跨模态行人重识别:Learning with Twin Noisy Labels for Visible-Infrared Person Re-Identification学习记录
目录
摘要
方法
Co-modeling
Pair Division
DART
试验结果:
论文链接:Learning with Twin Noisy Labels for Visible-Infrared Person Re-Identification
摘要
双噪声标签(TNL),即噪声标注和对应。简而言之,一方面,由于数据收集和注释的复杂性,例如红外模态的可识别性差,不可避免地会以错误的身份对一些人进行注释。另一方面,单一模态中错误注释的数据最终会污染跨模态对应关系,从而导致噪声对应关系。
为了解决 TNL 问题,提出了一种新的鲁棒 VI-ReID 方法,称为双重鲁棒训练 (DART)。简而言之,DART 首先利用深度神经网络的记忆效应计算注释的干净置信度。然后,所提出的方法用估计的置信度纠正噪声对应,并将数据进一步分为四组以供进一步利用。最后,DART 采用了一种新颖的双重鲁棒损失,包括软识别损失和自适应四元组损失,以实现对噪声注释和噪声对应的鲁棒性。
方法
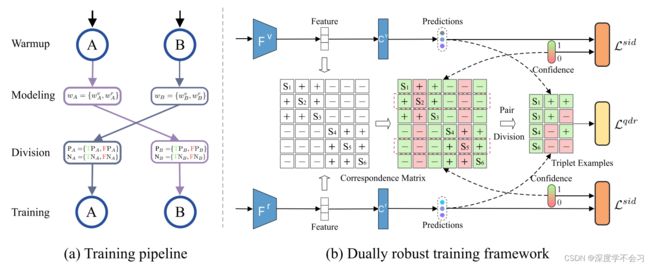
(a):DART 的训练管道。简而言之,DART 由两个单独的网络 (A,B) 组成,它们以共同教学的方式工作。更具体地说,DART 首先使用 Eq. 2预热 A 和 B 初始化。之后,在每个时期,执行以下过程。首先,网络 A/B 对每个样本的识别损失分布进行建模,以估计每个样本的正确注释置信度 w,然后将 w 输入 B/A 进行进一步训练。下一步将数据对分成四个子集,即TP、FP、TN和FN,并纠正它们的对应关系。最后,估计的置信度和修正对用于训练网络。 (b):A 和 B 的双重鲁棒训练框架。图中,“S”、“+”和“-”分别表示锚点、正样本和负样本。置信度高于特定阈值的样本将为绿色,否则为红色。如图所示,主干将首先分别提取可见光和红外模式的特征。然后,这些特征被馈送到分类器以获得预测并用于构建对应矩阵。之后,用估计的置信度建立对应矩阵,红色的anchor由于置信度过低而被丢弃。在配对划分模块的帮助下,配对将被分为四组,然后将它们组合为三元组(参见 (b) 中的一些组合示例)以进行优化。最后,预测、三元组和置信度用于通过最小化我们的损失来实现双重鲁棒训练。
Co-modeling
利用深度神经网络的记忆效应计算每个样本正确标注置信度的联合建模模块。
DART 将把可见光和红外模态投射到共享的潜在空间中,通过 {Fv, Cv} 和 {Fr, Cr},其中 Fv 和 Fr 是两个具有一些共享层的特征提取器 ,Cv 和 Cr 是两个分类器。使用特征 Ft(xti) 和注释 yti ,分别得到成对对应矩阵 Yp 和距离矩阵 D,其中 yp ij 是噪声对应,dij 表示潜在空间中 (xvi , xrj ) 之间的距离。即

注释 yt i 和 对应yp ij 都可能有噪声。为了处理嘈杂的注释问题,DNN 易于拟合简单模式,因此在初始训练阶段导致干净(即简单)样本的损失相对较小。基于这一观察,可以通过对损失分布建模来计算样本被正确注释的概率。具体来说,给定具有参数 θt (t ∈ {v, r}) 的模态特定网络 {Ft, Ct},我们通过以下方式计算每个样本的识别(交叉熵)损失
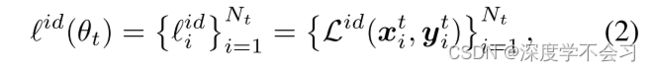

对两分量高斯混合模型进行建模来拟合所有训练数据的每样本损失分布,如下所示:

其中 γk 和 φ(id | k) 分别是第 k 个分量的混合系数和概率密度。根据 DNN 的记忆效应,我们可以计算每个样本 i 通过小均值分量 κ 上的后置概率得到正确注释的置信度 wi,即

如果简单地使用自建模置信度训练神经网络,它可能会引入误差累积。为了避免偏差,我们采用了共建模方法。具体来说,我们分别训练两组具有相同架构但初始化不同的网络,即 A = {Fv A, Cv A, Fr A, Cr A} 和 B = {Fv B, Cv B, Fr B , 铬 B}。在每个时期,网络 A 或 B 将建模一个 GMM 以分别拟合用于计算置信度的损失分布。然后,将置信度输入另一个网络进行进一步训练。
Pair Division
详细阐述了如何将对分成不同的组并纠正它们的对应关系。
由于协同建模模块,可以估计注释的干净置信度,这将用于将数据对划分为干净和噪声部分。之后将这些部分进一步分为四个子集,即真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)对。
采用模态混合策略从模态内部和跨模态构建对。对于给定对 (xt1 i , xt2 j ) 与噪声对应 yp ij 其中 tk ∈ {v, r}, k ∈ {1, 2},在估计的注释置信度上设置阈值 η 以将它们分成干净的部分 Sc = {(xt1 i , xt2 j ), yp ij | wi > η, wj > η} 和噪声部分 Sn = {(xt1 i , xt2 ), yp ij | wi > η, wj ≤ η}, 其中 i 和 j 分别为索引锚点和正(yp ij = 1) 或 负 (yp ij = 0) 样本。值得注意的是,我们丢弃了锚的置信度小于 η 的对,因为它们无法正确划分。校正{Sc, Sn}的对应关系后,新得到的对应关系记为{^Sc,^Sn}。整改操作如下:

其中 II(yp ij ∈ Sc) 表示该对是否属于干净部分,O是 异或操作。 Eq 6表示如果正对(yp ij = 1)来自Sc,则为TP;否则 FP。同样,来自 Sc 和 Sn 的负数分别被视为 TN 和 FN。
对于 FN 对,我们将进一步细化以提高准确性。具体来说,对于负样本 xt2 j ∈ Sn,如果其置信度 wj 不大于 η(即 wj ≤ η),同时其身份与锚样本不同(即 yt1 i != yt2 j ),应该是TN但被错误地视为FN。我们通过重建这样的TN对来修改它们的对应关系,

其中ct(ft(xt,i))是注释预测。 公式 6-7中,所有训练对将被分成TP、FP、TN和FN子集中的一个。
DART
通过协同建模和划分模块,DART可以获得注释置信度并纠正对的对应关系。 然后利用以下损失来实现鲁棒的VI-Reid:
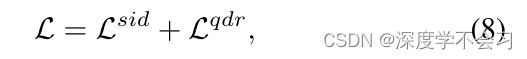
其中Lsid和Lqdr分别是软识别损失和四重损失,分别用于对抗噪声注释和噪声对应。
对噪声注释的鲁棒性
对于网络A或B,我们不是简单地丢弃带有噪声注释的样本[6],而是利用置信度WI来抑制优化过程中的噪声。 为此,提出了以下软识别损耗:

其中t∈V,R}表示可见或红外模态。
对噪声对应的鲁棒性
用四对子集(TP,FP,TN和FN),DART需要在它们的帮助下缓解模态差异。 由于原始三重损失只能处理TP和TN的组合,因此有必要开发一种新的方法来处理四个子集的所有可能组合(以三重形式)。
根据它们的校正对应关系,这些三元组可分为TP-Tn(YP y P ik=1)、TP-Fn(YP ij=1,YP ik=0)、FP-Fn(YP y P ij=1,YP ik=1)、FP-Tn(YP ij=0,ij=0,ik=0)。 值得注意的是,后三种组合是本文重点讨论的含噪通信。
为了解决这样一个有噪声的对应问题,我们提出了以下自适应四重丢失:


其中m是我们实验中固定为常数的边距, 和
和 分别表示异或和异或非运算。 由于TP-FN和FP-TN都是均匀对,现有的三重损耗不能处理这种情况。 因此,我们建议另外对置信度ws>η的对(xt1 i,xt4 s)进行抽样,以使用以下四重项:
分别表示异或和异或非运算。 由于TP-FN和FP-TN都是均匀对,现有的三重损耗不能处理这种情况。 因此,我们建议另外对置信度ws>η的对(xt1 i,xt4 s)进行抽样,以使用以下四重项:

Lqdr在不同情况下所享有的健壮性:

TP-TN(图3(a)):对于分成TP(YP ij=1)或TN(YPik=0)的配对,目标是减小TP的成对距离,同时增加TN的成对距离。 在这种情况下,LQDR将自适应地转化为香草三重损失,如下所示:
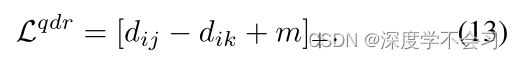
FP-Fn(图3(b)):对于分成Fp(Ypij=0)或Fn(Yp ik=1)的配对,目标是增加Fp的成对距离而减少Fn的成对距离。 然后,LQDR变成:
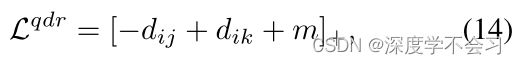
TP-FN(图3(c)):对于分成TP(YPij=1)或FN(YP ik=1)的对,目标是增加TP和FN对的成对距离。 然后,LQDR变成 :
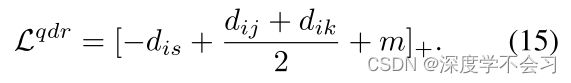
FP-TN(图3(d)):对于分成FP(YP ij=i0)或TN(YPk=0)的配对,目标是减小FP和TN的成对距离。 然后,LQDR变成:
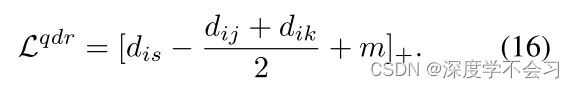
试验结果:
