清华学霸告诉你:如何自学人工智能?
最近不少同学跃跃欲试,想投入 AI 的怀抱,但苦于不知如何下手。其中,人工智能的核心就是机器学习(Machine Learning),它是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。
我们今天就来分享一篇来自 EliteDataScience 上专门讲给机器学习入门自学者的教程,一步步教你如何从基础小白进阶为 ML 大拿。快上车吧,别找硬币了,这趟车不要钱!

你是否正在准备自学机器学习,但又不知道怎么去学?
今天我们在这篇文章里就教你怎样免费获得世界级的机器学习教育,你既不需要有博士学位,也不必是技术大牛。不管你是想成为数据科学家还是在开发中使用机器学习算法,其实你都能比想象中更快地学习和应用机器学习。
本文告诉你在机器学习之路上的几个步骤,保你不会迷路,下面开始我们的表演。
第一步:先搞懂什么是机器学习
在闷头学习机器学习之前,最好先把什么是机器学习搞清楚,了解机器学习的基本概念。
简单来说,机器学习就是教电脑怎样从数据中学习,然后做出决策或预测。对于真正的机器学习来说,电脑必须在没有明确编程的情况下能够学习识别模型。
机器学习属于计算机科学与统计学的交叉学科,在多个领域会以不同的面目出现,比如你应该听过这些名词:数据科学、大数据、人工智能、预测型分析、计算机统计、数据挖掘······
虽然机器学习和这些领域有很多重叠的地方,但也不能将它们混淆。例如,机器学习是数据科学中的一种工具,也能用于处理大数据。
机器学习自身也分为多个类型,比如监督式学习、非监督式学习、增强学习等等。例如:
邮件运营商将垃圾广告信息分类至垃圾箱,应用的是机器学习中的监督式学习;电商公司通过分析消费数据将消费者进行分类,应用的是机器学习中的非监督式学习;而无人驾驶汽车中的电脑合摄像头与道路及其它车辆交互、学习如何导航,就是用到了增强学习。
想了解机器学习的入门知识,可以看看一些网络课程。对于想对机器学习领域的重点慨念有个基础的了解的人来说,吴恩达教授的机器学习入门课程绝对必看。
以及“无人车之父” Sebastian Thrun 的《机器学习入门》课程,对机器学习进行了详细介绍,并辅以大量的编程操作帮助你巩固所学内容。
大概了解机器学习后,我们就来到知识准备阶段了。
第二步:预备知识
如果没有基本的知识储备,机器学习的确看起来很吓人。要学习机器学习,你不必是专业的数学人才,或者程序员大牛,但你确实需要掌握这些方面的核心技能。
好消息是,一旦完成预备知识,剩下的部分就相当容易啦。实际上,机器学习基本就是将统计学和计算机科学中的概念应用在数据上。
这一步的基本任务就是保证自己在编程和统计学知识上别掉队。
2-1:用于数据科学中的Python编程
如果不懂编程,是没法使用机器学习的。幸好,这里有份免费教程,教你如何学习应用于数据科学中的Python语言。(文末有获取方式)
2-2:用于数据科学的统计学知识
了解统计学知识,特别是贝叶斯概率,对于许多机器学习算法来说都是基本的要求。
2-3:需要学习的数学知识
研究机器学习算法需要一定的线性代数和多元微积分知识作为基础。
第三步:开启“海绵模式”,学习尽可能多的原理知识
所谓“海绵模式”,就是像海绵吸水一样,尽可能多地吸收机器学习的原理和知识,这一步和第一步有些相似,但不同的是,第一步是对机器学习有个初步了解,而这一步是要掌握相关原理知识。
可能有些同学会想:我又不想做基础研究,干嘛要掌握这些原理,只要会用机器学习工具包不就行了吗?
有这个疑问也很正常,但是对于任何想将机器学习应用在工作中的人来说,学习机器学习的基础知识非常重要。比如你在应用机器学习中可能会遇到这些问题:
- 数据收集是个非常耗时耗力的过程。你需要考虑:我需要收集什么类型的数据?我需要多少数据?等此类的问题。
- 数据假设和预处理。不同的算法需要对输入数据进行不同的假设。我该怎样预处理我的数据?我的模型对缺失的数据可靠吗?
- 解释模型结果。说机器学习就是“黑箱”的观点明显是错误的。没错,不是所有的模型结果能直接判读,但你需要能够判断模型的状况,进而完善它们。我怎么确定模型是过度拟合还是不充分拟合?模型还有多少改进空间?
- 优化和调试模型。很少有人刚开始就得到一个最佳模型,你需要了解不同参数之间的细微差别和正则化方法。如果我的模型过度拟合,该怎么修正?我应该将几个模型组合在一起吗?
要想在机器学习研究中解答这些问题,掌握机器学习的知识原理必不可少。
这里推荐两部值得读的参考书籍:《统计学习导论》和《统计学习基础》
第四步:针对性实际练习
在开启“海绵模式”后,你应该掌握了机器学习的基础理念知识,接着就该实际操作了。 实际操作主要是通过具体的、深思熟虑的实践操作增强你的技能。本步目标有三个:
- 练习机器学习的整个流程:收集数据,预处理和清理数据,搭建模型,训练和调试模型,评估模型。
- 在真正的数据集上实践操作:对于什么样的数据适合用什么类型的模型,自己应逐渐建立这方面的判断能力。
- 深度探究:例如在上一步,你学习了很多机器学习算法知识,在这一步就要将不同类型的算法应用在数据集中,看看哪个效果最好。
完成这一步后,就可以进行更大规模的项目了。
4-1 九个基本部分
机器学习是一个非常广泛和丰富的领域,几乎在每个行业都有应用。因为要学习的东西太多,初学者很容易发慌,而且在面对很多个模型时也很容易迷失,看不到大局。
因此,我们把机器学习大概划分为九个部分:
ML整体学习:
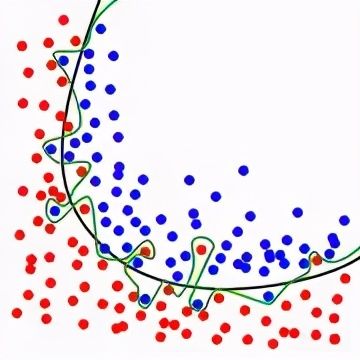
基本的机器学习原理,比如方差权衡这些知识。
优化:

为模型发现最优参数的算法。
数据预处理:

处理缺失数据、偏态分布、异常值等。
取样和拆分:
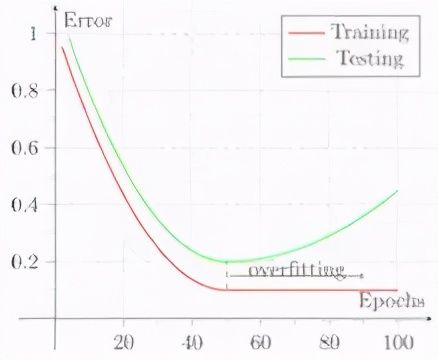
怎样拆分数据集来调整参数和避免过度拟合。
监督式学习:
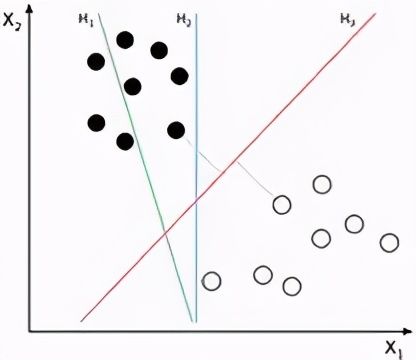
使用分类和回归模型从标记数据中学习。
非监督式学习

使用因素和集群分析模型从非标记数据中学习。
模型评估

根据不同的性能度量做出决策。
集成学习

将不同模型相结合,达到更好的性能。
商业应用

机器学习如何帮助不同类型的商业业务。
4-2 实践工具
对于初学者,我们建议采用现成可用的算法,这样可以把时间用在熟悉机器学习流程上,而不是写算法。根据你使用的编程语言,有两个不错的工具:
Python的Scikit-Learn
R语言的Caret
4-3 利用数据集实践操作
在这步需要用数据集进行搭建和调试模型的实际操作,也就是将你在“海绵模式”阶段学到的理论转变为代码。我们建议你选择UCI Machine Learning Repo,Kaggle和Data.gov上的数据集开始入手:
UCI Machine Learning Repo
Kaggle数据集
DataGov数据集
第五步:机器学习项目
终于到了最后一步,也是很有意思的一步。目前为止,我们已经完成了:知识储备、掌握基本原理、针对性练习等阶段,现在我们准备探究更大的项目:
这一步的目标就是练习将机器学习技术应用于完整的端到端分析。
任务:完成下面的项目,依次从易到难。
5-1:“泰坦尼克号”幸存者预测
“泰坦尼克号”幸存者预测是练习机器学习时相当流行的选择,而且有非常多的教程可供参考。
5-2 从零开始写算法
我们建议你先以一些简单的方面写起:逻辑回归、决策树、k 最近邻算法等。
如果中间卡住了,这里有些小技巧可以参考:
- 维基百科是个不错的资源库,提供了一些常见算法的伪代码。
- 可以看看一些现成ML工具包的源代码,获得灵感。
- 将算法分为几部分。写出取样、梯度下降等的分离函数。
- 在开始写整个算法前,先写一个简单的决策树。
5-3 选个有趣的项目或自己感兴趣的领域
其实这应该是机器学习最棒的部分了,可以利用机器学习实现自己的想法。
结语
如果你按照这个步骤一步步扎实学习的话,相信你最终一定在机器学习方面小有成就!
我们对初学机器学习的人还有10个小小的tips:
- 为自己设定学习目标和期限,尽力完成。
- 打好学习基础,掌握基本理论。
- 将实践理论相结合,不要只关注某一个方面。
- 试着自己从头写几个算法。
- 多角度思考问题,找到自己感兴趣的实践项目。
- 多想想每个算法能产生什么价值。
- 不要相信科幻电影中对ML的胡吹。
- 别过度理会网上关于ML知识的争论。
- 多想想数据的“输入/输出”,多问问“为什么”。
- 上集智,第一时间将自己升级→→集智
最后,祝大家学有所成!
注:如果需要这些Python学习资料文档,麻烦各位看官帮忙转发一下,然后加V mss2998 领取!
