论文精度笔记(四):《Sparse R-CNN: End-to-End Object Detection with Learnable Proposals》

作者单位:港大, 同济大学, 字节AI Lab, UC伯克利
文章目录
-
- 论文以及源码获取
- 论文题目
- 参考文献
- 1. 研究背景
- 2. 贡献
- 3. 相关工作
-
- 3.1 Dense method
- 3.2 Dense-to-sparse method
- 3.3 GIoU
- 3.4 DETR
- 3.5 transformer
- 3.6 encoder-decoder
- 4. 主要内容
-
- 4.1 Sparse R-CNN
- 4.2 Dynamic Head
- 4.3 Loss
- 5. 仿真分析
-
- 5.1
- 5.2
- 5.3
- 5.4
- 5.5
- 5.6
- 5.7
- 5.8
- 6. 论文总结
论文以及源码获取
论文下载:点击
源码下载:点击
论文题目
《Sparse R-CNN: End-to-End Object Detection with Learnable Proposals》
《稀疏R-CNN:端到端基于可学习建议的目标检测》
参考文献
Sun P, Zhang R, Jiang Y, et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals[J]. arXiv preprint arXiv:2011.12450, 2020.
1. 研究背景
由于以前目标检测器是基于anchor-free和anchor-base来产生很多候选框,很明显这会形成大量关于先验框的设计和先验框与真实框多对一的映射。更会造成很多不必要的资源浪费。
其次就是基于DETR目标检测器的基础进行改进的,DETR把目标检测重新定义为直接稀疏集合预测问题,它的输入仅仅100个学习的目标队列,最后的输出没有任何人工设计的后处理过程。但是它要求每个目标队列和全局图像上下文环境进行交互(self-attention),稀疏的不够彻底,由此作者在此基础上设计了一种纯稀疏化的方式产生建议区域.那么何为稀疏化方式呢?我们简单分析一下,如图一。
a为密集检测器,在特征图上产生密集的预测,是代表Anchor-Free的RetinaNet。
b为密集-稀疏检测器,RPN仍在特征图上产生密集的先验,是代表Anchor-Based的Faster R-CNN。
c为作者提出来的是一种稀疏目标检测方法,直接提供一个N个学习对象的小集合建议。
a,b缺点:
-
产生很多冗余框,使用NMS后处理
-
使用多对一正负样本分配
-
要设计复杂的先验候选框
C优点:
-
不使用NMS后处理
-
正负样本分配采用一对一的最优二分匹配
-
候选框是一组稀疏的learnable object queries。
2. 贡献
(一)提出一种稀疏建议框的生成算法;
(二)效果比密集建议框的生成算法更佳,且不需要非极大值抑制等后处理操作;
(三)在标准的COCO数据集上使用ResNet-50 FPN单模型达到了44.5 AP和 22 FPS,超越众多anchor-free和anchor-base检测器。并作为一种全新的研究方向供我们学习。
3. 相关工作
3.1 Dense method

RPN流程
2k scores:分类anchor是否属于候选框 输出为WxHx512x2K
4k coordinates:每个anchor的四个坐标值
流程为,通过将从特征提取网络中获取到的feature map进行3*3的卷积运算,输出的通道数为512,然后这里的k个anchor boxes指的是每一次3x3卷积所对应的中心都会生成K个锚框,K通常为9,为了能更好的覆盖所有可能的情况。
三种scale/size是{128,256,512}
三种比例{1:1 , 1:2 , 2:1}
最后通过分类层和回归层得到2k scores和4k coordinates。
3.2 Dense-to-sparse method
《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》

整个faster R-CNN的流程:
- 共享卷积网络-VGGNet
- 候选检测框生成网络RPN(Region Proposal Networks)
- Roi(Region of Interest) Pooling(根据框的坐标值从feature map 中提取相应的区域)
- Classifier
目标检测整体流程:先通过特征提取网络VGG获得一系列的feature map,然后将得到的feature map一部分传到RPN网络,获得候选框,这里的候选框就相当于把每个类别都框出来,但是我并不知道这个类别是属于什么,这时候在结合另外一条支路直接将feature map传输classifier这里,相当于将得到的候选框印到原始特征图上,这里RoI pooling 的作用就是根据所得到的候选框的坐标值从feature map中提取相应的区域,RPN在特征图中会产生尺寸不一致的候选区域,所以RoI pooling也有固定尺寸的作用。最后在通过分类层判断所属目标的类别。

faster R-CNN详细架构
前面部分也就是VGG16的整个部分了,先是将原始的大小的P*Q的图片resize成MxN的尺寸,然后在通过13个卷积层,13个relu激活函数和4个池化层,提取特征得到feature map,然后一部分送入到我们的RPN网络中,通过3x3的slide window,去遍历整个feature map,在遍历过程中每个window中心按和三个尺度和三个长宽比生成9个anchors。
上面一条支路为分类头,判断是否为背景,所以是二分类,通过1x1的卷积操作,生成通道数为18,这里的18是由于9个anchor都需要进行二分类,所以是9x2。再通过reshape操作和softmax归一化操作判断每个anchor属于前景还是背景,判断之后在通过reshape进一步获取到非背景区域的候选框,下面这一条支路是回归头,通过1x1卷积生成36的输出通道数,36是因为4x9,每个anchor都有4个坐标值。最后将两个支路进行结合,从而更准确的在特征图上框出候选框的大致位置。再通过RoIPooling前的NMS过滤掉置信度很小的候选框和RoIPooling将不同大小的输入转换为固定长度的输出并根据所得到的候选框的坐标值从feature map中提取相应的区域。
最后通过分类和回归预测并输出候选区域所属的类以及候选区域在图像中的位置。这就是整个Faster R-CNN的流程。也就是密集到稀疏方法的过程。
3.3 GIoU


输入为预测框和真实框,我们先通过AB找到最小包围框C,然后根据A,B所在区域计算其IOU大小,然后根据第三个公式计算就可以得到GIoU。解决了IOU在无重叠时也可以反应两个目标之间的距离和能够有效区分重叠的方式。
3.4 DETR

由于这篇论文是基于DETR改进的,我们这里来看看DETR的整个工作流程。开始说过了这篇论文是不需要RPN网络和NMS来产生候选框的,算是Sparse 的先祖。整个流程就是先通过输入一张图像,扔到CNN卷积网络中获取到一系列的特征和位置,然后将每一个位置的点按顺序排列出来传入到transformer,每个点的维度都是transform的序列,(画竖线)所以有H*W个这样的竖线,代表feature map的维度,不是图片的维度,由于在CNN里面做了五次下采样所以大概是图片维度的1/3.通过transformer的编解码出来,就会生成100个预测框(固定的),本身序列长度是很长,但是出来只有100,所以这是不定长序列的映射问题,后面我们会继续分析这个transformer是怎么做的。然后映射出来的predictions就包含不同的类别和bbox,这里通过颜色来进行区分。 (误检和框大小进行loss惩罚,通过反向传播回去。)这里的匹配是N对N的,这时候就会存在问题,图片的真实框中并不会有100个真实框,像右图只有两个框,DETR的作者就通过将剩余的98个框通过在图片上其它背景位置画框来解决,这就可以满足N对N的问题。 这里的loss其实和这篇论文的loss也很相似,中心点和iou
3.5 transformer

这里是整个transformer编解码的过程,特别注意到这里的position encoding,它的矩阵形状和图片通过CNN提取特征在经过下采样之后的矩阵形状保持一致,在将两者结合起来,目的是为了把………,并作为multi-head attention的输入,然后将其展成一列向量,就像是我上面画的红色的线,排列好了之后通过encoder生成一样的数目的序列,然后在送入到decoder里面的,这里的object queries只有四个序列,而通过编码出来的序列却非常多,那究竟这里是怎么通过编解码进行交互的呢?
3.6 encoder-decoder
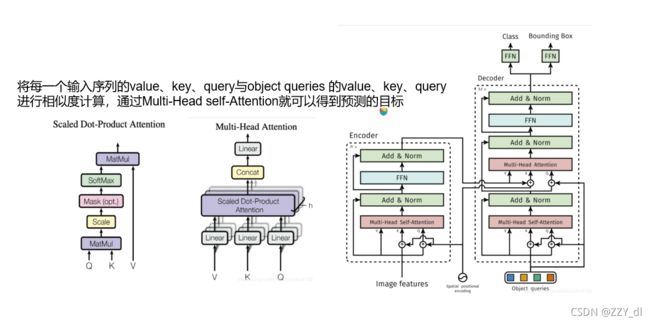
我们简单看一下Multi-Head self-Attention和Scaled Dot-Product Attention的结构就行了,因为这篇论文主要是运用相似的编解码的原理获取到一系列的候选特征,与固定学习到的候选框进行结合,提高准确性。编解码的大致过程就是这样的。下面我们看看这篇论文的主要内容。
4. 主要内容
4.1 Sparse R-CNN

整体网络架构
Sparse R-CNN :骨干网+动态检测交互头+分类和回归层
Proposal Boxes-N*4,N代表object candidates的个数,一般为100~300,4代表物体框的四个边界。
先是由骨干网提取特征图,这里proposal boxes可以理解为图像中可能出现物体的位置的统计值,是可学习的参数,但是这样提取出来的特征并不能很好的定位和分类物体,于是引入了一种特征层面的proposal features这也是一组可学习的参数,然后将两者结合同时送入到动态检测交互头,做一对一的交互,可提取出更精确的RoI feature,最后输出分类和位置。
输入包括一个图像、一组候选框和候选特性,其中后两个是可学习的参数。
分析完整个的结构,让我们单独看看动态检测交互头具体是怎么实现的呢?
4.2 Dynamic Head
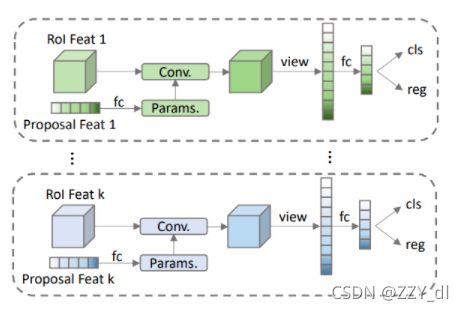
Dynamic Head
Conv=relu(norm(bmm(roi_Feats,param)))
这里的norm作为归一化层,和以前的BatchNorm有所区别

batch normalization对一个神经元的batch所有样本进行标准化,layer normalization对一个样本同一层所有神经元进行标准化,前者纵向 normalization,后者横向 normalization。BN层如果对于小Batchsize效果并不好,所以作者这里采用的是LN归一化的方法。
卷积之后将得到的RoI_Feature通过flatten的方式得到与原始的RoI_Feature相同尺寸维度的特征,然后通过一个全连接层得到与proposal feature相同尺寸维度的特征,这样做的意义是为了循环操作,也就是后面会提到的iterative。如果循环完毕就可以直接通过全连接层的目标特征进行分类预测和位置预测。
4.3 Loss

这篇论文损失函数包括三个:分类损失为焦点损失,IOU损失为GIoU损失,L1为L1损失
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。相当于困难样本挖掘。γ相当于放大系数,取2最优。γ利用幂函数的快速放缩特性动态调节简单样本权重降低的速率。对于正样本Pt越大,通过1-Pt得到的新的权重就越小,换句话说对于这类的易分样本就不用花更多的注意力了,反而对于困难的样本会更加重视,这里的αϵ[0,1]。
giou loss是1-GIoU。
L1 范数loss:目标值(Yi)与估计值(f(xi))的绝对差值的总和
5. 仿真分析
5.1

5.2

5.3

5.4

5.5
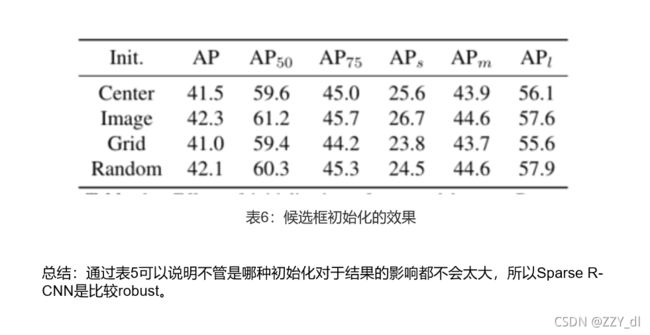
5.6

5.7
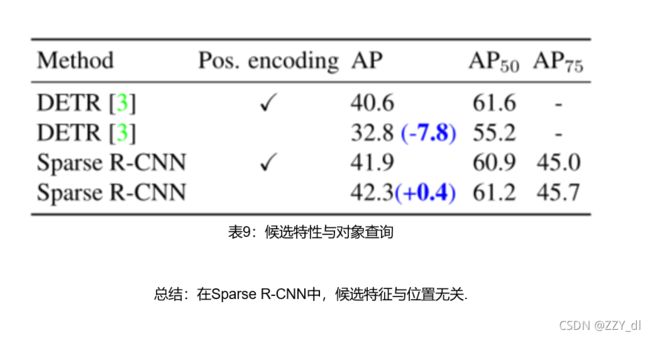
5.8

迭代架构中每个阶段预测框的可视化,包括已学习的候选框,显示分类分数在0.2以上的框,学会的建议框是白色的,同一类候选的方框用同样的颜色绘制,学习的候选框随机分布在图像上,并一起覆盖整个图像:我们还可以发现每个阶段都会逐渐细化boxes的位置,并删除重复的。在单人场景、道路场景、人群场景都表现出一个出色的性能。
6. 论文总结
- 提出一种稀疏的目标检测算法,通过一组固定的可学习的proposals为dynamic heads做分类和位置回归
- 最终预测是直接输出的,没有NMS后处理操作
- Sparse R-CNN的准确性、运行时间和训练收敛性能与建立良好的检测器相当。这个工作还能够激发对密集先验惯例的反思,并探索下一代物体探测器。