万字长文盘点时序融合在BEV感知中的应用(下)
本文承接上篇,如未阅读请先移步:
万字长文盘点时序融合在BEV感知中的应用(上)_苹果姐的博客-CSDN博客
四.基于transformer的图像特征融合
7.Uniformer[13](浙江大学,大疆,上海AI lab)
前文所介绍的6个模型有一个共同点,即都是在bev空间下对bev feature做时序融合.由于每一帧的bev feature只有一个,所以bev空间下的时序融合比较简单直接,可直接通过warp的方式将前序帧与当前帧融合,而且需要的缓存空间也比较小.但这种方法也有不足之处,一是会带来可融合区域的浪费,丢失有用信息,二是在融合过程中只能使用固定权重,无法自适应地调整前序帧权重,三是可用的时序区间也比较短,因为时序过长,可融合区域会更小,难以起到加强作用.BEVFormer的实验中,融合3帧,也就是2s的时序区间效果达到了峰值.
[13] UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird's-Eye-View
code:GitHub - cfzd/UniFormer (waiting)

Uniformer解释了基于warp的融合方式为什么会带来信息丢失.如下图所示,图(b)的灰色部分是连续两帧实际可融合区域,图(a)的灰色部分是生成一定范围内的矩形的bev feature后实际融合的区域,可见融合范围大大缩小,所以很多有用的信息被浪费了.
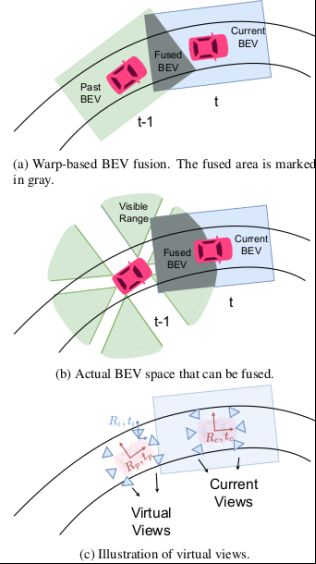
所以本文提出,为了更好地融合时序信息,可以不在bev空间通过warp的方式进行融合,而是把这一过程提前到图像空间,通过缓存前序帧的图像特征,并把前序帧的lidar2img参数,也就是相机外参转换到当前帧,那就等同于当前帧又多了很多个相机视角,同时可以看到更大范围的信息,图上图(c)所示.在这种架构下,多帧时间的融合和多视角空间的融合被统一起来了,所以模型命名为Uniformer.下图更加直观地展示了两种方法的区别:

Uniformer架构可以解决上述warp方法的全部缺陷.第一点,它不造成信息浪费,可以融合当前帧和前序帧相机视角所能覆盖的所有区域,第二点,它可以自适应地学习每个视角的权重,不区分当前和前序帧,第三,只要缓存空间允许,它可以融合很长的时序区间.当然这种方法的劣势是需要缓存多视角特征,无法使用较大的分辨率,一般需要高倍下采样,最后再进行上采样.Uniformer为这种方法取名为"virtual views"即虚拟视角方法.
在具体实现上,Uniformer的前序帧选取前6帧,时序对齐的方式如上文所述,通过外参转换的方式将前序帧变为当前帧的虚拟视角,然后做基于transformer的融合,包括self attention和cross attention,只是cross attention同时融合了时间和空间信息.最后还设计了self-regression自回归模块来融合多层transformer结果,最后得到bev feature,并指出这种方法也能达到类似于BEVFormer将前序帧和当前帧bev feature进行concate再融合的提升效果.bev feature分辨率采用50*50再用4倍上采样.实验效果对比如下图所示:

nuscenes val set
8.PETRv2[14](旷视科技)
[14] PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
code: GitHub - megvii-research/PETR: [ECCV2022] PETR: Position Embedding Transformation for Multi-View 3D Object Detection

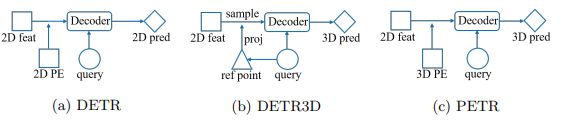
其实最先使用类似于虚拟视角的并不是Uniformer,而是PETRv2,只是PETRv2没有重点对时序融合进行分析.PETRv2是在PETR[15]的基础上加入时序融合的提升版.PETR又是对DETR3D的改进,简化了DETR3D的pipeline,把其中cross attention的多视角投影过程用事先计算好的3D positional encoding取代,与query相加后也可以为2D点提供3D信息,因为只要外参不变,每次投影过程其实是相同的,没必要每个iteration都重复计算,大大提高了效率.如下图所示:
[15] PETR: Position Embedding Transformation for Multi-View 3D Object Detection
PETRv2的时序融合方法与上文的Uniformer相似,都是通过变换前序帧外参的方式,将前序帧的相机视角变成当前帧的虚拟视角,只是它只用了1帧前序帧,是从前3-27帧(包含key frame和sweep)中随机选取的,与前文的Polarformer一致.融合分辨率与DETR3D一致,都是900个object query.以下是效果对比:
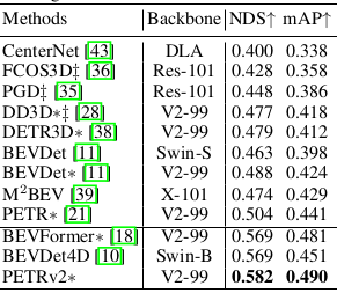
nuscenes test set
五.基于CNN(3D conv)的图像特征融合
9.Uniformer[16](深圳计算机视觉与模式识别实验室,商汤)
[16] UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
code: GitHub - Sense-X/UniFormer: [ICLR2022] official implementation of UniFormer

这篇Uniformer与前文[13]同名,但完全是两个不同的模型,彼此之间没有很大关联.Uniformer[16]不属于本文讨论的BEV感知范畴,主要做2D时序的相关任务,如视频分类等,但涉及的时序融合方法可以参考借鉴并自成一类,也就是基于基于CNN(3D conv)的图像特征融合.
对于连续帧2D图像来说,3D卷积就是用来融合时序信息的.作者提出,单纯使用3D卷积,只能融合局部时空信息,缺乏全局性,而transformer擅长提取全局特征,却忽略了局部相关性造成的冗余.而深度神经网络在浅层以提取局部特征为主,深层提取全局特征,可以充分利用CNN和transformer的特点,实现完美的结合,即在浅层主要使用3D conv, 深层结合transformer,原话是这样使用tackle both spatiotemporal redundancy and dependency, by learning local and global token affinity respectively in shallow and deep layers.
模型架构如上图所示,代码中一共分为4个stage,前2个stage是全卷积架构,后两个stage是卷积结合self-attention,整个网络还是以CNN为主.因为任务是视频识别,也需要选取比较多的帧数,文中是前32帧+后32帧中每8帧选1帧,不需要时序对齐,分辨率是224*224.以下是在Kinetics-400&600数据集上的对比实验:

Kinetics-400&600
六.基于Stereo的图像特征融合
博主在之前做单目深度估计相关研究时,用到的主要思想是利用时序帧的pose位姿变化(可用真值也可以估计),和相机内参信息,根据多视图几何原理得到每个像素点的重投影约束,进而估计每个像素点的相对深度,如经典单目深度估计模型monodepth2[17],具体可参见博客:
苹果姐:深度估计自监督模型monodepth2论文总结和源码分析【理论部分】
[17] Digging Into Self-Supervised Monocular Depth Estimation
除了单目深度估计,应用更加广泛的是双目深度估计,也就是Stereo,因为对于单目深度估计来说,连续帧的pose信息相对比较昂贵,假如用估计的方法得到pose,又无法得到绝对深度.而双目深度估计只需要两个相机的标定准确,就可以得到绝对深度.双目深度估计的一般方法是在设定的n个离散的深度侯选值下,对其中一个视图根据标定信息进行单应性变换warp到另一个视图,再用另一个原视图与warp得到的视图计算cost volumn,进而对每个深度值做加权平均得到最终的深度值[18].
[18] MVSNet: Depth Inference for Unstructured Multi-view Stereo
对于BEV感知而言,由于2D检测已经相对成熟,3D检测的核心仍然是从多个2D图像中获取目标的深度.考虑到单目和双目深度估计都是从时序或空间的多视图中获取深度,而且对于双目深度估计而言,只要有标定好的两个视图即可,是不是同一个时刻获取的并不是关键,所以也为BEV的时序融合提供了另外一种更具理论解释性的思路,即将带有pose信息的连续帧作为双目视图进行深度估计.目前这种思路比较有代表性的是以下两篇工作:
10. BEVStereo[19] (中科院,旷视科技)
[19] BEVStereo: Enhancing Depth Estimation in Multi-view 3D Object Detection with Dynamic Temporal Stereo
code: GitHub - Megvii-BaseDetection/BEVStereo: Official code for BEVStereo

BEVStereo的框架如上图,将多视图的当前帧和前序帧分两个warp方向分别输入共享权重的两个子网络,内部同时进行单目和双目深度估计(双目由于需要匹配点对,无法覆盖所有像素点),然后将每个视图的单目和双目深度估计结果进行融合,再对多视图做外参投影和voxel pooling得到bev feature,最后接检测头.其中还有一个创新点是,在做双目深度估计计算cost volumn时,并不是像MVSNET[18]那样通过设定的多个深度侯选值进行计算,而是对每个像素点都预测了一个µ 和σ,即为每个像素点预测了一个深度分布,通过设定一系列的k值,用µ +k*σ得到每个深度候选值,这样做的好处很明显,就是可以为每个像素点使用不同的深度分布,而不是统一用一样的分布,对于深度估计结果更加准确.Stereo部分结构如下图所示:
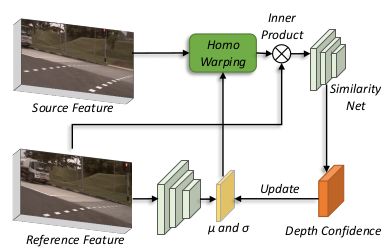
具体操作上,BEVStereo用了4帧前序sweep,每一帧都做了如上操作再进行融合.由于计算cost volume资源消耗较大,所以在backbone部分进行了16倍下采样,在stereo部分又做了4倍下采样.效果如下图所示,优势非常明显.

nuscenes test set
11.SoloFusion[20](卡耐基梅隆大学,加州大学伯克利分校)
[20] Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
code: GitHub - Divadi/SOLOFusion: Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection (waiting )

最后介绍一个较新的模型SoloFusion同样基于Stereo进行时序融合,整体思路和BEVStereo类似,但对这种方法在时序融合中的作用进行了进一步的分析.作者提到,影响时序融合效果的主要因素有两个,时序融合的区间范围和融合分辨率.关于区间范围,对于类似BEVFormer,对bev feature进行融合的方法来说,只能进行非常有限区间的融合(论文中验证了只在2s内有效),因为2s以上的bev feature重叠区间较小.但对于Stereo方法来说,区间长反而成了优势,因为两个视图的匹配点对在图像上距离较远,使深度估计变得更加简单,如下图所示:

关于融合的分辨率,自然是越大效果越好,但大的分辨率势必会带来资源消耗的增加,难以实际应用.作者通过实验证明,上文所说的增加融合区间长度可以弥补低分辨率带来的指标下降,因为增加区间长度同样可以提供更多的信息.而且,增加时序长度由于可以从缓存中读取,并不会明显降低推理的效率.作者进行了高分辨率+短时序,和低分辨率+长时序的实验,从下图可以看出,低分便率+长时序(c)带来了较小的fps下降和较大的mAP提升.如果二者结合,可以达到更好的效果.

基于以上优势,Stereo的方法可以充分发挥时序融合的潜力,而Solofusion采用长时序(16帧)+低分辨率(16倍下采样)以及短时序+高分辨率相结合的方式,可以带来更多的时序提升.下面两个表格分别对比了多个模型效果,以及各自时序版本相比单帧版本的提升,可以看出Solofusion不仅在绝对指标还是比单帧的提升上都位居前列.

nuscenes val set
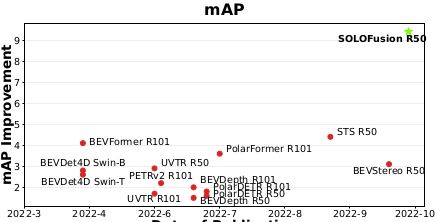
不同模型相对单帧的提升
关于BEV感知以及时序融合,还有太多值得我们学习和探索的方向.现将本文所介绍的11个模型的时序融合方法和细节进行精简整理(分辨率有限可放大观看),供有需要的读者参考备忘.
博主水平有限,如有不足欢迎留言批评指正.另本文完全原创,如有转载请注明出处.

BEV感知模型时序融合方法精简汇总