z=θTx ,我们可以得到:
下面我们举一个例子来更好地理解决策边界:
我们现在有如下图所示的数据集,假设函数模型为: hθ(x)=g(θ0+θ1x1+θ2x2) (这里怎么确定参数,我们会在之后的小节再讲)。
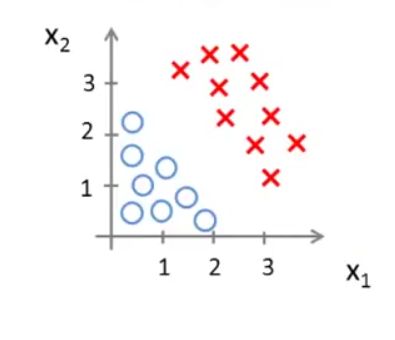
假设我们已经得到:
根据前面所讲的,我们可以得到:
我们在图中画出 −x1+x2=3 这条直线,如下图黄线所示
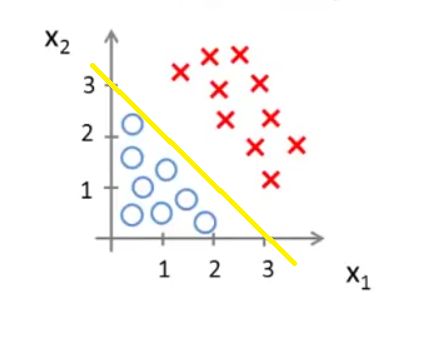
我们可以直观地看出,当 (x1,x2) 在这条直线的上方,则预测 y=1 ;当 (x1,x2) 在这条直线的下方,则预测 y=0 。 −x1+x2=3 这条直线就是这里的决策边界(Decision Boundary)。它将空间分为两个区域,预测 y=0 和预测 y=1 。这条直线并不是数据集本身的属性,而是假设函数(hypothesis)和其参数 θ 的属性。
值得注意的是,logistic 函数 g(z) 的输入(e.g. θTx )并不总是线性的:
上面的决策边界 −x1+x2=3 属于线性决策边界,再看一个非线性决策边界的例子。假设训练数据的分布如下图所示,则可用高阶多项式进行拟合。

如假设 hθ(x)=g(θTx)=g(θ0+θ1x1+θ2x2)+θ3x21+θ4x22 ,并且通过拟合,我们得到:
此时的决策边界为一个圆心在原点,半径为1的圆,当 (x1,x2) 位于圆外部,我们可以预测 y=1 ;当 (x1,x2) 位于圆内部,我们可以预测 y=0 。
二、逻辑回归(Logistic Regression)
2.1 逻辑回归的代价函数
前面提到决策边界由假设函数和参数 θ 决定,那么我们如何求解参数 θ ?在线性回归中,我们利用代价函数(cost function)来求 θ ,在逻辑回归中仍然适用。
我们仍然采用之前的符号定义:

线性回归中,代价函数表达式为:
-
下面我们讨论逻辑回归,定义单个样本的代价:
为了简化表达,可略去上标,即:
-
如果仍然像线性回归那样定义逻辑回归的代价函数 J(θ) ,则由于 hθ(x)=11+e−θTx ,导致 J(θ) 变成非凸函数,如下图,这就可能有很多局部最小值,用梯度下降法很难保证其收敛到全局最小值。

因此,在逻辑回归中,需要另寻一个代价函数,使其是凸函数(单弓形),如下图,这样就可以使用梯度下降法找到全局最小值。
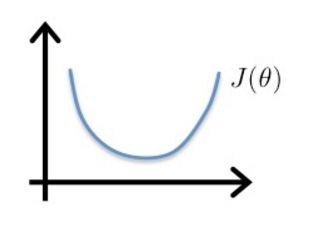
我们选择如下的代价函数来表示单个样本的代价:

这个函数看起来很复杂。下面我们通过画出它的图像来解释选择它的原因。
1、当y=1, Cost(hθ(x),y) 关于 hθ(x) 的图像:
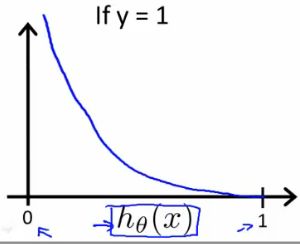
注意横坐标为 hθ(x) ,而 hθ(x) 的取值范围为 (0,−1) ,所以图像只取 (0,−1) 段。
我们可以看出,当 hθ(x)=1 ,则假设函数预测结果与事实一致, Cost=0 ;当 hθ(x)=0 ,则预测结果与事实不符, Cost=∞ ,说明要通过一个很大的代价 Cost→∞ 来惩罚学习算法。2、当y=1, Cost(hθ(x),y) 关于 hθ(x) 的图像:
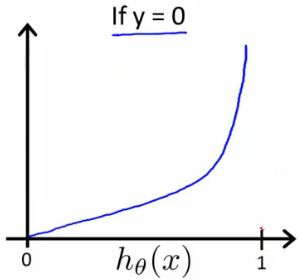
横坐标为 hθ(x) ,而 hθ(x) 的取值范围为 (0,−1) ,所以图像只取 (0,−1) 段。
同理,若 y=0 ,而 hθ(x)=1 ,将通过一个很大的代价 Cost→∞ 来惩罚学习算法。
以上说明在求解参数 θ 时,当选择合适的代价函数(代价函数转化为一个凸函数),我们就可以将问题转化为凸优化问题(convex optimization problem),方便我们求解全局最小值。
简化代价函数
为了方便书写和接下来的梯度下降,我们将上面代价函数的两个式子压缩为一个:
由单个样本的代价函数,最终我们得到逻辑回归总的代价函数:
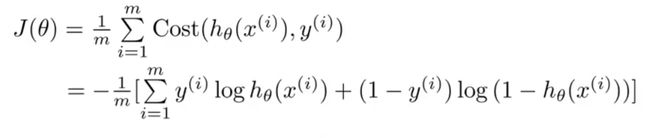
2.2 用梯度下降求解参数 θ
与线性回归相同,我们的目标是找到使代价函数 J(θ) 最小的参数 θ 。
回忆我们之前的梯度下降共公式:

将 ∂∂θjJ(θ) 代入,得到:
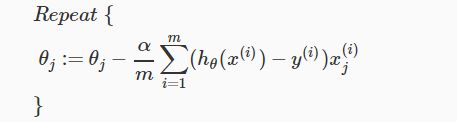
注意这里也要同时更新所有的 θ 值。
我们回忆之前所讲的线性回归中梯度下降的更新公式,你会发现,线性回归和逻辑回归的梯度下降更新公式是一样的。(视频中并未说明为什么,但是推导出的结果确实如此,推导过程可见这里)
但我们需要注意,两个公式中 hθ(x) 是不同的,线性回归中, hθ(x)=θTx ,而逻辑回归中, hθ(x)=11+e−θTx ,所以两者的梯度下降还是不同的。
梯度下降更新公式用向量表示(代码实现时常用到):
我们之前所讲的梯度下降常见两个问题的解决方法以及特征缩放对于逻辑回归也是适用的,在此不再赘述。
2.3 高级优化
在编写代码时,我们需要写代码表示 J(θ) , ∂∂θjJ(θ) ,但一般情况下我们只需要编写代码表示 ∂∂θjJ(θ) 将其代入更新公式就可以了,但如果你想要通过画 J(θ) 曲线图判断梯度下降是否正常工作或收敛,也可以编写 J(θ) 的代码。
逻辑回归找出最优的算法除了梯度下降外,还有其他一些高级优化算法例如共轭梯度,变尺度法(BFGS),限制变尺度法(L-BFGS)等,这些高级优化算法不需人为选择学习率 α ,拥有比梯度下降更快的速度,但同时也更加复杂。
三、多分类问题:One vs all
这一部分我们主要讲一下如何用逻辑回归解决多类别分类问题。这里,我们采用一种“一对多”(one vs all)的分类算法。
举例,一个二类分类问题的数据集分布如下图左所示,一个多类分类问题的数据集分布如下图右所示(用不同的符号表示不同的类别):
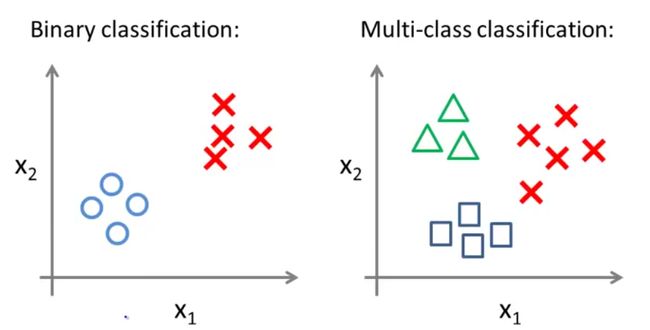
在之前所讲的二类分类问题中,我们可以使用逻辑回归用直线将数据集一分为二为正类和负类。那么我们如何用一对多(one vs all)的分类思想解决多分类问题?
用上图右数据集举例说明。图中数据一共有三类,我们可以将其转化为三个二分类问题。在每一个两类分类问题中,把待识别的类别当作正类别,其余合为一类作为负类别。如下图:

每一个类别拥有一个假设函数,故这里一共有3个假设函数:
相当于给每个类别单独训练一个逻辑回归分类器,用 h(i)θ(x) 去预测 y=i 的概率。给出一个新的 x ,我们取使h(i)θ(x)最大的 i 作为它的输出类别。
总结:
One vs all:
Train a logistic regression classifier h(i)θ(x) for each class to predict the probability that  y=i .
To make a prediction on a new x , pick the class that maximizes h(i)θ(x): maxi(h(i)θ(x))
四、过拟合(Overfitting)和正则化(Regularization)
前面我们已经讲了线性回归和逻辑回归,它们能够有效地解决许多问题,但当将它们应用于某些特定的机器学习应用时,我们会遇到过拟合问题(overfitting),会导致结果特别差。这一小节内容会为大家解释什么过拟合问题,并且介绍一种可以改善或减少过度拟合问题的技术——正则化技术( regularization),。
4.1 过拟合(overfitting)
在利用训练数据拟合假设函数时,可能会有如下图三种情况:
① 欠拟合(underfitting)
欠拟合(underfitting)也称为高偏差(high bias)。即,拟合出的假设函数在训练数据集上不能很好地拟合数据, h(i)θ(x) 和 y 的偏差比较大,如下图(左为线性回归欠拟合,右为逻辑回归欠拟合)
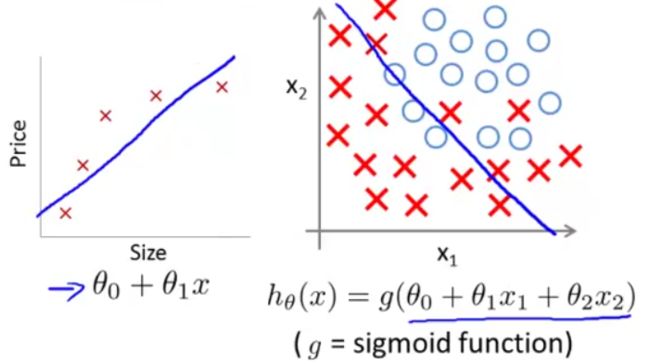
② 适度拟合(just right)
即,拟合出的假设函数在训练数据集上能较好的反映输出和输入的关系,hθ(x)和y的偏差不大,如下图(左为线性回归适度拟合,右为逻辑回归适度拟合)
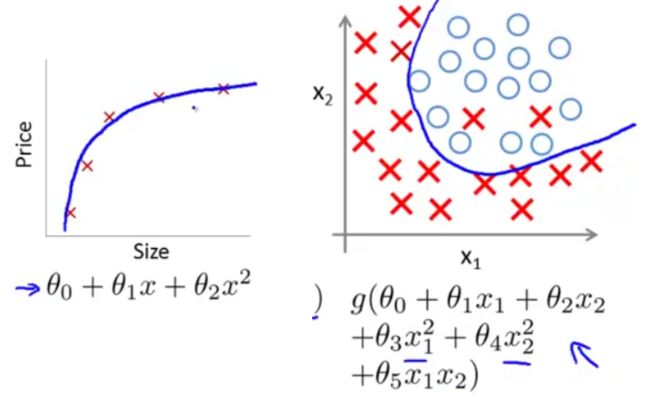
③ 过拟合(overfitting)
过拟合(overfitting)也称为高方差(high variance)。即,由于特征变量太多,导致学习到的假设函数太过适合于训练数据集,甚至J(θ)≈0,导致无法泛化(generalize)到新的数据样本,如下图(左为线性回归过拟合,右为逻辑回归过拟合)。
泛化能力:指一个假设模型能够应用于新样本(没有出现在训练集)的能力。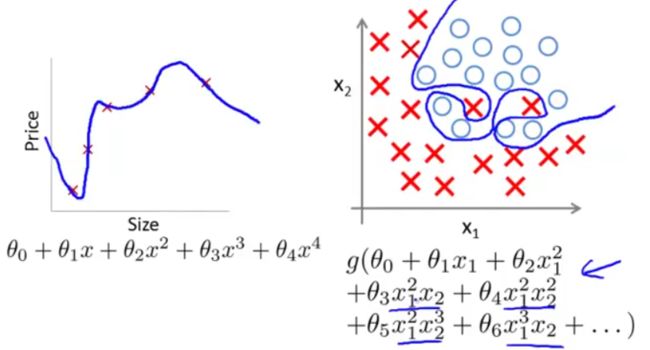
这(过拟合)对于训练数据集来说当然是好的,但我们的最终目的不是让假设函数完美适配训练数据,而是让它去预测新的问题。过拟合带来的问题是假设函数很精准地适配了训练数据,但是却无法泛化到新的例子,对新的输入无法很好地预测其输出。
当我们遇到过拟合(overfitting)问题时,我们应该如何解决呢?
前面通过绘制假设函数曲线我们可以选择合适的多项式阶次,但当特征变量变得很多时,画图本身就变得很难。这里给出两种规避过拟合的方法:★ 减少特征变量的数量
我们可以人工选择保留或舍弃哪些变量,也可以通过模型选择算法(model selection algorithm)自动选择采用哪种特征变量。
★正则化(regularization)
即,保留所有特征变量,但要减小 θj 的数量级或值。
4.2 正则化(Regularization)
在前面过拟合的图示中假设函数 hθ(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4 ,这时会出现过拟合现象;如果我们想要消减 θ3x3 和 θ4x4 两项的影响,来避免过拟合,同时,我们不希望删去这两个特征变量或者说不改变假设函数的形式,那么我们可以在代价函数后添加惩罚项如下:
J(θ)=12m∑mi=1(hθ(x(i))−y(i))2+1000θ23+1000θ24-
则在 minθJ(θ) 的任务中, θ3 , θ4 将会非常小( →0 ) ,相当于没有后面两项,这样假设函数就近似于一个二次函数,就可以恰当的拟合数据集。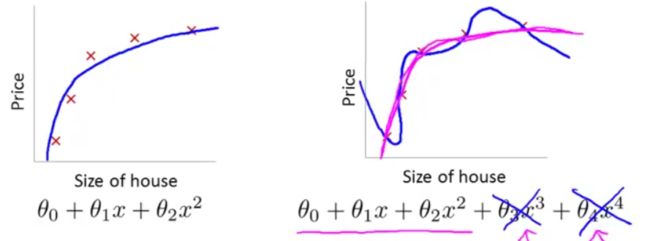
当有很多特征时,我们并不知道哪些项是关联度较小的项,无法像上面挑出 θ3 , θ4 那样提前挑出对应的 θ 参数以缩小它们。我们可以惩罚所有的参数,
J(θ)=12m[∑mi=1(hθ(x(i))−y(i))2+λ∑nj=1θ2j]-
注意 j 从1开始,不惩罚 θ0 , θ0 仍然可能是较大的。(在实践中即使加入 θ0 项,结果也只有非常小的差异)λ∑nj=1θ2j 项称为正则化项, λ 称为正则化参数,它控制着正则化两个目标之间的平衡。
正则化的两个目标:
① 更好的拟合训练数据,使假设函数很好的适应训练集
② 保持 θ 参数值较小,避免过拟合正则化参数 λ 的影响:
① λ 如果太小,则相当于正则化项没起到作用,无法控制过拟合;
② λ 如果太大,则除了 θ0 ,其余的参数都会约等于 0 ,相当于去掉了那些项,使hθ(x)=θ0,毫无疑问这会得不偿失地导致欠拟合。
(在之后的课程中我们会讲一些自动选择 λ 参数的算法。)
4.3 正则化在线性回归中的应用
对于线性回归的求解,我们之前推导了两种学习算法:一种基于梯度下降;一种基于正规方程。
带有正则化的梯度下降
为了惩罚除了 θ0 以外的所有参数,我们将梯度下降的公式修改为如下形式:
除 θ0 外, θj 的表达式中,中括号中的部分为对带有正则化项的代价函数 J(θ) 求偏导的结果。这个式子还可以写成下面的形式:
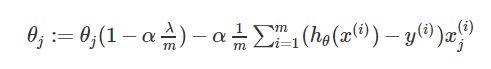
其中 (1−αλm)<1 ,当 α 很小,m很大时,相当于把 θj 向 0 压缩了一点点;后面一项 α1m∑mi=1(hθ(x(i))−y(i))x(i)j 与无正则化的线性回归梯度下降表达式中相应的项一致。这相当于我们只是将 θj 变小了一点点,然后执行和以前一样的更新。
带有正则化的正规方程
我们将输入输出用矩阵和向量表示出来:X=⎡⎣⎢⎢⎢⎢⎢(x(1))T(x(2))T⋮(x(m))T⎤⎦⎥⎥⎥⎥⎥∈Rm×(n+1),y=⎡⎣⎢⎢⎢⎢y1y2⋮ym⎤⎦⎥⎥⎥⎥∈Rm原正规方程给出的求解 minθJ(θ) 的式子为:
θ=(XTX)−1XTy如果加入正则化,则公式变为:
θ=(XTX+λ⋅L)−1XTy其中,
L=⎡⎣⎢⎢⎢⎢⎢00⋮001⋮0⋯⋯⋱⋯00⋮1⎤⎦⎥⎥⎥⎥⎥L 是一个对角线为0,1,1,1,⋯,1,其余全为 0 的(n+1)×(n+1)维矩阵。事实上,带有正则化的正规方程加上 (λ⋅L) 后,还可解决之前 XTX 不可逆的问题。
利用正则化,即使是在较小的数据集里有很多特征,也可以更好地进行线性回归。
4.4 正则化在逻辑回归中的应用
回忆我们之前讲的逻辑回归的代价函数:
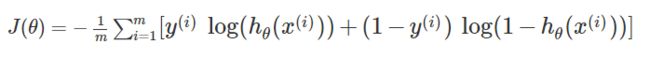
我们可以通过在后面添加如下一项来进行正则化:

带有正则化的梯度下降:

注意,虽然这里,逻辑回归的正则化后梯度下降公式与线性回归相同,但由于假设函数不同,两者并不是一样的。
附:课后测试题答案
1、答案:C

2、答案:B
