多任务学习原理与优化
文章目录
- 一、什么是多任务学习
- 二、为什么我们需要多任务学习
- 三、多任务学习模型演进
-
- Hard shared bottom 硬共享
- Soft shared bottom 软共享
- 软共享: MOE & MMOE
- 软共享: CGC & PLE
- 加入FM
- MMOE/PLE 的调参
- ESMM
- 四、 loss权重
-
- 1, 利用任务的不确定性作为loss权重 Using Uncertainty to Weigh Losses
- 2, 利用任务的训练学习难度来作为权重loss权重 Dynamic Task Prioritization
- 3, 梯度标准化 Gradient Normalization
- 4, Dynamic Weight Average
- 5, 帕累托最优 Pareto-Eficient
- 6, 优化多任务梯度 PCGrad
- 7, 交替训练 Alternative Training
- 五、线上分融合
-
- 1, 加乘法公式融合
- 2, 分数转化为序
- 3, 最优化离线搜参
- 4, learn to rank 搜参
- 六、其他
- 其他相关链接
一、什么是多任务学习
多任务学习是目前推荐算法领域一个比较流行常见的研究范围, 相比单模型或者单任务推荐算法, 比如推荐里面的CTR模型, 时长模型都是只优化提升点击率, 完播率。 多任务学习优化目标同时是多个指标,比如互动, 点击和时长, 因此多任务学习从业务上来说和业务需求息息相关,从技术上来说如何在训练时平衡多个任务如何在预测时融合三个任务学习成果是重中之重。
二、为什么我们需要多任务学习
- 业务上需要同时提高多个指标。
- 为了产品整体体验, 譬如只对点击进行优化的话 ,容易出现一些博眼球的物料吸引用户点击,但其实这些低质内容不利于整体留存, 因此加入收藏或者时长任务进行多任务学习提升用户体验。
- 主指标的label面临噪声大, 正样本比少的情况, 加入辅助任务进行多任务学习可以通过共享bottom layer学到相似的pattern来提升主任务指标。
- 多个任务共享一个模型,占用内存量减少, 多个任务一次前向计算得出结果,推理速度增加;
多任务学习除了本篇重点的深度模型外, 业界初始的简单的方法也可以先训练多个单模型, 然后进行线上分融合。 除此以外, 可以利用label定义和交叉熵公式上做文章, 比如说我们在优化点击模型时想增加物料质量吸引用户点赞, 那就在定义正样本时点击设为正样本 1, 并且当点击且有互动时在交叉熵损失函数正样本那项之前加一个权重。 这么做的意义第一是在反向推导时,这个权重也相当于在梯度上乘以一个权重加速下降,第二也可以看做是对正样本的一种增强扩大改变了正负样本比例。
通常对点击和时长同时建模时,因为时长是一个连续值, 还会使用不同曲线对时长进行reweight, 这里可以重点看下蘑菇街这篇文章蘑菇街首页推荐多目标优化之reweight实践:一把双刃剑?

通过改变label function的方式操作简单上线快速,但本质不是一种多模型建模的方法, 而是将不同的目标转化为同一个目标, 需要多次ab调整reweight参数, 本质上是一个帕累托寻找有效解的过程。
相关链接:
https://zhuanlan.zhihu.com/p/291406172
https://zhuanlan.zhihu.com/p/359275468
https://zhuanlan.zhihu.com/p/268359893
https://zhuanlan.zhihu.com/p/271858727
https://zhuanlan.zhihu.com/p/281434497
三、多任务学习模型演进
多任务学习深度模型主要分hard shared bottom和soft shared bottom, 都是通过共享底层网络然后到上层不同的任务塔组合而成, 其中hard shared bottom比较早期而且简单但是对任务相关性要求比较高, 而soft shared bottom 通过加入gate网络后演化出主流MMOE, PLE,CGC等模型
Hard shared bottom 硬共享
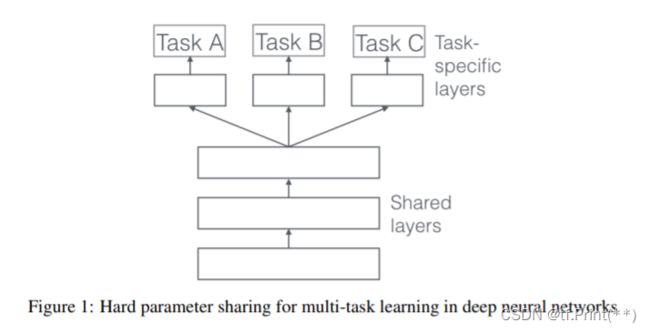
- 实现简单,特征进入共享DNN后再分别进入各个任务DNN塔。 但多任务共用隐层对各自影响大, 只有当各任务互相促进,学习才能好, 对于相关性较差任务很容易出现跷跷板现象。
Soft shared bottom 软共享

- 与硬参数共享相对的是软参数共享:每个任务都有特定的模型、参数;但对模型间的参数,使用距离正则化约束,保障参数空间的相似。
软共享: MOE & MMOE
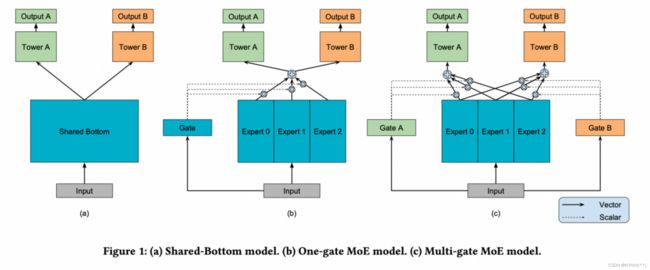
- 底层网络分成独立的expert网络, 上层任务塔由gate网络经expert网络进行差异化输出。
- 有几个任务就有几个gate网络, 但是专家网络与任务数无关。 每个任务塔的输入是所有expert的加权和, 权重由gate网络决定。
- 在任务相关性好的情况下, 所有多任务模型所有效果均较好;但MMoE > OMoE > Share-Bottom
- 当相关性不足时, MMoE > OMoE
软共享: CGC & PLE
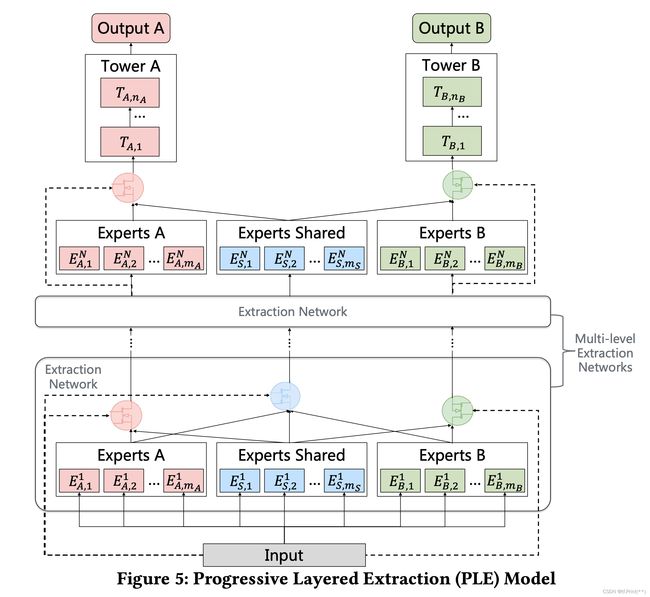
-
CGC和PLE是对MMOE模型的优化, MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声; 但是PLE和CGC每个任务有独立的Expert,同时保留了共享的Expert,增加了模型的复杂程度, 进一步缓解了多任务学习里面的跷跷板问题。
-
CGC和PLE的区别是PLE就是多层的CGC。 多层CGC同样带来了, 下层Expert和上层Expert的交互。
加入FM

除了上述主要多任务学习模型的迭代, 还有些小的模型优化改进, 比如在多目标排序模型在腾讯QQ看点推荐中的应用实践
类似DNN+FM 组成了DEEPFM,增强了一阶二阶特征的交叉,提升效果。
MMOE/PLE 的调参
多任务学习模型里主要可以调节的是专家网络的个数和gate网络的mlp隐藏层层数。
- 专家个数越多效果越好,但多到一定程度以后,提升幅度就不大了,而训练和在线预测的耗时会明显增加,所以需要平衡专家个数和效率来选择最佳专家个数
- 在我的场景里, 当gate网络由一层fc升级为3层fc(gate网络参数增大,expert网络参数减少)时效果有明显提升
ESMM
相关链接:
https://zhuanlan.zhihu.com/p/422925553
https://zhuanlan.zhihu.com/p/291406172
https://zhuanlan.zhihu.com/p/359275468
https://zhuanlan.zhihu.com/p/383891318
https://zhuanlan.zhihu.com/p/441117034
https://zhuanlan.zhihu.com/p/268359893
(讲了很多其他模型)
四、 loss权重
多任务学习中最重要的一点就是如何对于多个任务塔得到的loss进行合理的加和(下式), 首先不同人物的loss本身就有不同的量级, 量级差距过大可能造成训练的不平衡, 其次设置不同的权重加和会导致影响不同任务的训练速度和梯度, 可能会导致一个或多个任务在网络权重中占主导地位的情况。
对于loss权重, 可以进行手拍+离线在线评估进行搜参, 当然更多的是 各个论文和大厂从不同理论技术决定任务loss的动态权重。
Loss = w1 * l1 + w2 * l2 +w3 * l3(w1,w2,w3分别代表不同权重)
1, 利用任务的不确定性作为loss权重 Using Uncertainty to Weigh Losses
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
原文中回归问题中不确定性概率模型, 同方差不确定性或任务依赖不确定性是对同一任务的不同输入实例保持不变的量(quantity)。优化过程是maximize一个高斯似然目标,以考虑到同方差不确定性。
![]()
所有回归值落在预测值y方差sigma左右, 多个任务的回归概率如下图推倒, 最后引出公式7
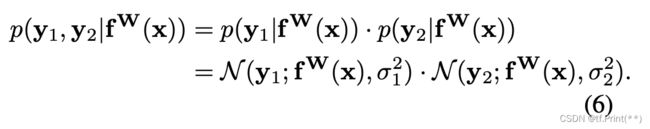
 对于分类问题, 原文给出下列公式, 但是由于我们的场景是二分类问题,这边sigmoid可以是softmax。 至于为什么 f(x) 要除以sigma的平方, 作者说这边sigma类比吉布斯分布/ 玻尔兹曼分布的温度, 解释的不是很清晰,我个人理解就是温度越高系统越不稳定, 类似方差越大, 不确定性也大。
对于分类问题, 原文给出下列公式, 但是由于我们的场景是二分类问题,这边sigmoid可以是softmax。 至于为什么 f(x) 要除以sigma的平方, 作者说这边sigma类比吉布斯分布/ 玻尔兹曼分布的温度, 解释的不是很清晰,我个人理解就是温度越高系统越不稳定, 类似方差越大, 不确定性也大。
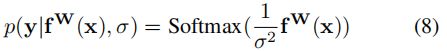
原文给出了一个回归任务一个分类任务 LOSS的最终公式
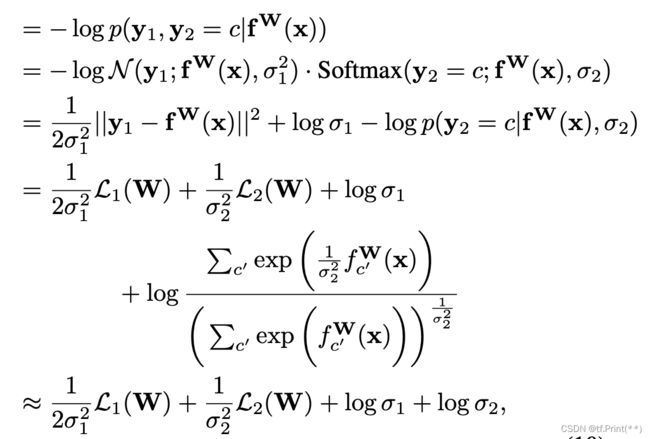
双分类问题uncertainty loss TensorFlow 代码实现
loss = tf.exp(-log_var_1)* loss_1 + tf.exp(-log_var_2)* loss_2 + log_var_1 + log_var_2
- 公式中对于分类问题, sigma之前的分母系数为1,因此我们置1。
- 为什么实现中使用e的log(方差),这是防止分母为0。
- log_var 初始值为设置为0.0
sigma这边原文提出来是一个可以学习的参数, 因此我们也将作为tf variable 一起训练。 其次 sigma不仅作为loss的权重, 它作为公式尾的一个系数, 也起到正则化的作用。
同时可以看到的是sigma作为一个噪音参数它的增大会减小相关任务的权重,因此,当任务的同方差不确定性较高时,任务对网络权重更新的影响较小。这在处理noisy label时是有利的,因为对于这类任务,task-specific权重会自动降低。
uncertainty方式适合处理噪音大的任务, 它代表着对于loss较大的task,意味着它的uncertainty(不确定性)也较高,为了避免模型往错误的方向“大步迈”,应该以较小的梯度去更新w;相反的,对于loss较小的task,它的uncertainty也就较低,以较大的梯度去更新w;
uncertainy方法希望给简单(噪音小)任务更高的权重。
应用案例:https://zhuanlan.zhihu.com/p/291406172
2, 利用任务的训练学习难度来作为权重loss权重 Dynamic Task Prioritization
《Dynamic task prioritization for multitask learning》
上面一种方法可以看到作者倾向于不确定性更小的任务主导训练(我理解为更容易的任务), 这也比较好理解, 让容易任务主导共享层, 难的任务能更直接获得共享知识。
但是李飞飞这篇文章不这么认同,《Dynamic task prioritization for multitask learning》
她觉得难的任务应该给予更高的权重, 先肯最硬的骨头。
所谓的难易,主要体现在kpi上, 也就是文中说的Kt, 这个值可以是acc也可以是auc。我在这里使用auc。
文中提出这里最终kpi要使用一个平滑表示, 这也比较好理解。 因此我这里将k设置为一个variable, 初始值为0.0, 每次传入后续function中进行迭代。
![]()
作者给出最终权重loss公式是 :
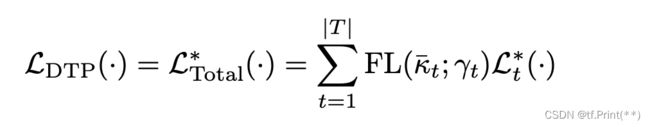
这其中使用了focal loss封装在kpi外面,作用是 focal loss给那些容易区分的样本更小的权重,使得在训练过程中,模型能更聚焦那些困难任务。
DTP loss 三分类问题的实现
# Dynamic Task Prioritization
def focal_loss_dtp(auc,k,alpha=0.95, gamma=2.0):
k = alpha * auc + (1-alpha) * k
return -tf.pow(1-k, gamma) * tf.log(k)
dtp_1 = focal_loss_dtp(auc_1[1], k_1)
dtp_2 = focal_loss_dtp(auc_2[1], k_2)
dtp_3 = focal_loss_dtp(auc_3[1], k_3)
loss = dtp_1 * loss_1 + dtp_2 * loss_2 + dtp_3 * loss_3
值得注意的是, DTP需要事先平衡损失值的整体大小, DTP没有考虑不同任务的loss的量级,需要额外的操作把各个任务的量级调整到差不多;且需要经常计算KPI。
Uncertainty loss 似乎可以适用于标签噪声更大的数据,希望简单任务主要多任务训练, 而DTP可能在干净的标注数据里效果更好, 希望难学的任务主要训练。
在我们的场景里,Uncertainty loss 添加后效果持平,而DTP loss反而使得实验结果降低了许多。
3, 梯度标准化 Gradient Normalization
《Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks》
-
梯度归一化(GradNorm)通过刺激任务特征梯度的大小相似来控制多任务网络的训练, 能自动平衡多task不同的梯度量级,保证梯度在一个量级。
-
总的Loss依旧是不同loss的权重, 但是额外设计了额外的loss来学习不同task loss的权重
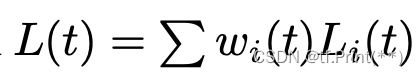
-
额外的Loss不参与网络层的参数的反向梯度更新,独立优化。 目的在于不同task的梯度通过正则化能够变成同样的量级,使不同task可以以接近的速度进行训练。
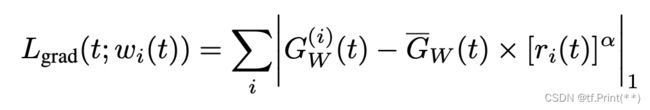
4, Dynamic Weight Average
《End-to-End Multi-Task Learning with Attention》
Dynamic Weight Average核心公式如下, 是通过计算前一轮迭代和后一轮迭代Loss之比算出loss下降的速率, loss缩小快的任务,则权重会变小;反之权重会变大。最终达到各个任务以相近的速度来进行学习。

和DTP一样这个策略需要平衡各个loss的量级。
5, 帕累托最优 Pareto-Eficient
A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation
https://zhuanlan.zhihu.com/p/456089764
帕累托最优是阿里2019年发表于RecSys上的一篇文章, 对比手动调节联合Loss,该论文使用kkt条件来负责各目标权重的生成。其总loss的定义仍然是所有task的loss加权平均,但这个权重是经过正则化(scalarization)的。相关工业应用可以参照爱奇艺这篇文章, 一矢多穿:多目标排序在爱奇艺短视频推荐中的应用
主要步骤:
- 均匀设置目标权重值(可更新的),同时设置权重边界值超参,运行PE-LTR算法在训练过程中不断更新权重值;
- 通过设置不同的权重边界值超参,多次运行训练任务,根据目标的重要性挑选效果最好的模型。
核心公式:
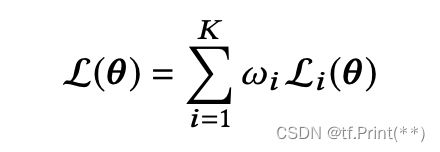
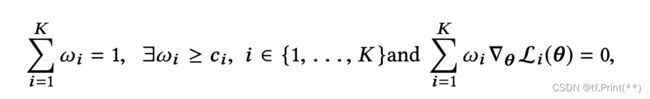
6, 优化多任务梯度 PCGrad
《Gradient Surgery for Multi-Task Learning》
https://zhuanlan.zhihu.com/p/422925553
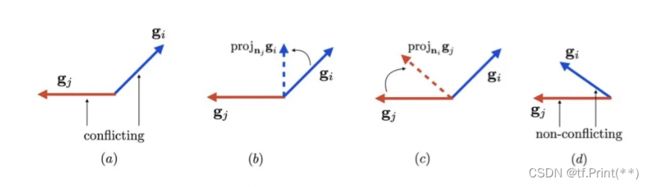
“在多任务训练期间,如果能知道具体的梯度就可以利用梯度来动态更新 w 。 如果两个任务的梯度存在冲突(即余弦相似度为负),将任务A 的梯度投影到任务B 梯度的法线上。即是消除任务梯度的冲突部分,减少任务间冲突。
首先通过计算 gi与 gj之间的余弦相似度来判断 gi是否与 gj 冲突;其中负值表示梯度冲突。
如果余弦相似度是负数,我们用它在 g的法线平面上的投影替换。如果梯度不冲突,即余弦相似度为非负,原始梯度gi保持不变。”
7, 交替训练 Alternative Training
这篇文章对于Loss融合的方式使用了交替训练 (https://zhuanlan.zhihu.com/p/291406172)

“Alternative Training在训练任务A时,不会影响任务B的Tower,同样训练任务B不会影响任务A的Tower,这样就避免了如果任务A的Loss降低到很小,训练任务B时影响任务A的Tower,以及学习率的影响。
Alternative Training比较适合在不同的数据集上输出多个目标,多个任务不使用相同的feature,比如WDL模型,Wide侧和Deep侧用的特征不一样,使用的就是Alternative Training,Wide侧用的是FTRL优化器,Deep侧用的是Adagrad或者Adam。”
train_op1 = tf.train.AdamOptimizer().minimize(loss1)
train_op2 = tf.train.AdamOptimizer().minimize(loss2)
final_train_op = tf.group(train_op1 train_op2)
相关链接:
https://zhuanlan.zhihu.com/p/456089764
https://zhuanlan.zhihu.com/p/355380682
https://zhuanlan.zhihu.com/p/269492239
https://zhuanlan.zhihu.com/p/291406172
https://zhuanlan.zhihu.com/p/422925553
https://www.yanxishe.com/columnDetail/26367
https://cloud.tencent.com/developer/news/783261
https://zhuanlan.zhihu.com/p/383891318
五、线上分融合
多任务学习在线上预测输出的时候是输出多个预测分,因此在排序时需要将这几个分数加权融合后得到一个分数, 但是因为每个预测分的分布不一样(和正负样本比有关),而且在具体业务中每个任务的重要性不一样, 因此在每个任务的分数融合权重需要经过一定方法的设定和计算。 下面介绍我认为的融合分权重设定三个方向,
1, 加乘法公式融合

- “最简单的融合方式就是按照上式进行加法和乘法的融合。通过 ai控制值域分布和中心点的偏移, bi表明该目标得分的提升比例。加法融合中,bi代表该目标得分的占比。不同的场景,各目标的重要性不同。通过设置目标不同的权重,调整各子目标的重要性级别,实现候选集中某目标样本的顺序提升。” (https://zhuanlan.zhihu.com/p/441117034)
- 加法融合的缺点是容易被某些最大的目标主导, 且随着项目的增多加法融合会逐步弱化各子目标的重要性影响。
- 而乘法融合具有一定的目标独立性,无需考虑旧目标集的值域分布, 但是容易收到预测值方差分布影响。
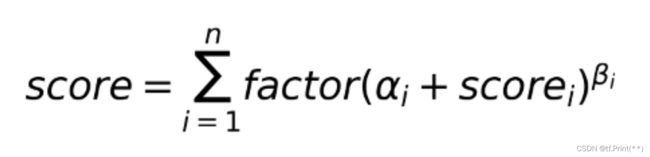

爱奇艺对加法乘法融合公式做了升级(https://zhuanlan.zhihu.com/p/383891318),如上述公式:
- 通过factor调节单目标整体的影响力。
- 通过beta基于预估分数调节单目标影响力,即融合公式对于不同用户是有一定个性化的。
- alpfa起到一定兜底作用,同时保证factor只调大单一目标权重,而不是作用于融合公式整体。
- 缺点是,加法形式特别容易被最大的目标主导。
2, 分数转化为序
上述第一种方式的参数大多数情况都是根据工程师手拍然后根据线上ab的反馈动态调整的, 来调整各个分数的量级和分布到一个固定一直的范围。
其实,我们可以把预测分归一化,转化为序, 这样的话使用下述最简单的线性加权就可以
具体地,把用户的个性化预估点赞率从小到大排序,把每个具体的值映射成它的序,再把序折合成一个分数,不同的序映射到不同的分数。 举个例子, 在工程引擎里, 每次对1000个样本进行排序,把他们从大到小映射到100个桶里, 落入相映的桶给 0.01 - 1.00的分数。 最后将这个转化为序的分数加上一定的业务权重求和起来。
3, 最优化离线搜参
无论上述第一种方式和第二种方式最前面的业务权重都是通过手拍+ 线上反馈得到的。 这里提出的最优化搜参, 是定义一个目标这个目标是又各个业务指标的AUC加权得到的, 我们要使得我们排序分融合后这个总的AUC最大。
![]()

上述第一张图中的a,b,c权重是我们动态调整需要求的参数, 下图wi是我们设定的固定的和业务指标有关的AUC权重,代表我们最整个业务AUC的不同需求。具体地说,搜参任务就是寻找一组参数,将各个子目标得分融合得到统一得分,依据此得分计算各子目标的 auci,使总的 AUC之和是最大。
大致的离线搜参步骤:
1, 取线上解作为baseline参数;
2, 从基础解出发,通过高斯分布产生邻域内的N组参数;(限制参数的试探区域,保持稳定,控制损失)
3, 用多组参数直接AB,实时计算收益,选择较好的top-k组参数;
4, 得到均值和方差,继续迭代2~3步骤。
参考:
常见的最优化搜参算法:粒子群算法, 遗传算法, grid search, 交叉熵算法(Cross-Entropy Method,CEM)、进化策略(Evolutionary Strategy,ES)、贝叶斯优化(Bayes Optimization)、高斯过程回归(Gaussian-Process Regression,GPR)
4, learn to rank 搜参
同样参照多目标排序在快手短视频推荐中的实践
首先根据业务需求设定一个label, 然后使用GBDT或者DNN来拟合这个目标,输入是多任务塔多个预测分, loss 是 加权logloss
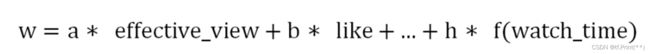
也可以直接端到端learn to rank 也就是说拟合的不再是各个任务点击,互动,时长而是他们的组合label。
相关链接:
https://zhuanlan.zhihu.com/p/441117034
https://zhuanlan.zhihu.com/p/383891318
https://zhuanlan.zhihu.com/p/500237779
https://mp.weixin.qq.com/s/mxlecZpxXEoOe21UY_UCXQ
六、其他
其他一些模型技巧:
1, user侧的序列特征里的id可以和item侧那边的id共享矩阵, 减少内存空间消耗, 避免算法在拉近序列特征id和item id空间距离花费太大代价。
2,加mid, uid, topicid等特征。
其他相关链接
https://zhuanlan.zhihu.com/p/291406172
https://zhuanlan.zhihu.com/p/359275468
https://zhuanlan.zhihu.com/p/422925553
https://zhuanlan.zhihu.com/p/441117034
https://zhuanlan.zhihu.com/p/268359893
https://www.infoq.cn/article/0xdvnhsha02egyr1qaax
https://www.yanxishe.com/columnDetail/26367
https://zhuanlan.zhihu.com/p/456089764
https://cloud.tencent.com/developer/news/783261
https://zhuanlan.zhihu.com/p/341345727
上面这篇重点看下
https://zhuanlan.zhihu.com/p/355380682
资料收集:
https://www.zhihu.com/question/359962155
https://zhuanlan.zhihu.com/p/269492239
https://zhuanlan.zhihu.com/p/56613537
论文:
1, 用uncertainty决定loss权重:
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
2, 用帕累托最优决定loss权重
Multi-Task Learning as Multi-Objective Optimization
3, 总结文
Multi-Task Learning for Dense Prediction Tasks: A Survey
代码更新检查:
看focal_loss作用:
评估指标:
用uncertainty先试一下
调整三塔不同的学习率
Uncertainty:
Pytorch keras两段代码看完了,都是做了一个multi loss layer, 按照公式把log_var加进去了
对照公式再看一下, 然后他这都是回归问题,怎么做分类问题
https://github.com/hardianlawi/MTL-Homoscedastic-Uncertainty
https://ruder.io/multi-task/
http://liuxiao.org/2020/07/multi-task-learning-using-uncertainty-to-weigh-losses-for-scene-geometry-and-semantics/
因此,

越大,任务的不确定性越大,则任务的权重越小,即噪声大且难学的任务权重会变小。
2-3和2-4的两个loss函数似乎存在在某种程度上是对立的。在2-3中,文章希望对于“难学”的任务给予更高的权重;而在2-4中,文章希望给“简单”的任务更高的权重。在综述中是这样写的:
We hypothesize that the two techniques do not necessarily conflict, but uncertainty weighting seems better suited when tasks have noisy labeled data, while DTP makes more sense when we have access to clean ground-truth annotations.
这两种方法不一定是完全冲突的,不确定性建模似乎可以适用于标签噪声更大的数据,而DTP可能在干净的标注数据里效果更好。(你是怎么看的呢?可以在评论区讨论一下)