机器学习-sklearn补充
具体有关sklearn知识点见机器学习(1)、(2)、(3)、(4)、(5)、(6)
1、加载图片import cv2
cv2.imread()
将彩色(三维的)图片转化成黑白的(图片灰度化处理),大大降低数据量。cv2.cvtColor(digit,code=cv2.COLOR_BRG2GRAY)
plt.imshow(digit,cmap = plt.cm.BuPu)
2、如果k近邻的邻居数不知道选多少,可以用样本数开根号得出的数作为邻居数,但这个邻居数也不一定是最适合的。
距离公式:欧氏距离
d = \sqrt{(x1 - y1)^2 + (x2 - y2)^2 + (x3 - y3)^2 + ……}
3、算法是“学习”,不是死记硬背,不是存在数据库一样,所以预测训练集的结果,准确率也不会达到100%。要进行一一对比。
4、图片可进行二值化操作,非黑即白。
5、datasets.load_iris(False)默认是False,返回的是字典,如果改为True,返回的是x,y的值。
6、降维(指特征降维),切片 X=X[:,:2] 将原来的4维降维2维。
7、用法:linspace(x1,x2,N)
功能:linspace是Matlab中的均分计算指令,用于产生x1,x2之间的N点行线性的矢量。其中x1、x2、N分别为起始值、终止值、元素个数。若默认N,默认点数为100。
8、[X,Y] = meshgrid(x,y)
meshgrid返回的两个矩阵X、Y必定是行数、列数相等的 (即X、Y两个矩阵都有相同的行数,和相同的列数)且X、Y的行数都等于输入参数y中元素的总个数,X、Y的列数都等于输入参数x中元素总个数(这个结论可以通过查看 meshgrid的源代码得到,可以通过示例程序得到验证)。
meshgrid()对于三维图形来说,输出的是xy平面区域上的函数值。假设x是从-1到1;y也是-1到1;z=f(x,y)中(x,y)是2x2的正方形中所有点的组合,在matlab中x,y的范围用矢量表示,通过meshgrid函数就把x,y转换成矩阵X,Y;通过矩阵X,Y来表示平面区域上所有点的组合。
9、一维化:reshape()与ravel()
10、ListedColormap()定义颜色
contourf画轮廓面,等高面
11、模型选择中的交叉验证
from sklearn.model_selection import cross_val_score

12、%matplotlib inline是一个魔法函数(Magic Functions)。官方给出的定义是:IPython有一组预先定义好的所谓的魔法函数(Magic Functions),你可以通过命令行的语法形式来访问它们。
![]()
13、重"uniform","distance"
选择默认的"uniform",意味着所有最近邻样本权重都一样,在做预测时一视同仁。如果是"distance",则权重和距离成反比例,即距离预测目标更近的近邻具有更高的权重,这样在预测类别或者做回归时,更近的近邻所占的影响因子会更加大。
p值; p=2:即欧式距离;p=1:即曼哈顿距离
14、iloc和loc的区别
iloc主要使用数字来索引数据,不能使用字符型的标签来索引数据。
loc只能使用字符型标签来索引数据,不能使用数字来索引数据。
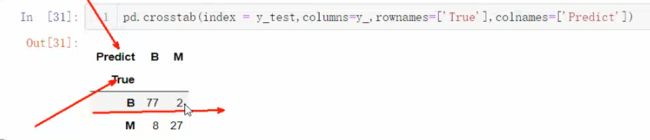
15、crosstab()总是返回一个数据帧。dataframe是两个变量的交叉表:True和Predict。交叉表表示取一个变量,将其组显示为index,取另一个变量,将其组显示为columns。
16、精确率、召回率

17、KFold、StratifiedKFold将数据分成多份
from sklearn.model_selection import KFold, StratifiedKFold
sklearn中的Kfold和StratifiedKFold都是k折交叉切分。StratifiedKFold(默认切分3份)用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同。
18、熵:是对于不确定性的度量,不确定性就是有序和无序,是离散随机时间的概率,一个系统越有序,它的信息熵越低,一个系统越混乱,它的信息熵越高,可以认为是系统有序化的度量。
19、OrdinalEncoder(DataFrame),OneHotEncoder,LabalEncoder(Series)
OrdinalEncoder:将每列特征按照每列特征内容去重后的顺序进行编码(一列特征中存在多个类别区分,比如教育特征中包含博士、硕士、本科、专科),返回数字编码。
LabalEncoder:与OrdinalEncoder类似,但每次只能输入一个特征值,并返回该特征值数组形式编码。
OneHotEncoder:每次只能输入一个特征值,返回二维数组,如果只选择10个人进行教育特征的one-hot编码,每一个人属于教育特征中的哪一类,就在那一类的位置(每列特征内容去重后的顺序位置,比如本科排在教育特征中的第三个位置)进行独热,标注1,其余为0
OneHotEncoder与OrdinalEncoder的区别是OneHotEncoder能消除数值大小对算法的影响。
20、信息熵的决策树:标准差越大,越波动,越离散,越容易分开,但是不一定选标准差大的进行裂分,它只是其中的一个条件,还要看信息熵,信息熵越大的越不纯。
基尼系数:基尼系数越小,越纯。
决策树的使用不需要对数据进行归一化和标准化。在公司的应用中,不用决策树,太简单,用决策树的升级版:集成算法(随机森林,(extrem)极限深林,梯度提升树,adaboost提升树)
随机森林通过组合不同的树,组合不同树的结果,取概率多的作为最终结果。
21、决策树,进行裂分的时候,根据信息增益最大进行裂分,比较刻板。
极限森林(1)样本随机 (2)分裂条件随机(不是最好的裂分条件)
像在随机森林中一样,使用候选特征的随机子集,但不是寻找最有区别的阈值,而是为每个候选特征随机绘制阈值,并选择这些随机生成的阈值中的最佳阈值作为划分规则。
22、梯度提升树(GradientBoostClassifier/分类,GradientBoostRegressor/回归) 梯度=导数
梯度提升树用于分类,也是森林,也是集成算法,其基本树(决策树,分类树)
梯度提升树用回归方式进行分类。
criterion="friedman_mse" mse均方偏差(mean-square-error)
如果是二分类,使用一棵树就可以分开
如果是三分类,需要使用3棵树,才能将彼此类两两分开。
回归是分类的极限思想,分类的类别多到一定程度,那么就是回归。
残差越小,结果越好,越接近平均值,通过学习率(默认是0.1),不断提升树,残差会越来越小。
学习率太大容易产生梯度爆炸或梯度消失。
tollerence容忍度,误差在万分之一,任务结束;
precision精确度,精度达到万分之一,任务结束。precision=0.001
min.value和max.value瞎蒙的值,方法,最快的速度找到最优解(梯度下降)
23、在Bagging中,通过对训练样本重新采样的方法得到不同的训练样本集,在这些新的训练样本集上分别训练学习器,最终合并每一个学习器的结果,作为最终的学习结果,Bagging方法代表:随机森林。随机森林中每棵树的权重一样的。
在Boosting算法中,学习器之间是存在先后顺序的,同时,每一个样本是有权重的,初始时,每一个样本的权重是相等的。首先,第1个学习器对训练样本进行学习,当学习完成后,增大错误样本的权重,同时减小正确样本的权重,再利用第2个学习器对其进行学习,依次进行下去,最终得到b个学习器,最终,合并这b个学习器的结果,同时,与Bagging中不同的是,每一个学习器的权重也是不一样的。Boosting方法代表:梯度提升树。在Boosting方法中,最重要的方法包括:AdaBoost和GBDT。
AdaBoost算法与Boosting算法不同,它是使用整个训练集来训练弱学习器,其中训练样本在每次迭代的过程中都会重新被赋予一个权重,在上一个弱学习器错误的基础上进行学习来构建一个更加强大的分类器。AdaBoost提升树中每棵树的权重不同。
sign是负号函数,大于等于0变成1,小于0变成-1。
24、对于线性回归和逻辑回归,其目标函数为: g(x) = w1x1 + w2x2 + w3x3 + w4x4 + w0
如果有激活函数sigmoid,增加非线性变化 则为分类 即逻辑回归
如果没有激活函数,则为回归。对于这样的线性函数,都会有coef_和intercept_函数。
coef_为w1到w4,权重
intercept_为w0,偏移(与y轴交叉的位置)
25、concatenate函数

concatenate((a1, a2, …), axis=0) 数组拼接函数
参数:
a1,a2……为要拼接的数组
axis为在哪个维度上进行拼接,默认为0
>>> a = np.array([[1, 2], [3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.concatenate((a, b.T), axis=1)
array([[1, 2, 5],
[3, 4, 6]])
对numpy.append()和numpy.concatenate()两个函数的运行时间进行比较,concatenate()效率更高,适合大规模的数据拼接。
26、共线性对非共线性的变量的系数估计不产生影响。
共线性不会影响模型的拟合优度。
共线性会使得共线性的变量的系数估计变得不可靠,但共线性变量的系数之间维持一种近似的特殊关系。
数据不好的情况(包括共线性问题)使用岭回归,数据质量好的情况,线性回归比岭回归结果要好。
线性回归处理不好的时候,使用Lasso回归,线性回归拟合的时候,使用Lasso回归或岭回归,样本的数量少于属性的时候或者特征数量特别多的时候,使用Lasso回顾,也可以使用岭回归,它们缩减的程度不一样。
27、当选择数据较小的时候,logspace(-5,1,50)比linspace(0.01,5,50)划分的更细致、更均匀。
logspace()创建等比数列
28、subplot(m,n,p)或者subplot(mnp)此函数最常用:subplot是将多个图画到一个平面上的工具。其中,m表示是图排成m行,n表示图排成n列,也就是整个figure中有n个图是排成一行的,一共m行,如果第一个数字是2就是表示2行图。p是指你现在要把曲线画到figure中哪个图上,最后一个如果是1表示是从左到右第一个位置。
29、逻辑斯蒂回归:利用Logistics回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式(f(x1,x2……) = w1x1+w2x2+……),以此进行分类。这里的“回归” 一词源于最佳拟合,表示要找到最佳拟合参数集。
逻辑斯蒂回归是一个非常经典的二项分类模型,也可以扩展为多项分类模型。其在应用于分类时的过程一般如下,对于给定的数据集,首先根据训练样本点学习到参数w,b;再对预测点分别计算两类的条件概率,将预测点判为概率值较大的一类。
30、弹性网络(ElasticNet)是一种使用L1和L2先验作为正则化矩阵的线性回归模型.这种组合用于只有很少的权重非零的稀疏模型,比如:class:Lasso, 但是又能保持:class:Ridge 的正则化属性.我们可以使用 l1_ratio 参数来调节L1和L2的凸组合(一类特殊的线性组合)。
当多个特征和另一个特征相关的时候弹性网络非常有用。Lasso 倾向于随机选择其中一个,而弹性网络更倾向于选择两个。
31、连接函数concat()
32、FacetGrid当您想要在数据集的子集中分别可视化变量的分布或多个变量之间的关系时,该类非常有用。
share{x,y} : 是否共享x轴或者y轴,就是说如果为真,就共享同一个轴,否则就不共享,默认是都共享,即都为True
g = sns.FacetGrid(tips, col="sex", hue="smoker",sharex=True, sharey=True)# 都共享
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend()
33、Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使你的图变得精致。
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。

34、corr相关性系数
cov协方差,协方差是两个属性之间的关系,如果两个属性一样,就是方差。方差是协方差的一种特殊形式,就好比椭圆是圆的一种特殊形式,导数是偏导数的特殊形式。
corr = cov/(std1*std2)