(pytorch进阶之路二)transformer学习与难点代码实现
写在前面:https://github.com/yyz159756/pytorch_learn/tree/main/transformer
文章目录
- 理解
- Encoder
- Decoder
- word embedding
- position embedding
- Attention
- Encoder self attention mask
- Intra attention mask
- Decoder self attention mask
- Mask loss
理解
transformer和cnn、rnn最大的区别是它的先验假设(归纳偏置)比较少,没有假设局部关联性(cnn),也没有去假设有序建模性(rnn),它的假设是任意一个位置都可以与其他位置有关联性,基本上没有任何的先验假设。好处是相比于cnn和rnn它可以更快速的学习无论是长时还是短时的关联性。但是数据量的要求与先验假设的程度成反比,也就是说先验假设越多,我们人为注入了更多的我们的经验,模型就更容易去学,需要的数据量就越低。
因此transformer模型我们也不是可以无脑用,因为它的先验假设很少,要用好transformer模型,还要根据不同的任务,注入一些任务相关的先验假设,比如在注意力机制上或者是loss上,或者是模型结构上,根据这些先验假设做一些改变或者优化。比如每个位置的注意力机制的计算不需要针对整个序列,而是针对周围的几个token,这样的先验假设就是局部关联性。
另外的特点就是transformer核心计算在注意力机制上,平方复杂度,与序列长度的平方成比例。
主要任务:机器翻译、语音识别
Encoder
主要有以下的组成,position embedding,multi head self attention(位置信息混合),layer norm & residual,feedforward neural network(特征层进行混合)
Encoder only模型:bert,分类任务(如句子情感判断),非流式任务
Decoder
主要有以下的组成,position embedding,casual multi head self attention(因果自回归), layer norm & residual,memory base multi head cross attention(QKV),feedforward neural network
Decoder only模型:GPT模型,语言建模,自回归任务,流式模型,
word embedding
embedding作用是将高维离散token映射到低维稠密token
假设一个任务背景:英语翻译德语,首先我们需要构建一个英语句子 源序列 source sentence和一个目标序列 target sentence 德语,源序列 src_seq 和 目标序列 tgt_seq
序列该如何构建呢?接触过NLP应该都不陌生,序列的字符以词表dict的索引的形式表示
规定序列长度,假设为src和tgt len
# %%
import numpy
import torch as T
import torch.nn as nn
import torch.nn.functional as F
# %%
# 假设有两个句子
batch_size = 2
# 每个句子长度为2~5
src_len = T.randint(2, 5, (batch_size, ))
tgt_len = T.randint(2, 5, (batch_size, ))
# 方便研究,我们写死
src_len = T.Tensor([2, 4]).to(T.int32)
tgt_len = T.Tensor([4, 3]).to(T.int32)
print(src_len)
print(tgt_len)
输出结果tensor([2, 4]),tensor([4, 2]),说明src句子长度为2和4,tgt句子长度为4和2,一共两个句子

接着我们构建seq,假设src和tgt dict最大序号为8,就是最大单词数量都是8,随机生成seq放入list,为了保证句子长度一致,我还需要padding操作,使用functional里的pad函数,之后序列用unsqueeze、cat转换成[batch_size, max_len]形式的tensor作为batch输入
# %%
# 单词表大小
max_source_word_num = 8
max_target_word_num = 8
# 最大序列长度
max_source_seq_len = 5
max_target_seq_len = 5
# 生成seq
src_seq = [T.randint(1, max_source_word_num, (L,)) for L in src_len]
# padding
src_seq = list(map(lambda x: F.pad(x, (0, max_source_seq_len - len(x))), src_seq))
# 升一维方便我们拼接
src_seq = list(map(lambda x: T.unsqueeze(x, 0), src_seq))
# 拼接
src_seq = T.cat(src_seq, 0)
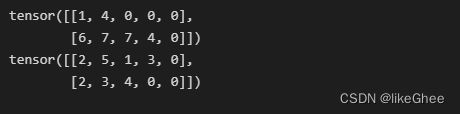
print(src_seq)
tgt_seq = [F.pad(T.randint(1, max_target_word_num, (L,)), (0, max_target_seq_len-L)) for L in tgt_len]
tgt_seq = list(map(lambda x: T.unsqueeze(x, 0), tgt_seq))
tgt_seq = T.cat(tgt_seq, 0)
print(tgt_seq)
输出结果:
输入完成,中间部分embedding,使用pytorch的API,nn.Embedding
第一个参数 num_embeddings,单词数,我们一般取最大单词表大小 + 1,padding的0算上
第二个参数 embedding_dim, 词向量维数,一般是512,方便我们取8
# %%
model_dim = 8
# 构造embedding table
src_embedding_table = nn.Embedding(max_source_word_num + 1, model_dim)
tgt_embedding_table = nn.Embedding(max_target_word_num + 1, model_dim)
print(src_embedding_table.weight.size())
# 测试一下forward
src_embedding = src_embedding_table(src_seq)
print(src_embedding.size())

position embedding
Attention is all you need中有PE(position embedding)的表达式,大体思路是将单词在句子的位置信息转换为一个向量,再与WE(word embedding)相加
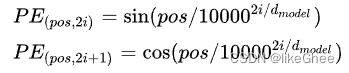
首先PE是一个二维的矩阵:[max_len, dim],最大长度可以和max_source_seq_len一致,这里规定max_position_len=5
PE矩阵可以看作是两个矩阵相乘,一个矩阵是pos(/左边),另一个矩阵是i(/右边),奇数列和偶数列再分别乘sin和cos
# %%
max_position_len = 5
pos_matrix = T.arange(max_position_len).reshape((-1, 1))
print(pos_matrix)
# 因为要分奇数列和偶数列,所以间隔为2
i_matrix = T.pow(10000, T.arange(0, model_dim, 2).reshape([1, -1]) / model_dim)
print(i_matrix)
# 构建embedding矩阵
pe_embedding_table = T.zeros([max_position_len, model_dim])
# 偶数列,行不变,0::2偶数列,意思是下标从0开始,直到最后,取步长为2的所有元素
pe_embedding_table[:, 0::2] = T.sin(pos_matrix / i_matrix)
# 奇数列
pe_embedding_table[:, 1::2] = T.cos(pos_matrix / i_matrix)
print(pe_embedding_table)
构造nn.Module,替换掉weight
# %%
# 改写nn Module weight方式创建pe embedding
pe_embedding = nn.Embedding(max_position_len, model_dim)
pe_embedding.weight = nn.Parameter(pe_embedding_table, requires_grad=False)
print(pe_embedding.weight.size())
构造输入,我们需要传入位置索引,自然就是用range操作了,最后计算出PE
# %%
# 构造位置索引
src_pos = T.cat([T.unsqueeze(T.arange(max_position_len), 0) for _ in src_len] , 0)
print(src_pos)
tgt_pos = T.cat([T.unsqueeze(T.arange(max_position_len), 0) for _ in tgt_len] , 0)
# forword计算src-pe
src_pe_embedding = pe_embedding(src_pos)
print(src_pe_embedding.size())
Attention
# %% 注意机制实现
def attention(query: torch.Tensor, key: torch.Tensor,
value: torch.Tensor, mask=None, dropout=None):
"""
shape: [batch_size * num_head, seq_len, model_dim/num_head]
"""
# size()的最后一个维度
d_k = query.size(-1)
# 计算attention
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
# mask矩阵等于0的地方,将该元素置为负无穷
scores = scores.masked_fill(mask == 0, -1e9)
# 计算softmax,因为softmax是单调函数,
# 又因为mask的地方被置为了负无穷,所以softmax出来是0
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
Encoder self attention mask
self attention mask目的是mask掉padding多出来的0
一般mask是放在softmax中的,softmax是单调函数,输入负无穷输出则接近0,因此我们构造的mask矩阵(bool矩阵)使用masked_fill使得score被mask的元素被设置为负无穷。
mask的shape [batch_size, max_src_len, max_src_len],max_src_len是最大句子长度
我们先构造有效位置pos,padding至max_src_len,用unsqueeze cat bmm reshape至mask的shape,构造出mask布尔矩阵,最后使用masked_fill构造出masked_score
import torch
import torch as T
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
#%%
# 假设有两个句子
batch_size = 2
# 每个句子长度为2~5
src_len = T.randint(2, 5, (batch_size, ))
tgt_len = T.randint(2, 5, (batch_size, ))
print(src_len)
print(tgt_len)
# 方便研究,我们写死
src_len = T.Tensor([2, 4]).to(T.int32)
tgt_len = T.Tensor([4, 3]).to(T.int32)
valid_encoder_pos = [torch.ones(L) for L in src_len]
# padding至max句子长度
valid_encoder_pos = list(map(lambda x: F.pad(x, (0, max(src_len) - len(x))), valid_encoder_pos))
# 扩1维
valid_encoder_pos = list(map(lambda x: T.unsqueeze(x, 0), valid_encoder_pos))
# 拼接
valid_encoder_pos = T.cat(valid_encoder_pos, 0)
# 继续扩维 -> [2,4,1]
valid_encoder_pos = T.unsqueeze(valid_encoder_pos, 2)
print(valid_encoder_pos.shape, "# valid_encoder_pos")
# bmm:带批的矩阵相乘 [2,4,1] * [2,1,4]
valid_encoder_pos_matrix = torch.bmm(valid_encoder_pos, valid_encoder_pos.transpose(1, 2))
print(valid_encoder_pos_matrix.shape, "# valid_encoder_pos_matrix")
print(valid_encoder_pos_matrix, "# 4*4,valid_encoder_pos_matrix 第一行表示第一个单词对其他单词的有效性")
invalid_encoder_pos_matrix = 1-valid_encoder_pos_matrix # 取反
print(invalid_encoder_pos_matrix, "# invalid_encoder_pos_matrix 0表示有效位置,1表示无效的位置")
mask_encoder_self_attention = invalid_encoder_pos_matrix.to(torch.bool)
print(mask_encoder_self_attention, "# mask_encoder_self_attention True的地方需要mask")
# 用法,随机生成一个score
score = torch.randn(batch_size,max(src_len), max(src_len))
masked_score = score.masked_fill(mask_encoder_self_attention, -1e9) # 传入一个布尔型的张量,mask的地方置为负无穷
# 再对masked的score计算一个softmax, 计算出注意力的权重
prob = F.softmax(masked_score, -1)
print(prob, "# 注意力权重")
Intra attention mask
intra attention是decoder block的中间部分,decoder目标序列的自注意力输出作为Query,把encoder的Memory当作key和value,Q和K算出一个score,经过softmax得到一个权重,再用权重与value加权求和,得到一个新的表征,这个表征反应的就是目标序列和源序列的相关性的表征。
在上述的decoder的intra注意力机制过程中就涉及到一个目标序列与源序列关联性的mask – intra attention mask
# intra-attention mask实现
# 公式 Q valid pos @ K^T valid pos, shape:[batch_size, tgt_seq_len, src_seq_le]
# 构造tgt mask
valid_decoder_pos = torch.unsqueeze(torch.cat([torch.unsqueeze(F.pad(torch.ones(L), (0, max(tgt_len)-L)), 0)for L in tgt_len]), 2)
print(valid_decoder_pos, "# valid_decoder_pos")
print(valid_decoder_pos.shape, "# valid_decoder_pos size")
# 构造出交叉有效位置 -- mask矩阵
valid_cross_pos_matrix = torch.bmm(valid_decoder_pos, valid_encoder_pos.transpose(1, 2))
print(valid_cross_pos_matrix, "# valid_cross_pos 目标序列对源序列关联有效矩阵,1表示有效, src len:[2,4] tgt len:[4,3], 所以一个tensor表示tgt 4个单词注意力到src的2个单词")
# 下面其实不用置反操作也行,使用masked_fill时候,参数mask == 0
invalid_cross_pos_matrix = 1-valid_cross_pos_matrix
print(invalid_cross_pos_matrix, "# invalid_cross_pos_matrix,1表示无效")
# 转换为bool类型
cross_attention_mask = invalid_cross_pos_matrix.to(torch.bool)
print(cross_attention_mask, "# cross_attention_mask, True表示需要mask的地方")
Decoder self attention mask
decoder是自回归模型,一次只预测一个值,将预测的值送回decoder作为输入,产生第二次输出,以此往复,也就是说每个单词的预测都是建立在上一个单词预测的基础上。
那么为了使训练阶段与预测(infer)阶段过程保持一致,那么我们在训练阶段就需要对decoder的输入做一定的遮掩。
如果直接将tgt seq输入decoder,就违背了因果,提前知道了答案,训练就没有意义了。
所以训练阶段就需要把答案遮住,通过decoder输出去预测这个答案,这样才能和预测(infer)阶段保持一致。
因此decoder self attention的mask是一个三角形的mask矩阵,第一次输入是特殊字符,第二次输入特殊字符和一个目标值,第三次…
# 构造decoder self attention mask
# 构建一个下三角矩阵
valid_decoder_tri_matrix = [torch.tril(torch.ones(L,L)) for L in tgt_len] # tgt_len:[4, 3]
# pad操作是从低维到高维的,向后填充和向下填充
valid_decoder_tri_matrix = list(map(lambda x: F.pad(x, (0,max(tgt_len) - len(x),0,max(tgt_len) - len(x))), valid_decoder_tri_matrix))
print(valid_decoder_tri_matrix, "# valid_decoder_tri_matrix, 第二张量也变成四行了")
valid_decoder_tri_matrix = list(map(lambda x: torch.unsqueeze(x, 0), valid_decoder_tri_matrix))
valid_decoder_tri_matrix = torch.cat(valid_decoder_tri_matrix)
print(valid_decoder_tri_matrix.shape, "# valid_decoder_tri_matrix,扩维 拼接")
print("已经构建好了decoder self attention mask了")
invalid_decoder_tri_matrix = 1-valid_decoder_tri_matrix
invalid_decoder_tri_matrix = invalid_decoder_tri_matrix.to(torch.bool)
print(invalid_decoder_tri_matrix)
# 测试decoder self attention mask
score: torch.Tensor = torch.randn(batch_size, max(tgt_len), max(tgt_len))
score.masked_fill_(invalid_decoder_tri_matrix, -1e9)
print(score)
prob = F.softmax(score, dim=-1)
print(prob)
Mask loss
手动mask
# 出现了padding情况,第一个句子长度是2,因此需要mask掉
tgt_len = torch.Tensor([2,3]).to(torch.int32)
print(tgt_len, "# tgt_len")
mask = torch.cat([torch.unsqueeze(F.pad(torch.ones(L), (0, max(tgt_len) - L)), 0) for L in tgt_len],0)
print(mask, "# mask")
loss = F.cross_entropy(logits, label, reduction='none') * mask
print(loss, "# mask loss")
使用ignore_mask参数
# 使用ignore_index,默认是-100
label[0, 2] = -100
print(label, "# with ignore_index label")
loss = F.cross_entropy(logits, label, reduction='none')
print(loss, "# loss ignore_index,默认是-100,自动mask操作")