文本张量的表示方法
概念:
- 将一段文本使用张量进行表示,将词汇表示成向量,成为词向量,再由各个词向量按顺序组成矩阵形成文本表示。
为什么?
- 因为文本不能够直接被模型计算,所以需要将其转化为向量
作用:
- 将文本转化为张量表示形式,能够将文本作为计算机程序的输入,然后进行下一步一系列的操作。
把文本转化为向量有两种方法:
-
one-hot编码
-
word2vec
-
word embedding
1. one-hot 编码 【使用稀疏的向量表示文本,占用空间多】
又称为独热编码,将每个词表示成具有n个元素的向量,这个向量只有一个元素是1,其余的元素都是0,不同词汇的1和0的位置是不同的,其中n的大小是整个语料中不同词汇的总数。
即:把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典,例如有一个文档:深度学习,那么进行one-hot处理后的结果如下:
| token | one-hot encoding |
|---|---|
| 深 | 1000 |
| 度 | 0100 |
| 学 | 0010 |
| 习 | 0001 |
one-hot编码实现:
# 导入用于对象保存与加载的joblib
import joblib
# 导入keras中的词汇映射器Tokenizer
from keras.preprocessing.text import Tokenizer
# 假定vocab为语料集所有不同词汇集合
vocab = {"张三", "李四", "王五", "赵六", "孙七"}
# 实例化一个词汇映射器对象
t = Tokenizer(num_words=None, char_level=False)
# 使用映射器拟合现有文本数据
t.fit_on_texts(vocab)
for token in vocab:
zero_list = [0] * len(vocab)
# 使用映射器转化现有文本数据, 每个词汇对应从1开始的自然数
# 返回样式如: [[2]], 取出其中的数字需要使用[0][0]
token_index = t.texts_to_sequences([token])[0][0] - 1
zero_list[token_index] = 1
print(token, "的one-hot编码是:", zero_list)
# 使用joblib工具保存映射器, 以便之后使用
tokenizer_path = "./Tokenizer"
joblib.dump(t, tokenizer_path)输出结果:
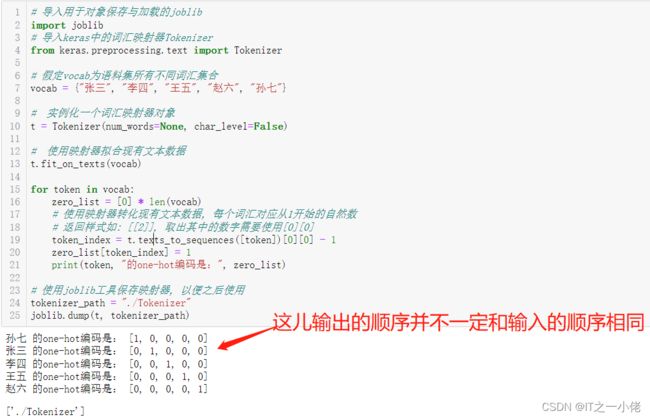
one-hot编码的使用:
# 导入用于对象保存与加载的joblib
import joblib
# 加载之前保存的Tokenizer, 实例化一个t对象
t = joblib.load(tokenizer_path)
# 编码token为“李四”
token = '李四'
# 使用t获得token_index
token_index = t.texts_to_sequences([token])[0][0] - 1
print(token_index)
# 初始化一个zero_list
zero_list = [0] * len(vocab)
# 令zero_list的对应索引为1
zero_list[token_index] = 1
print(token, '的one-hot编码是:', zero_list)运行效果:

one-hot编码的优劣势:
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
2. word2vec
将词汇表示成向量的无监督训练方法,将构建神经网络模型,将网络参数作为词汇的向量表示,它包含CBOW和Skipgram两种训练方式。
CBOW(Continuous bag of words)模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.

- 图中窗口大小为9, 使用前后4个词汇对目标词汇进行预测.
CBOW模式下的word2vec过程说明:
假设给定的训练语料只有一句话: Hope can set you free ,窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1).

接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代.

最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
skipgram模式
给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.

图中窗口大小为9, 使用目标词汇对前后四个词汇进行预测.
skipgram模式下的word2vec过程说明:
假设给定的训练语料只有一句话: Hope can set you free ,窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是skipgram模式,所以将使用can作为输入 ,Hope和set作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1).
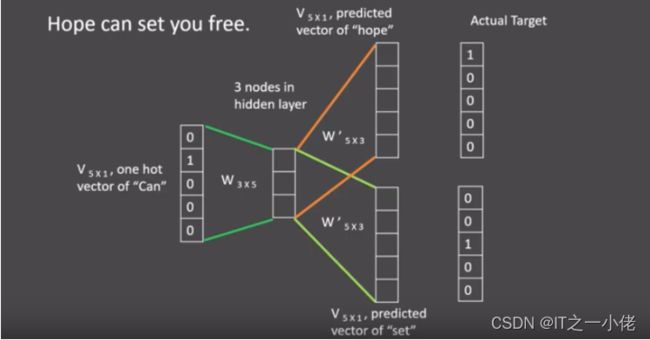
接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代.
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
第一步: 获取训练数据
# 获取烹饪相关的数据集, 它是由facebook AI实验室提供的演示数据集
# 首先创建一个存储数据的文件夹data
$ mkdir data
# 使用wget下载数据, 存储在data目录中
$ wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz -P data
# 解压data目录中的数据
$ tar xvzf ./data/cooking.stackexchange.tar.gz
查看数据的前10条:
$ head cooking.stackexchange.txt 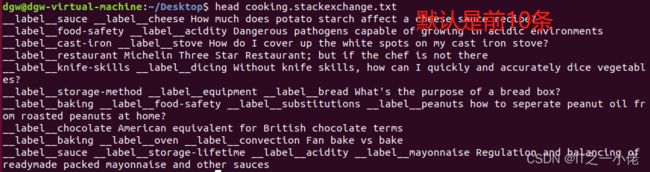

数据说明:
cooking.stackexchange.txt中的每一行都包含一个标签列表,后跟相应的文档, 标签列表以类似 "__label__sauce __label__cheese"的形式展现, 代表有两个标签sauce和cheese, 所有标签__label__均以前缀开头,这是fastText识别标签或单词的方式. 标签之后的一段话就是文本信息.如: How much does potato starch affect a cheese sauce recipe?
第二步: 训练集与验证集的划分:
# 查看数据总数
$ wc cooking.stackexchange.txt ![]()
# 12404条数据作为训练数据
$ head -n 12404 cooking.stackexchange.txt > cooking.train
# 3000条数据作为验证数据
$ tail -n 3000 cooking.stackexchange.txt > cooking.valid![]()
第三步: 训练词向量:
import fasttext
# 使用fasttext的train_supervised方法进行文本分类模型的训练
# 它的参数是数据集的持久化文件路径'../data/nlp/composition.txt'
model = fasttext.train_unsupervised('../data/nlp/cooking.train')
model# 通过get_word_vector方法来获得指定词汇的词向量
model.get_word_vector('We')
第四步: 模型超参数设定:
# 在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如:
# 无监督训练模式: 'skipgram' 或者 'cbow', 默认为'skipgram', 在实践中,skipgram模式在利用子词方面比cbow更好.
# 词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大.
# 数据循环次数epoch: 默认为5, 但当你的数据集足够大, 可能不需要那么多次.
# 学习率lr: 默认为0.05, 根据经验, 建议选择[0.01,1]范围内.
# 使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同.
model = fasttext.train_unsupervised('../data/nlp/cooking.train', "cbow", dim=300, epoch=1, lr=0.1, thread=8)
model# 通过get_word_vector方法来获得指定词汇的词向量
model.get_word_vector('We')array([ 1.8798960e-04, 3.9608974e-04, 1.2488964e-04, -9.2796411e-04,
-6.1711291e-04, -6.2431244e-04, -1.4772391e-04, -3.5378849e-04,
-3.0792586e-04, 5.1501358e-04, 1.6098269e-03, 1.0018016e-03,
1.6719052e-03, -5.6049239e-04, 7.6037890e-04, 6.1507529e-04,
-1.8648471e-03, -7.2232017e-04, -2.7811489e-04, -4.6330268e-04,
-9.9416811e-04, -2.8092955e-04, -9.3677954e-06, 1.6349037e-03,
4.3381727e-04, -6.1742309e-04, 9.5424021e-04, -3.5220262e-04,
-2.4382970e-03, -1.9431422e-03, -6.0295616e-04, 6.0434028e-05,
5.1125861e-04, 2.8696796e-04, -3.2288337e-04, -1.0013091e-03,
-1.0437337e-03, -8.3238486e-04, -4.9110944e-04, 1.1270840e-03,
8.6425280e-04, -1.9255802e-03, -1.9251168e-03, -1.6462419e-03,
-1.8576446e-03, 7.5667788e-04, 6.6057773e-04, -6.5994063e-05,
-1.6498434e-03, -2.5676386e-04, -4.6431762e-04, 3.8234689e-04,
-6.8796007e-04, 1.0940077e-03, -2.7840986e-04, -3.9451220e-04,
1.7935492e-03, 4.8564124e-04, -2.9137146e-04, 1.9880496e-03,
2.9593395e-04, 7.1078213e-04, -5.0951108e-05, -2.1633005e-04,
-5.9387996e-04, 1.3559591e-05, 4.3469830e-04, -1.5066195e-03,
8.5074385e-04, -1.6271046e-03, -2.6409666e-04, 1.3218648e-03,
-7.4308616e-04, 1.0227414e-03, -1.6490914e-03, -6.4410793e-04,
6.9497466e-05, 3.5593982e-04, 2.6490851e-03, -5.3268351e-04,
1.2321163e-03, 1.0681837e-03, -4.7990127e-04, 3.8721034e-04,
9.9227787e-04, -5.4918707e-04, -1.4470376e-03, 1.2126429e-03,
-4.3907342e-04, -3.9304476e-04, -6.5747555e-04, 3.0149959e-04,
5.4582942e-04, -5.9078913e-04, -2.3132609e-03, -2.2930815e-03,
2.5756651e-04, -4.4075365e-04, -1.6666949e-05, 1.4334652e-03,
1.7858138e-03, 2.2278397e-04, 9.0640283e-04, 3.0442880e-04,
1.3243086e-03, -7.0690678e-04, -6.4097706e-04, 4.2106956e-05,
-5.3881318e-04, 2.0223754e-03, 8.1660668e-04, 9.3027781e-04,
8.9407474e-04, 7.0259813e-04, -1.0891645e-03, -1.5033981e-03,
1.2447413e-03, -5.1550893e-04, 7.8015483e-04, -1.8651132e-04,
-1.5457397e-03, 2.3224749e-04, -7.1424220e-05, 2.5053683e-05,
-5.3998549e-04, 2.8403290e-04, 7.0932624e-04, 1.0760939e-03,
9.5664262e-04, -1.2577500e-03, -1.3050484e-03, -9.9220476e-04,
-1.1326331e-03, -3.9973820e-04, 1.8455237e-03, -1.2213863e-03,
4.4848816e-04, 1.1577337e-04, -1.3397774e-04, -1.1544895e-03,
-2.4254384e-04, -1.1866910e-03, 9.7491080e-05, -1.5464274e-03,
-5.7074567e-04, -6.0549628e-05, 4.0644035e-04, -1.9360933e-03,
8.4747089e-04, 1.4777582e-03, -8.4022677e-04, 5.1099074e-04,
2.1948041e-04, -1.5321872e-03, 9.0355752e-05, -1.8932702e-04,
-8.6888927e-04, 3.4475196e-04, 1.1358424e-03, 5.9262745e-04,
1.4131053e-03, -6.2828342e-04, -2.0598862e-03, 3.5489188e-04,
-9.5051492e-04, 5.5754336e-04, 1.5305297e-04, -2.2592241e-04,
-1.2468253e-03, 2.1133265e-03, 2.0393701e-03, -7.5453354e-05,
2.2464308e-03, -2.7793306e-03, -2.7650670e-04, -5.6757347e-04,
-1.2623724e-03, 2.4185526e-04, -2.1872879e-04, -1.3029057e-03,
1.2648103e-03, -1.7081172e-04, -5.1090492e-06, 2.0209840e-03,
-4.6539324e-04, -4.3347658e-04, 2.6551257e-03, -4.7769718e-05,
-1.5018480e-03, -2.7433509e-04, -1.1514550e-03, -9.0617285e-04,
6.4340071e-05, -1.4025187e-04, 1.6628280e-03, -2.0780518e-04,
1.2190402e-03, -5.0332031e-04, 9.3403400e-04, -2.3752507e-03,
-1.6558596e-03, -2.7870771e-04, -5.1363997e-05, -3.8631755e-04,
-1.2252243e-03, -8.8181972e-05, -8.7797281e-04, 4.6918890e-04,
2.8892321e-04, -3.6389800e-05, -3.7714560e-04, 1.6713038e-03,
-6.1489409e-06, -9.9299802e-04, 2.9321382e-04, 3.4070999e-04,
-9.1769427e-05, 4.3389792e-04, 2.8307032e-04, 1.8194178e-03,
-2.1896229e-04, -8.7369949e-04, 1.1310980e-03, 2.5185114e-03,
-2.8928742e-05, 3.6371639e-05, -3.4053749e-04, -1.3872653e-03,
1.9170906e-03, -1.9865986e-03, 2.5991439e-03, 7.5947837e-04,
4.3592113e-04, 6.6652254e-04, -2.0494119e-04, -9.2760939e-04,
-1.5355994e-04, -9.6773081e-05, -4.9556443e-04, 1.1428313e-03,
1.4962892e-03, 1.0212720e-03, -3.8397498e-05, 5.6903791e-05,
-5.9897255e-04, -2.0230697e-03, -1.7971732e-05, -2.3715696e-04,
-7.2849606e-04, -9.0493623e-04, 7.3953054e-04, -1.4050563e-03,
-1.4323555e-03, -4.4240867e-04, 5.6989986e-04, 2.5848616e-03,
4.2838976e-04, -6.8223989e-04, -6.6442939e-05, 6.2906457e-04,
-1.3130277e-03, -2.7790554e-03, 3.0586561e-05, -8.8957418e-04,
-7.8230907e-05, 9.6563809e-04, -8.4480271e-04, 1.8562011e-03,
4.5768984e-04, -9.2681765e-04, 5.0427485e-04, 1.6942159e-03,
-2.4133138e-04, 1.6701745e-04, -8.1996943e-05, 1.8672661e-04,
-3.0396209e-04, -1.5319184e-03, 6.3104037e-04, 3.0288688e-04,
9.7920932e-04, 1.0130615e-03, -6.8494043e-04, -1.3638380e-03,
1.4863213e-03, 9.4224850e-04, 7.5208559e-04, -3.8108899e-04,
-9.1517594e-04, 1.0825705e-03, -6.2862772e-04, -7.2933477e-04,
-1.1180628e-03, 7.0936600e-04, -6.9769856e-04, 1.8013072e-03,
1.9647011e-03, -2.0243833e-03, -1.0390377e-03, 7.8340177e-04],
dtype=float32)第五步: 模型保存与加载:
# 使用save_model保存模型
model.save_model("../data/nlp/cooking.train.bin")
# 使用fasttext.load_model加载模型
model = fasttext.load_model("../data/nlp/cooking.train.bin")
model.get_word_vector("We")3. word embedding
word embedding是深度学习中表示文本常用的一种方法。和one-hot编码不同,word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同的维度,例如100,256,300等。其中向量中的每一个值是一个参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
如果文本中有20000个词语,如果使用one-hot编码,那么我们会有20000*20000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000* 维度,比如20000*300
形象的表示就是:
| token | num | vector |
|---|---|---|
| 词1 | 0 | [w11,w12,w13...w1N] ,其中N表示维度(dimension) |
| 词2 | 1 | [w21,w22,w23...w2N] |
| 词3 | 2 | [w31,w23,w33...w3N] |
| ... | …. | ... |
| 词m | m | [wm1,wm2,wm3...wmN],其中m表示词典的大小 |
我们会把所有的文本转化为向量,把句子用向量来表示
但是在这中间,我们会先把token使用数字来表示,再把数字使用向量来表示。
即:token---> num ---->vector

3.1 word embedding API
torch.nn.Embedding(num_embeddings,embedding_dim)
参数介绍:
-
num_embeddings:词典的大小 -
embedding_dim:embedding的维度
使用方法:
embedding = nn.Embedding(vocab_size,300) #实例化
input_embeded = embedding(input) #进行embedding的操作 # input传入的只能是数字,字符串无法操作3.2数据的形状变化
思考:每个batch中的每个句子有10个词语,经过形状为[20,4]的Word emebedding之后,原来的句子会变成什么形状?
每个词语用长度为4的向量表示,所以,最终句子会变为[batch_size,10,4]的形状。
增加了一个维度,这个维度是embedding的dim