小样本目标检测综述 --刘浩宇,王向军 --阅读笔记
文章目录
-
- 1 基本背景
- 2 大样本与小样本的对比
- 3 在没有大量数据支持的情况下,小样本检测保证检测效果,有哪些解决方法?
-
- 3.1 数据域:
-
- 3.1.1 转化原有数据集 D t D_t Dt r _r r a _a a i _i i n _n n
- 3.1.2 迁移其他数据集
- 3.2 模型域
-
- 3.2.1 多任务训练网路
- 3.2.2 增量学习网络
- 3.2.3 迁移学习网络
- 3.3 算法域
1 基本背景
首先什么是小样本学习?
小样本学习是指在样本数据不足或质量较低的情况下进行的深度学习训练和预测的方法。
早期深度学习目标检测方法存在哪些问题?
- 依赖样本的数据的分布与数量,需要足够多的已标注样本的来支持检测效果。但是这样会引入较高的制作成本。
- 早期应用大量标注样本回归候选框的位置,目标集与训练集数据分布不同会导致检测效果下降。
- 在军工业场景下,大量的数据样本不易得。
2 大样本与小样本的对比

- 在有大量样本数据的情况下,模型训练误差是很小的。如果样本数量足够大,模型训练误差甚至可以趋于0

- 但当样本数量很小时,模型无法很好地拟合真实分布,往往会造成很大的模型训练误差。
3 在没有大量数据支持的情况下,小样本检测保证检测效果,有哪些解决方法?
- 数据域 : 通过先验知识来做数据增强,通过数据量的增大解决模型不收敛的问题。
- 模型域 : 通过先验知识来限制模型复杂度,降低假设空间的大小,使得模型收敛加快。
- 算法域 : 通过先验知识来提供一个更快捷的搜索策略。
3.1 数据域:
- 本质上就是通过各种数据增强的方法,增加样本容量,增加参数优化与迭代的次数;相当于提供了先验知识,帮助训练模型更接近训练能够达到的最佳模型。
- 由于被检测目标的真实分布是不可知的p(x,y),绝对准确的先验知识是不可获得的。

3.1.1 转化原有数据集 D t D_t Dt r _r r a _a a i _i i n _n n
我们在做pcb瑕疵检测的时候也发现:一开始使用deeppcb方法的时候,对于论文本身的复现效果较好,而对于我们自己真实的数据指标只有30%多,但是经过筛选并做数据增强之后(筛选主要是从缺陷的宽高比以及相对图像的大小进行筛选以尽量符合deeppcb本身数据集的属性),指标达到了74%左右,有明显提升,这或许正说明了deeppcb模型泛化性不好是由于预先设定的9种默认框是符合deeppcb本身数据集的缺陷分布状态的,也就是综述里说的,先验知识。如果我们想改善对我们数据集的性能,就需要去改变这个所谓的先验知识,修改默认的9种框的宽高比以及大小。在ppyoloe的测试中也有类似情况,对于个别图像出现的漏检现象,或许也正是训练集与目标检测集之间的分布不同导致的,实验发现,将漏检图像放入训练集,重新测试漏检大大降低。
我们之前做过的数据增强:属于转化原有数据集Dtrain的图像增强,支持LabelIMg和LabelMe标注的文件,能实现LabelIMg标注后的图片的增强(包括模糊,亮度,裁剪,旋转,平移,镜像等多种操作的随机组合)。在实验中也确实发现,图像增强可以提升一些训练效果,但作用有限。
源码地址:https://github.com/pureyangcry/tools
综述中提到的这种方案或许以后可以用到:
Zoph等提出了一种自动检索并采用可行的符合应用任务特点的图像增强方案AutoAugment,创建了一个数据增强策略的搜索空间,利用搜索算法选取适合特定数据集的数据增强策略,其尝试的数据增强策略共计22种,可以概括为:色彩变换,扭曲颜色通道而不影响包围框的位置,如对比度、亮度等 、几何变换(几何尺度上扭曲图像,相应地改变包围框注释的位置和大小,如旋转、剪切、平移等) 、包围框变换只扭曲包围框注释中包含的像素内容,如候选框旋转、候选框翻转等 。 其方案特别有益于数据集和小目标的检测。
论文传送门:https://arxiv.org/abs/1906.11172
源码传送门:https://github.com/tensorflow/tpu/tree/master/models/official/detection
3.1.2 迁移其他数据集
另一种数据域的数据增强方式是迁移其他数据集,目前流行的一种方法是引入对抗生成网络产生与训练集Dtrain分布相同的数据作为补充。
之前我们一直在使用监督训练的方法,下面这种Nguyen提出的半监督目标检测方法或许也可以尝试。
Nguyen 将未标记图像的训练作为一种潜在变量模型,提出了一种基于期望最大化的未标记图像半监督目标检测方法,对目标检测的分类部分和定位部分进行了潜在标签估计,并对模型进行了优化。在COCO数据集上,半监督相较于监督学习有0.7%的指标提升。
Huang等借助GAN通过白天的数据生成了夜间的数据,看起来效果不错。
Nguyen半监督目标检测方法论文地址:Semi-supervised object detection with unlabeled data .
Huang论文地址: AugGAN:cross domain adaption with GAN-based data augmentation
3.2 模型域
目标检测所采用的模型决定了模型空间P的大小;模型域解决方案的基本原理是:选取较大的模型空间P,再通过先验知识缩小空间。如下图:
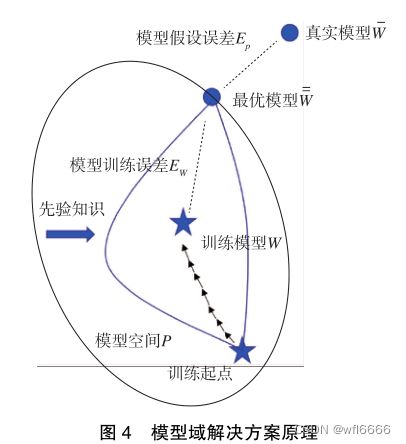
我认为,我们对ppyoloe的网络结构的修改可以认为是模型域解决方案。原本ppyoloe的输入是一张3通道的图片,训练之后发现效果没有那么好,漏检现象比较明显,但在我们修改ppyoloe的输入为成对输入(test+temp),经过3层卷积进行浅层特征提取后做特征差,让模型更关注于原图和模板图的差异,实验表明,达到了更好的效果;我觉得添加模板图的输入就是给了模型一个先验知识,缩小了模型空间,使模型更容易贴近训练的最佳模型,也就更贴近真实模型。
3.2.1 多任务训练网路
多任务训练网络:比如Luo等通过一个预先训练的卷积神经网络CNN从源域中的源任务学习来初始化CNN在目标域中的目标任务。在训练过程中,使用从多层CNN的表示中计算出的对抗损失来迫使两个CNN项目样本进入一个任务不变空间。该方法在新领域的新类上显示了令人信服的结果,即使每个类只有几个标记的例子可用,也优于流行的微调方法。
论文地址:Label efficient learning of transferable representations across domains and tasks.
多任务之间进行共享参数是一个很好的思路,我认为在ppyoloe中也类似的提出了一个新颖的头部ET-head,并在T-head的基础上做了优化,平衡速度和精度,核心还是T-head。T-head目的是为了解决传统one-stage的分类与定位任务之间的不对齐问题,为了进一步克服分类和定位的偏差,在论文中提出了任务对齐学习(TAL),它由动态标签分配和任务对齐损失组成。动态标签分配意味着预测/损失感知。根据预测结果,为每个ground-truth分配动态数量的正锚。通过显式对齐两个任务,TAL可以同时获得最高的分类分数和最精确的包围框。这是我认为与综述中提到的深度卷积特征在不同任务中的共享可以一定程度上提高检测精度是一致的。

该图显示了TOOD(提出T-head)在无锚法中的效果,有了更精准的锚点,成功对齐了分类与定位任务,而不是第一张图片中红色锚点置信度高但是定位更接近披萨,绿色锚点定位准确为桌子但置信度低而被红色锚点NMS抑制。
3.2.2 增量学习网络
另一种模型域的解决方法是增量学习网络:增量学习是指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分已学习到的知识,其实现方式非常类似于人类自身的学习模式。
增量学习更像是一种理想状态,比如我们使用微调好的ppyoloe对之前筛选掉的原始数据进行测试有漏检现象,第一解决思路就是将所有原始数据重新按比例增强后重新训练,虽然可行,但费时费力。增量学习这种新思路如果可以避免灾难性遗忘的话,好像更加巧妙,而且在工业场景下会不断出现新的缺陷类型,增量学习的方式也更加合适。
一种用于增量学习的检测器ONCE:Incremental few-shot object detection .
3.2.3 迁移学习网络
还有一种模型域解决方案是迁移学习网络:当给定的已标注训练样本不足以完成训练时,可以将其他类似域的先验知识转移到当前应用中,以缓解目标域样本不足导致的效果较差的问题,域适应的方法通常用来提升目标域上的定位效果。
3.3 算法域
算法域解决方案的基本原理是:找到一种模型空间P中快速搜索最优模型的策略,这种策略可以利用先验知识来改变参数θ的搜索过程,使模型在有限次的迭代下快速收敛,其具体原理下图所示:

元学习:区别于其他优化方式使模型更接近最优模型,元学习的优化策略直接目标是真实模型, 其目标是让机器“学会学习”。元学习拟合一系列相似任务的分布,利用元学习器将各个学习任务的参数合成,以此获得一个好的初始化参数。本质上是要寻找一个对于所有任务都较优的模型参数。
最后,由于本人知识储备有限,尽量花费大量时间阅读综述,仍觉理解不足,以上有理解错误之处,敬请指证;在本综述中提到的一些思路与方法,可以参考具体的文献。