YOLOV5学习笔记(一)——原理概述
目录
一、目标检测概述
1.1 数据集介绍
1.2 性能指标
1.2.1 混淆矩阵
1.2.2 IOU(边界框回归)
1.2.3 AP&mAP
1.2.4 检测速度
1.3 YOLO发展史
1.3.1 算法思想
1.3.2 YOLOv5网络架构
一、目标检测概述
1.1 数据集介绍
- PASCAL VOC

- MS COCO

1.2 性能指标

1.2.1 混淆矩阵

1.2.2 IOU(边界框回归)
IOU=1 是完全重叠

根据IOU设置的阈值来判断是TP还是FP ,比如重叠为0.5

1.2.3 AP&mAP
AP是衡量学习出来的模型在每个类别上的好坏
mAP是衡量学习出来的模型在所有类别上的好坏是AP的平均值
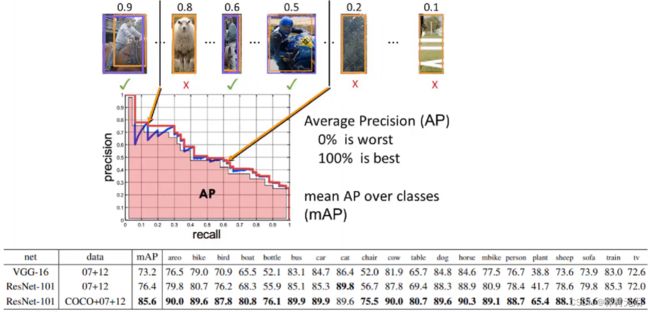
- 不同数据集对于AP和mAP的概念还是不同的


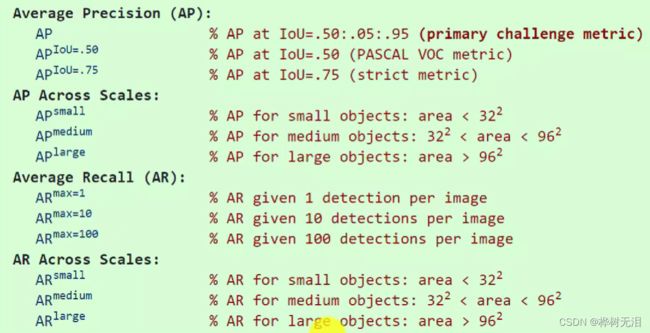
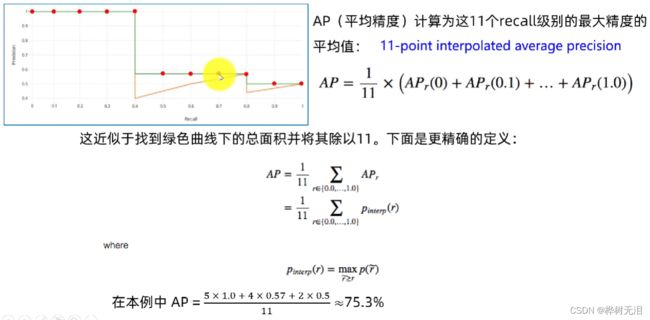
- AP计算
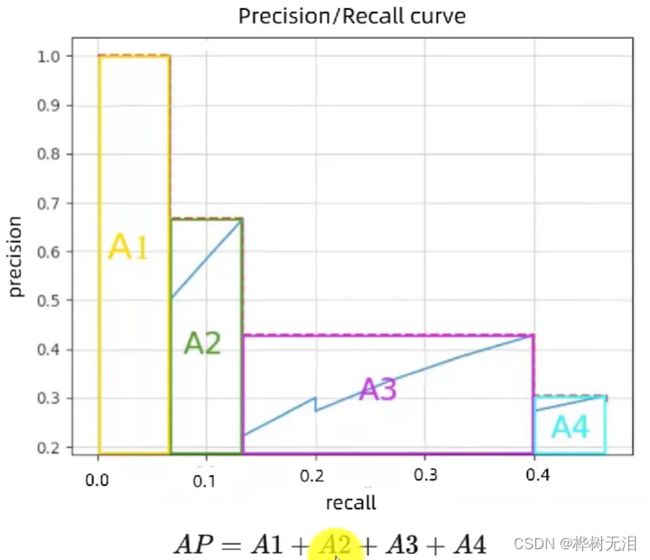
1.2.4 检测速度

1.3 YOLO发展史
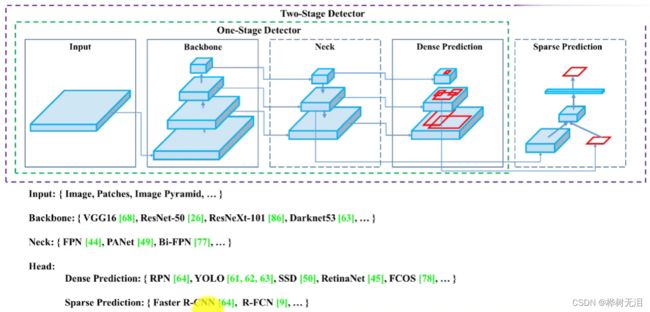 1.3.1 算法思想
1.3.1 算法思想
- yolov3框架图
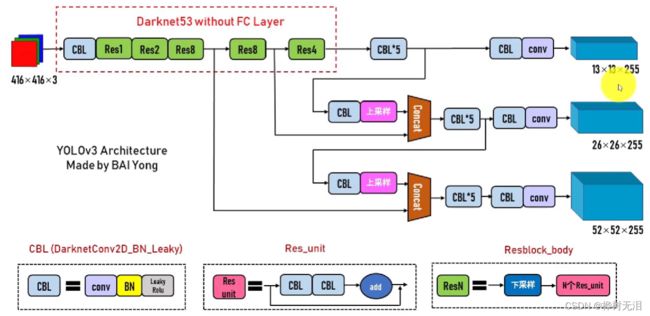
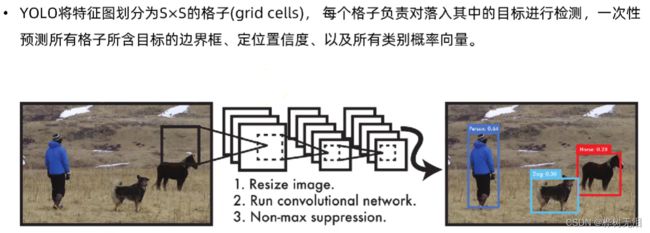
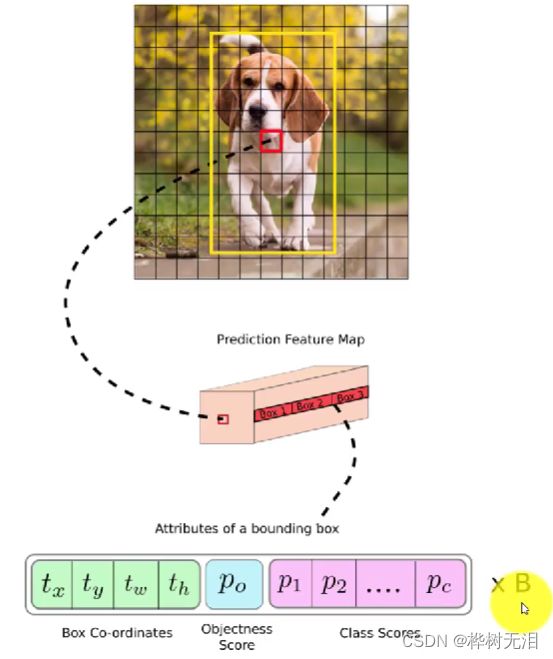
先经过卷积神经网络得到特征图像,之后对图像进行网格划分,每个网格单独进行画框检测和类别的概率图,最终得到结果。
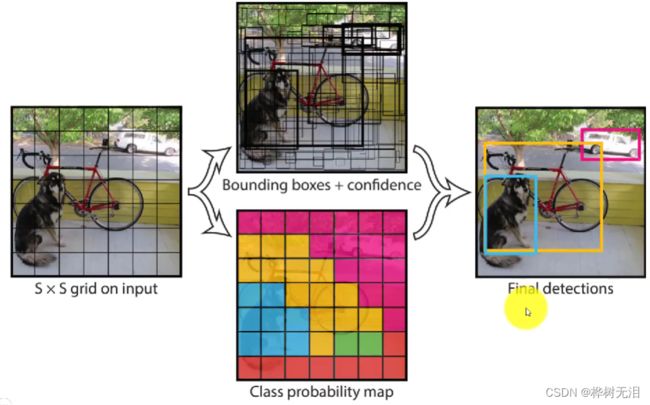
每个小框内包含了边界框坐标、目标得分和类别得分
- 多尺度融合
经过卷积神经网络可以得到不同大小的特征图,对不同大小的特征图进行融合利于小目标的检测。
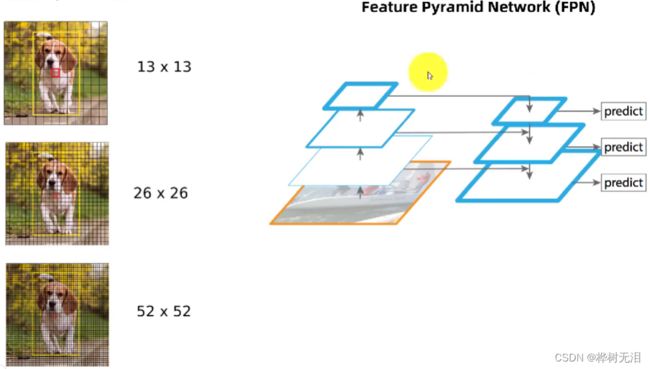
图片卷积经过32倍下采样得到19*19的图片,每个网格都会单独预测和画锚框

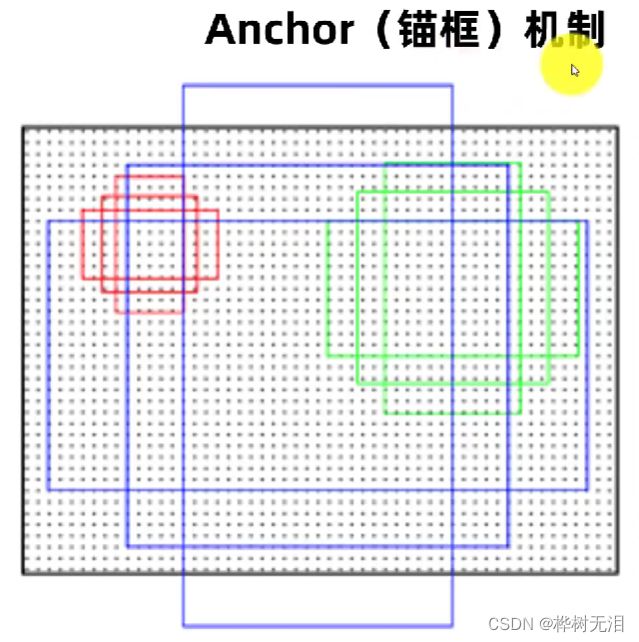
预先设定一些边界框的大小 ,每个尺度都有若干个锚框



- 损失函数

1.3.2 YOLOv5网络架构
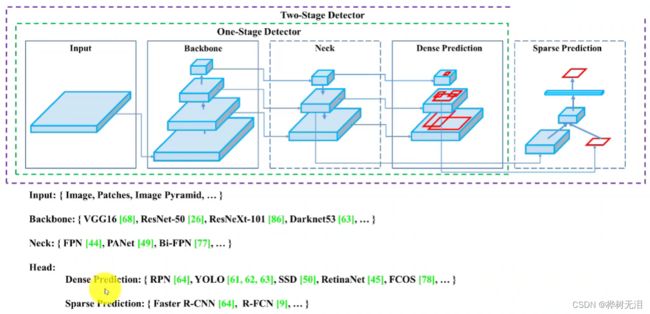
一个网络往往有主干网络(Backbone)+颈部(Neck)+头部(Head)组成

可视化


pip install onnx>=1.7.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install coremltools==4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
python models/export.py --weights weights/yolov5s.pt --img 640 --batch 1
yaml文件
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple 控制模型的深度用来控制模型的深度,仅在number≠1时启用。 如第一个c3层(c3具体是什么后续介绍)的参数设置为[-1, 3, c3, [128]],其中number=3,表示在v5s中含有1个c3(3*0.33)
width_multiple: 0.50 # layer channel multiple 用来控制模型的宽度,主要作用于args中的ch_out。如第一个conv层,ch_out=64,那么在v5s实际运算过程中,会将卷积过程中的卷积核设为64x0.5,所以会输出32通道的特征图。
#通过这两个参数可以不同的模型设计
#边界框的设置
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
#from:当前模块输入来自那一层的输出,-1代表从上一层获得
#number: 代表本模块重复的次数
#model:表示网络模块的名称,具体细节可以在./models/common.py查看,如conv、c3、sppf都是已经在common中定义好的模块
#args:表示向不同模块内传递的参数
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 #64代表通道数,3表示3*3的卷积核,2代表步长为2,2表示分两组卷积
#input:3x640x640
#[ch_out, kernel, stride, padding]=[64, 6, 2, 2]
#故新的通道数为64x0.5=32
#根据特征图计算公式:feature_new=(feature_old-kernel+2xpadding)/stride+1可得:
#新的特征图尺寸为:feature_new=(640-6+2x2)/2+1=320
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
#sspf模块将经过cbs的x、一次池化后的y1、两次池化后的y2和3次池化后的self.m(y2)先进行拼接,然后再cbs提取特征。 仔细观察不难发现,虽然sspf对特征图进行了多次池化,但是特征图尺寸并未发生变化,通道数更不会变化,所以后续的4个输出能够在channel维度进行融合。这一模块的主要作用是对高层特征进行提取并融合,在融合的过程中作者多次运用最大池化,尽可能多的去提取高层次的语义特征。
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]通过底层源码理解YOLOv5的Backbone_Python_萬仟网
yolo的不同网络大小仅仅改变这两个参数
