【Block总结】CDFA,对比驱动特征聚合模块|即插即用,极大增强特征表达!
论文信息
- 标题: ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
- 作者: Mengqi Lei, Haochen Wu, Xinhua Lv, Xin Wang
- 机构: 中国地质大学(武汉),百度公司
- 发表时间: 2024年12月11日
- 会议: AAAI 2025
- 论文: https://arxiv.org/pdf/2412.08345
- GitHub链接: https://github.com/Mengqi-Lei/ConDSeg
论文概述
ConDSeg框架旨在解决医学图像分割中的两个主要挑战:前景与背景之间的“软边界”问题,以及医学图像中普遍存在的共现现象。这些问题导致模型在分割时容易产生误判。为此,ConDSeg引入了多种创新模块,以提高分割性能。
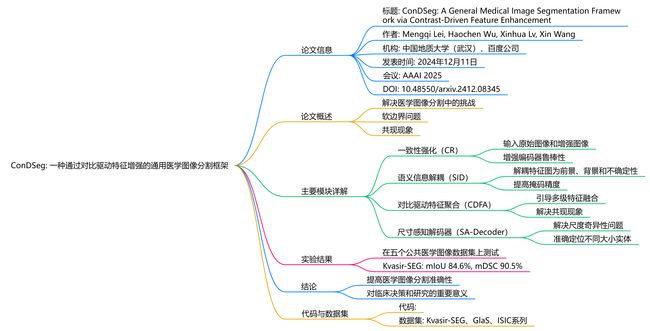
主要模块详解
-
一致性强化(Consistency Reinforcement, CR):
- 该模块通过输入原始图像和经过强增强的图像到编码器,最大化预测掩码之间的一致性,从而增强编码器在不同光照条件下的鲁棒性。这使得模型能够在恶劣环境中提取高质量特征。
-
语义信息解耦(Semantic Information Decoupling, SID):
- SID模块将编码器输出的特征图解耦为前景、背景和不确定性区域的特征图。通过设计的损失函数,训练过程中逐渐减少不确定性区域,提高前景和背景掩码的精度。
-
对比驱动特征聚合(Contrast-Driven Feature Aggregation, CDFA):
- CDFA模块利用SID模块解耦的前景和背景特征,引导多级特征融合和关键特征增强,进一步区分待分割的实体。该模块通过对比前景和背景特征,解决共现现象带来的挑战。
-
尺寸感知解码器(Size-Aware Decoder, SA-Decoder):
- SA-Decoder解决了解码器的尺度奇异性问题,能够准确定位图像中不同大小的实体,避免错误学习共现特征。通过不同层次的特征图预测不同大小的实体,提高了模型在图像中区分不同实体的能力。
对比驱动特征聚合模块(CDFA)的具体工作原理
对比驱动特征聚合模块(Contrast-Driven Feature Aggregation, CDFA)是ConDSeg框架中的一个关键组件,旨在通过对比前景和背景特征来增强医学图像分割的性能。以下是CDFA的具体工作原理:
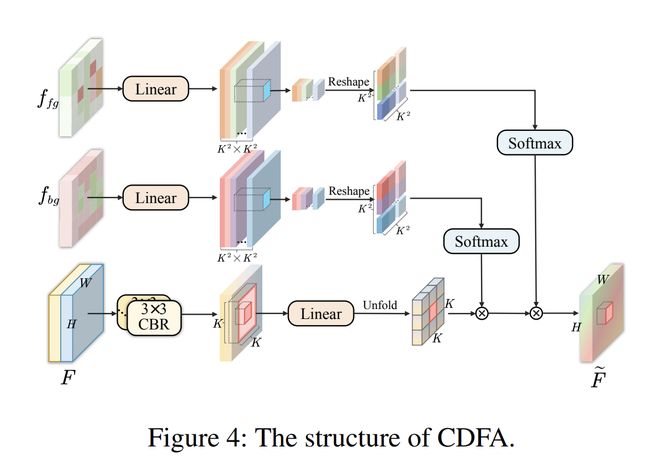
1. 特征输入与预处理
CDFA模块接收来自语义信息解耦模块(SID)的前景特征和背景特征。这些特征经过解耦后,分别包含了与前景和背景相关的信息。CDFA的输入包括:
- 前景特征(fg): 代表待分割的目标区域。
- 背景特征(bg): 代表图像中非目标区域的信息。
2. 特征融合与增强
CDFA模块的核心在于通过对比前景和背景特征来引导多层次特征的融合和关键特征的增强。具体步骤如下:
-
特征转换: 输入的前景和背景特征首先经过一系列卷积层进行处理,以提取更丰富的特征表示。
-
注意力机制: CDFA利用注意力机制来计算前景和背景特征之间的关系。通过显式建模前景特征和背景特征的对比关系,CDFA能够增强输入特征图的语义表达能力。
-
加权特征融合: CDFA根据计算得到的注意力权重,对前景和背景特征进行加权融合。这一过程确保了模型能够更好地区分待分割的实体,减少共现现象带来的干扰。
3. 输出生成
经过加权融合后的特征图将被送入后续的解码器进行处理,最终生成分割掩码。CDFA的设计使得模型能够在不同尺度上有效地定位和分割图像中的不同实体。
实验验证
在多个医学图像数据集上的实验表明,CDFA模块显著提高了模型的分割性能。例如,在Kvasir-SEG数据集上,使用CDFA的ConDSeg框架在平均交并比(mIoU)和Sørensen-Dice系数(mDSC)等指标上均优于其他传统方法,如U-Net和TGANet。
总结
CDFA模块通过对比前景和背景特征,利用注意力机制和加权融合策略,增强了模型对医学图像中复杂特征的理解能力。这一模块的引入有效地解决了医学图像分割中的共现现象和模糊边界问题,提升了整体分割性能。代码:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class CBR(nn.Module):
def __init__(self, in_c, out_c, kernel_size=3, padding=1, dilation=1, stride=1, act=True):
super().__init__()
self.act = act
self.conv = nn.Sequential(
nn.Conv2d(in_c, out_c, kernel_size, padding=padding, dilation=dilation, bias=False, stride=stride),
nn.BatchNorm2d(out_c)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
if self.act == True:
x = self.relu(x)
return x
class ContrastDrivenFeatureAggregation(nn.Module):
def __init__(self, in_c, dim, num_heads, kernel_size=3, padding=1, stride=1,
attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.v = nn.Linear(dim, dim)
self.attn_fg = nn.Linear(dim, kernel_size ** 4 * num_heads)
self.attn_bg = nn.Linear(dim, kernel_size ** 4 * num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.unfold = nn.Unfold(kernel_size=kernel_size, padding=padding, stride=stride)
self.pool = nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True)
self.input_cbr = nn.Sequential(
CBR(in_c, dim, kernel_size=3, padding=1),
CBR(dim, dim, kernel_size=3, padding=1),
)
self.output_cbr = nn.Sequential(
CBR(dim, dim, kernel_size=3, padding=1),
CBR(dim, dim, kernel_size=3, padding=1),
)
def forward(self, x, fg, bg):
x = self.input_cbr(x)
x = x.permute(0, 2, 3, 1)
fg = fg.permute(0, 2, 3, 1)
bg = bg.permute(0, 2, 3, 1)
B, H, W, C = x.shape
v = self.v(x).permute(0, 3, 1, 2)
v_unfolded = self.unfold(v).reshape(B, self.num_heads, self.head_dim,
self.kernel_size * self.kernel_size,
-1).permute(0, 1, 4, 3, 2)
attn_fg = self.compute_attention(fg, B, H, W, C, 'fg')
x_weighted_fg = self.apply_attention(attn_fg, v_unfolded, B, H, W, C)
v_unfolded_bg = self.unfold(x_weighted_fg.permute(0, 3, 1, 2)).reshape(B, self.num_heads, self.head_dim,
self.kernel_size * self.kernel_size,
-1).permute(0, 1, 4, 3, 2)
attn_bg = self.compute_attention(bg, B, H, W, C, 'bg')
x_weighted_bg = self.apply_attention(attn_bg, v_unfolded_bg, B, H, W, C)
x_weighted_bg = x_weighted_bg.permute(0, 3, 1, 2)
out = self.output_cbr(x_weighted_bg)
return out
def compute_attention(self, feature_map, B, H, W, C, feature_type):
attn_layer = self.attn_fg if feature_type == 'fg' else self.attn_bg
h, w = math.ceil(H / self.stride), math.ceil(W / self.stride)
feature_map_pooled = self.pool(feature_map.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn = attn_layer(feature_map_pooled).reshape(B, h * w, self.num_heads,
self.kernel_size * self.kernel_size,
self.kernel_size * self.kernel_size).permute(0, 2, 1, 3, 4)
attn = attn * self.scale
attn = F.softmax(attn, dim=-1)
attn = self.attn_drop(attn)
return attn
def apply_attention(self, attn, v, B, H, W, C):
x_weighted = (attn @ v).permute(0, 1, 4, 3, 2).reshape(
B, self.dim * self.kernel_size * self.kernel_size, -1)
x_weighted = F.fold(x_weighted, output_size=(H, W), kernel_size=self.kernel_size,
padding=self.padding, stride=self.stride)
x_weighted = self.proj(x_weighted.permute(0, 2, 3, 1))
x_weighted = self.proj_drop(x_weighted)
return x_weighted
if __name__ == '__main__':
# 创建一个随机输入张量,形状为 (batch_size,height×width,channels)
input1 = torch.rand(1, 64,40, 40)
# 创建一个随机输入张量,形状为 (batch_size,height×width,channels)
input2 = torch.rand(1, 64,40, 40)
# 创建一个随机输入张量,形状为 (batch_size,height×width,channels)
input3 = torch.rand(1, 64,40, 40)
# 实例化EFC模块
block = ContrastDrivenFeatureAggregation(64,64,num_heads=8)
# 前向传播
output = block(input1,input2,input3)
# 打印输入和输出的形状
print(input1.size())
print(output.size())
输出结果:
torch.Size([1, 64, 40, 40])
torch.Size([1, 64, 40, 40])