YOLOv3 物体识别显示中文标签
问题
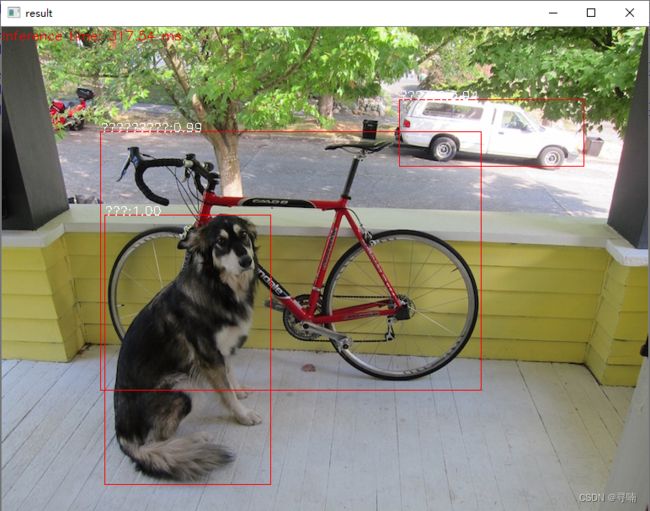
最近在做yolov3识别物体,想着把coco.name修改为中文,从而实现显示中文标签,结果发现,emmmm,显示出来是????????就是下面这个鬼样子
之前的代码是这样子的:
import cv2
cv=cv2
import numpy as np
import time
net = cv2.dnn.readNetFromDarknet("yolov3/yolov3.cfg", "yolov3/yolov3.weights")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
confThreshold = 0.5 #Confidence threshold
nmsThreshold = 0.4 #Non-maximum suppression threshold
frame=cv2.imread("dog.jpg")
classesFile = "coco.names";
classes = None
with open(classesFile, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
def getOutputsNames(net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
print(getOutputsNames(net))
# Remove the bounding boxes with low confidence using non-maxima suppression
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
classIds = []
confidences = []
boxes = []
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
classIds = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
print(boxes)
print(confidences)
indices = cv.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
#print(i)
i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
# Draw the predicted bounding box
def drawPred(classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv.rectangle(frame, (left, top), (right, bottom), (0, 0, 255))
label = '%.2f' % conf
# Get the label for the class name and its confidence
if classes:
assert(classId < len(classes))
label = '%s:%s' % (classes[classId], label)
print(label)
#Display the label at the top of the bounding box
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255))
blob = cv2.dnn.blobFromImage(frame, 1/255, (416, 416), [0,0,0], 1, crop=False)
t1=time.time()
net.setInput(blob)
outs = net.forward(getOutputsNames(net))
print(time.time()-t1)
postprocess(frame, outs)
t, _ = net.getPerfProfile()
label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
cv.putText(frame, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255))
cv2.imshow("result",frame)
`# 解决方案
于是网上开始寻找解决方案,最后发现,这位博主的解决方案最好,博客为:https://blog.csdn.net/hijacklei/article/details/116010860
我们在这个博客中下载语言包,之后将这个语言包直接放在你的py文件同路径下即可,原博说需要解压这个语言包文件,亲测不需要解压也可以。之后修改我们的drawPred()函数中的cv.putText()为cv2AddChineseText(),并在代码中新增自己封装的cv2AddChineseText(),修改之后的代码如下:
import cv2
cv=cv2
import numpy as np
import time
from PIL import Image, ImageDraw, ImageFont
net = cv2.dnn.readNetFromDarknet("yolov3/yolov3.cfg", "yolov3/yolov3.weights")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
confThreshold = 0.5 #Confidence threshold
nmsThreshold = 0.4 #Non-maximum suppression threshold
frame=cv2.imread("dog.jpg")
classesFile = "coco_ch.names";
classes = None
with open(classesFile, 'rt',encoding = 'utf-8') as f:
classes = f.read().rstrip('\n').split('\n')
def getOutputsNames(net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
print(getOutputsNames(net))
# Remove the bounding boxes with low confidence using non-maxima suppression
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
classIds = []
confidences = []
boxes = []
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
classIds = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
## print(boxes)
## print(confidences)
indices = cv.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
img0 = frame
for i in indices:
#print(i)
i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
img0= drawPred(img0,classIds[i], confidences[i], left, top, left + width, top + height)
return img0
# Draw the predicted bounding box
def drawPred(frame, classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv.rectangle(frame, (left, top), (right, bottom), (0, 0, 255))
label = '%.2f' % conf
# Get the label for the class name and its confidence
if classes:
assert(classId < len(classes))
label = '%s:%s' % (classes[classId], label)
print(label)
#Display the label at the top of the bounding box
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
img_text = cv2AddChineseText(frame, label, (left, top-20), textColor=(0, 255, 0), textSize=20)
## cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255))
return img_text
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype(
"simsun.ttc", textSize, encoding="utf-8")
# 绘制文本
draw.text(position, text, textColor, font=fontStyle)
# 转换回OpenCV格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
blob = cv2.dnn.blobFromImage(frame, 1/255, (416, 416), [0,0,0], 1, crop=False)
t1=time.time()
net.setInput(blob)
outs = net.forward(getOutputsNames(net))
print(time.time()-t1)
img = postprocess(frame, outs)
t, _ = net.getPerfProfile()
label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
cv.putText(img, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255))
##cv2.imshow("result",frame)
cv2.imshow("result",img)
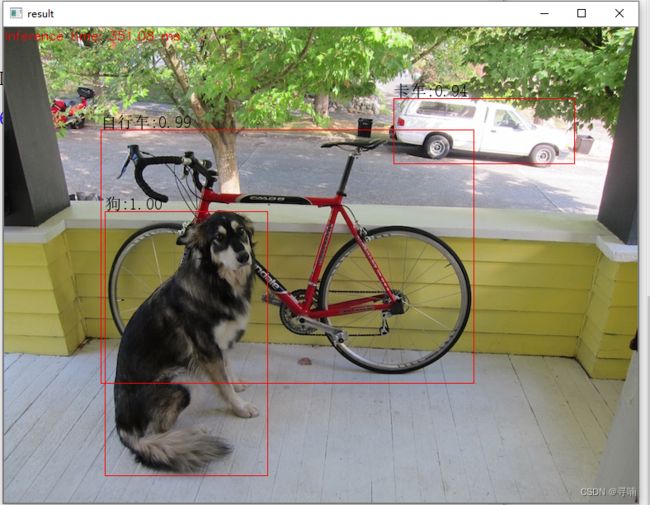
demo中用来检测的图片如下:

中午版本的coco_ch.name内容如下:
人
自行车
汽车
摩托车
飞机
公交车
火车
卡车
船
红绿灯
消防栓
停止标志
停车收费表
长凳
鸟
猫
狗
马
羊
牛
象
熊
斑马
长颈鹿
背包
雨伞
手提包
领带
手提箱
飞盘
滑雪板
单板滑雪
运动球
风筝
棒球棒
棒球手套
滑板
冲浪板
网球拍
瓶子
红酒杯
杯子
叉子
刀
勺
碗
香蕉
苹果
三明治
橙子
西兰花
胡萝卜
热狗
比萨
甜甜圈
蛋糕
椅子
长椅
盆栽
床
餐桌
马桶
电视
笔记本电脑
鼠标
遥控器
键盘
手机
微波炉
烤箱
烤面包机
洗碗槽
冰箱
书
时钟
花瓶
剪刀
泰迪熊
吹风机
牙刷
复制到coco_ch.name即可
成功识别并标记的结果如下: