PyTorch深度学习实践——卷积神经网络(GoogLeNet部分实现、ResNet )
参考资料
参考资料1:https://blog.csdn.net/bit452/article/details/109693790
参考资料2:http://biranda.top/Pytorch%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0012%E2%80%94%E2%80%94Advancedd_CNN/
torch.nn.Conv2d 为什么只定义卷积核的大小,而不定义卷积核的具体数值
卷积核都是随机的
https://segmentfault.com/q/1010000022234007
GoogLeNet部分实现
1×1Conv下面的括号是输出有几个通道。
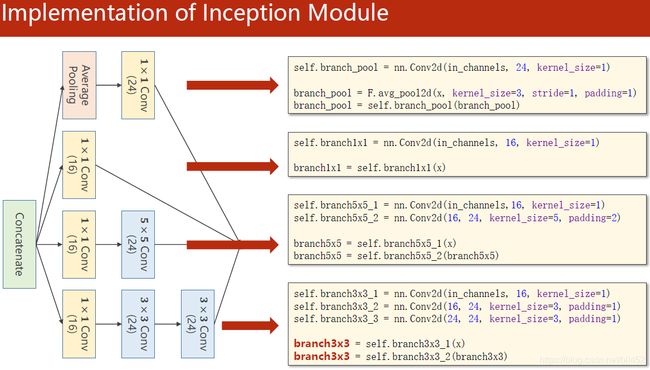
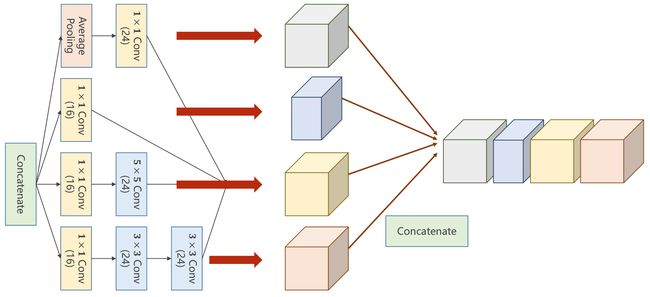
每次维度为[64,1,28,28]的图像,经过两次Inception Module 后,再通过一个全连接 生成10个概率。
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class InceptionA(nn.Module):
# 仅是一个模块,其中的输入通道数并不能够指明
def __init__(self, in_channels):
super(InceptionA, self).__init__()
# 1
# 定义一个输出通道为16的单一的1×1的卷积
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
# 2
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
# 3
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
# 4
# init内定义1x1卷积(输入通道 输出通道 卷积核大小)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
# 1
branch1x1 = self.branch1x1(x)
# 2
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
# 3
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
# 4
# avg_pool2d->均值池化函数 stride以及padding需要手动设置以保持图像的宽度和高度不变,
#这里设置kernel_size=3, stride=1, padding=1是为了 图像的长和宽不变。
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
# 括号内branch_pool的是池化后的结果,括号外的branch_pool是定义的1x1卷积,赋值给对象branch_pool
branch_pool = self.branch_pool(branch_pool)
# 利用Concatenate按通道维度方向进行拼接可得到输出图像。dim=1 意味着按下标为1的维度方向拼接,在图像有四个维度(B,C,W,H),dim=1的是通道C。
# cat拼接
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
# 在Inception的定义中,拼接后的输出通道数为24+16+24+24=88个
self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16
self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应
self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应
self.mp = nn.MaxPool2d(2)
# 关于1408:
# 每次卷积核是5x5,则卷积后原28x28的图像变为24x24的
# 再经过最大池化,变为12x12的
# 以此类推最终得到4x4的图像,又inception输出通道88,则转为一维后为88x4x4=1408个
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0) # in_size:64 , size([64,1,28,28])
# 1、将一个1通道的转为10通道的,
x = F.relu(self.mp(self.conv1(x)))
# 2、将10通道的转为24+16+24+24=88 通道的
x = self.incep1(x)
# 3、将88通道的转为20通道的,
x = F.relu(self.mp(self.conv2(x)))
# 4、将20通道的转为88通道的,
x = self.incep2(x)
# 上面有解释为何1408
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
#GPU
#cuda 0是选择第一块显卡,cuda 1是选择第二块显卡。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#将来model迁移到device
model.to(device)
# construct loss and optimizer
#交叉熵损失函数CrossEntropyLoss()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
# batch_size = 64 ,最前面已经声明了
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
#GPU
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()# 优化器梯度清零
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():# 测试集不需要计算梯度
for data in test_loader:
images, labels = data
#GPU
# send the images and labels at every step to the GPU。
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

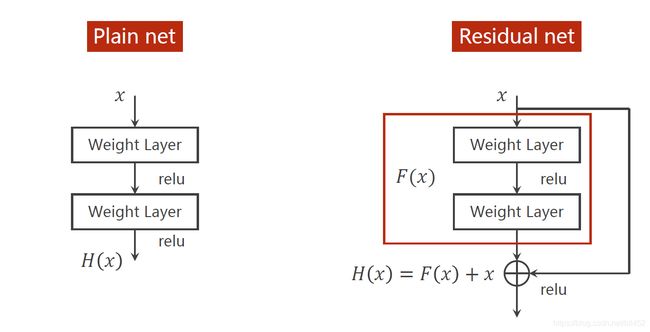
ResNet残差网络
plain net 纯网络
residual net 残差网络


import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
#训练集
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
#测试集
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
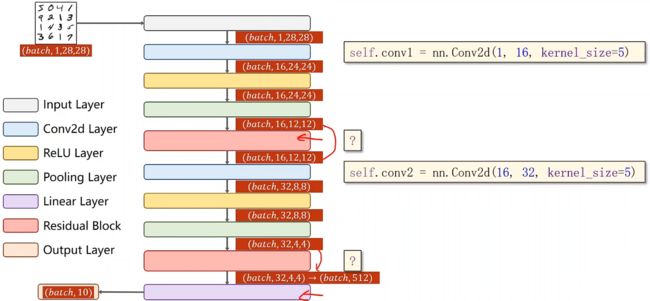
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5) # 88 = 24x3 + 16
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)#(64,32×4×4=512)
x = self.fc(x)
return x
model = Net()
#GPU
#cuda 0是选择第一块显卡,cuda 1是选择第二块显卡。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#将来model迁移到device
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
#GPU
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
# GPU
# send the images and labels at every step to the GPU。
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
