AAAI 2022:基于锚框排序的目标检测知识蒸馏|AI Drive

「AI Drive」是由 biendata 和 PaperWeekly
共同发起的学术直播间,旨在帮助更多的青年学者宣传其最新科研成果。我们一直认为,单向地输出知识并不是一个最好的方式,而有效地反馈和交流可能会让知识的传播更加有意义,从而产生更大的价值。
知识蒸馏是模型压缩的有效手段,但是目标检测网络的知识蒸馏方法却很少被研究。
传统的soft label蒸馏,在目标检测任务上基本没有提升。基于这个发现,南京理工大学计算机学院博士李钢和他的团队提出了一种适用于目标检测的锚框排序蒸馏,充分利用了检测网络中,1个目标匹配多个anchor的属性。
此外,他们的研究发现,利用特征蒸馏,虽然可以取得一定的提升,但是特征蒸馏的效率还有很大的提升空间,他们提出利用教师和学生网络的预测差异来引导特征蒸馏,让蒸馏过程更加关注于那些学生网络预测不准的区域。
本期AI Drive,由李钢详细介绍这项工作刊登于AAAI 2022的研究。
主讲人介绍:李钢,南京理工大学计算机学院博士生,研究兴趣为计算机视觉,特别是目标检测,知识蒸馏,自监督、半监督学习。在AAAI, ACM MM等人工智能顶级会议上发表论文多篇。曾在商汤研究院,上海人工智能实验室实习。

论文链接:https://arxiv.org/abs/2112.04840
本文将按照如下四个方向进行讲解(本文ppt,“数据实战派”按后台菜单指示即可获得下载地址,关注视频号“AI Drive”可观看回放):
l 介绍知识蒸馏的背景
l 介绍锚框排序蒸馏
l 实验分析和结论
l 未来工作展望
一、介绍知识蒸馏的背景

这一页PPT展示的是 coco test benchmark上的前5名的算法结果。
从前5名可以看出,目标检测任务的榜单被大模型所占据。
虽然大模型在各个视觉任务上不断地突破着性能的上限,但是大模型由于效率低,导致它们在端边业务上不可以直接使用。通过知识蒸馏,将大模型的知识传递给小模型,显著提升小模型的性能,从而使端边应用受益,是目前主流的做法。如何将知识从大模型有效地迁移到小模型,是一个非常有价值的研究问题。
二、介绍锚框排序蒸馏

在知识蒸馏的框架中,我们将能力更强的network作为教师模型,将参数量更小、更轻量级的模型叫做学生模型。我们通过把教师模型里面的Dark knowledge传递给学生模型,让学生模型有轻量级的结构的同时,也能取得和教师模型一样优秀的performance。
在检测任务里,Dark knowledge主要分为以下三个方面:
(1)基于FPN Feature的Dark knowledge;
(2)基于网络预测层面的Dark knowledge;
(3)基于relation的。在这个工作中,我们主要关注feature层面和网络预测层面的knowledge。通过我们的蒸馏算法,在coco benchmark上,R50-based RetinaNet实现了40.4% AP,超过了baseline 3.5%,同时也显著超过了之前的一些知识蒸馏的SOTA方法。
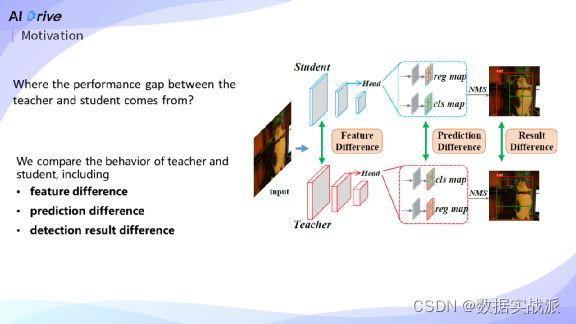
下面介绍这个工作的motivation。实现高效蒸馏的关键是,找出学生模型跟教师模型之间的差异到底体现在什么地方。
我们从以下三个方面比较了教师模型和学生模型在behavior上的差异:分别是(a) FPN Feature;(b) dense prediction,这里的dense prediction指上图中cls map和reg map;© 检测结果,这里的检测结果指的是经过了NMS之后,稀疏的检测框。

通过比较学生跟教师模型之间的差异,发现了一些非常有趣的现象。
首先通过比较学生跟教师模型的检测结果,发现了对于一些简单的样本,学生跟教师模型都能取得很好的预测结果,并且它们检测结果是从相同的anchors输出的。对于一些比较困难的样本,学生模型检测出来的box的质量比教师模型的要差,同时这两个boxes并不是从同一个anchor预测出来的。这个现象反映了对一些hard case,学生模型跟教师模型的anchor排序是不同的。我们发现了anchor的rank distribution,可以作为一种知识,从教师模型传递给学生模型。

第二点是比较了prediction和feature上的差异。
最上面一行可视化了教师模型和学生模型在网络预测上的差异,第二行是feature差异的可视化。对预测结果而言,黄框里面的区域,学生模型不需要经过蒸馏,自己也可以预测出跟教师模型一样准确的boxes;具体地,黄框区域里, prediction difference非常小,学生模型的预测和教师模型的预测非常接近。因此,在这个区域里学生模型就不需要再学习教师模型的feature。
同时我们发现在这个区域里面,学生模型跟教师模型之间的feature差异会非常大。按照以前的蒸馏方法,如,均匀地蒸馏整个feature map,这个区域就会有很大的梯度,是我们不想要的,严重影响了特征蒸馏的效率,基于这个motivation,我们提出了prediction-guided feature imitation。
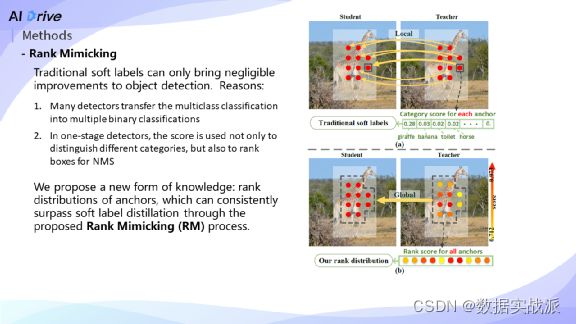
下面对我们本文提出的两个方法 - Rank Mimicking跟Prediction-guided Feature Imitation做详细介绍。因为CNN的目标检测网络有一个属性 - 在做label design的时候,一般采用的都是one-to-many的label assignment。
换而言之,一个物体会assign多个positive anchors。我们发现检测网络有能力建模不同positive anchors之间的relation,一般会赋予高质量的anchor更高的cls score。
从上图中的可视化场景可知,落在长颈鹿身上的anchors,它们可以获取到更好的pattern,所以,它们的score高于落在背景上的anchors的score。而且,从前文motivation中,可以看出Teacher model在建模anchor relation方面比student model有更明显的优势。基于这一点,我们提出了一种全新的knowledge,叫作rank distribution of anchors。
传统的Soft label在目标检测任务上只能取得很小的提升。我们分析是由于:
(1)single stage detector一般采用Focal loss,不再采用Softmax。它把multi-class的分类问题转换成了多个binary-class的分类问题,不再利用Softmax显性建模不同的类别之间的结构信息。
(2)现在有一些detector,比如说VarifocalNet、GFL,它们的score并不仅仅用于区分不同的类,也用于NMS中的排序。以上两点导致了传统的分类任务里的Soft label蒸馏,不再适用于目标检测这个任务。我们提出利用Rank Mimicking的方式来蒸馏rank distribution。

Rank Mimicking的数学形式如上图所示。和Soft label蒸馏相比,我们的Softmax不是在类别维度进行,而是在anchor维度进行,实现全局建模。然后采用KL-Divergence来优化teacher和student的rank distribution的距离。

上图详细解释Rank Mimicking跟传统的Soft label之间的差异。传统的Soft label如上图所示是一种anchor内的建模,换而言之是一种局部的建模方式,它建模是在每一个anchor的不同类别上做Softmax,而Rank Mimicking建模的是一个instance对应的所有positive anchors之间的relations。

下面介绍Prediction-guided Feature Imitation,利用预测来反向引导feature imitation。该方法在之前分类任务中,没有人尝试过。因为检测是一个dense prediction任务,使得prediction和feature的维度保持一致,才可以利用预测来反向引导特征蒸馏。
在这里,我们仅采用分类分支输出的score map来计算prediction difference. 得到teacher和student的prediction difference之后,沿着channel维度取平均,得到了特征蒸馏的soft mask。最后,把该soft mask作为特征蒸馏前面的权重,以点乘的方式乘上去即可。
学生模型在训练过程中,loss function方式可以总结成下面这三项,一是传统的检测task loss,第二项是RM loss、第三项特征蒸馏的PFI loss,通过这三项loss来引导学生模型的训练。
三、实验分析和结论
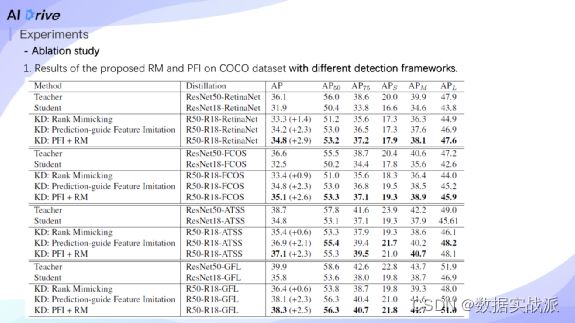
下面介绍实验结果。在coco benchmark上,我们验证了RM,PFI在不同的detection frameworks上的提升。在不同的检测器上,本文所提出的两个components都可以带来很一致的提升。

Tab.2中,我们对Rank mimicking和soft label做了比较,在三种不同的检测器上,我们提出的方法Rank mimicking稳定超越了传统的soft label,证明了Rank mimicking的优越性。
Tab.3上,除了ResNet,我们在MobileNet v2上也做了一些实验,证明了所提方法可以带来稳定的增益。Tab.4中,我们将提出的预测引导蒸馏的方式(PFI),跟以前的手工设计的特征蒸馏方法,如whole map、positive samples和negative samples蒸馏等,做了比较,发现PFI可以产生最好的性能。

此图列的是和state-of-the-art方法的比较:在coco和pascal VOC数据集上,我们的蒸馏方法都取得了最好的性能。

最后以可视化的方式展示了Rank mimicking在训练过程中带来的改变。
可以看到在蒸馏之前,对于困难样本,student跟teacher往往从不同的anchors预测出检测结果。通过Rank mimicking以后,学生模型可以从高质量的anchors得到检测结果,behavior跟teacher的更加相近了。
四、未来工作展望
以上就是我们AAAI 2022的目标检测知识蒸馏的工作介绍。接下来分享下我对知识蒸馏的未来工作展望。

(1) 在很多任务上,大模型的性能确实远超小模型。但当大模型越来越大,和小模型之间的performance gap也越来越大的时候,蒸馏所带来的性能提升是否也会增长,这是一个很重要的点。如果swinV2-L(1.3B params)和 swinV2-G(3.5B params)蒸馏R50所带来的提升是一样的话,这就使得大模型的意义减少了不少。如何让蒸馏的增益随着teacher model的capacity线性增长,是一个很有意义的问题。
(2) 不同网络结构之间的蒸馏。CNN和transform的蒸馏,其实是很困难的,普通的特征蒸馏的方法往往很难优化。如何设计一些损失函数,或者蒸馏策略,将transformer的知识有效传递给CNN,是一个待解决的问题。
(3)目前半监督检测框架,往往采用mean-teacher的范式。在训练过程中,teacher会比student稳定至少会高2-3个点。但在半监督pipeline中,teacher model仅仅是用来产生pseudo label,能不能用现有的知识蒸馏方法,提供除了pseudo label之外,其他有效的知识,比如说是否可以做特征蒸馏或Rank mimicking。