PyTorch从入门到实践 | (6) PyTorch实战指南:猫狗二分类
原文地址
在学习某个深度学习框架时,掌握其基本知识和接口固然重要,但如何合理组织代码,使得代码具有良好的可读性和可扩展性也必不可少。本文不会深入讲解过多知识性的东西,更多的则是传授一些经验,关于如何使得自己的程序更pythonic,更符合pytorch的设计理念。这些内容可能有些争议,因其受我个人喜好和coding风格影响较大,你可以将这部分当成是一种参考或提议,而不是作为必须遵循的准则。归根到底,都是希望你能以一种更为合理的方式组织自己的程序。
在做深度学习实验或项目时,为了得到最优的模型结果,中间往往需要很多次的尝试和修改。根据我的个人经验,在从事大多数深度学习研究时,程序都需要实现以下几个功能:
1)模型定义
2)数据处理和加载
3)训练模型(Train&Validate)
4)训练过程的可视化
5)测试(Test/Inference)
另外程序还应该满足以下几个要求:
1)模型需具有高度可配置性,便于修改参数、修改模型,反复实验
2)代码应具有良好的组织结构,使人一目了然
3)代码应具有良好的说明,使其他人能够理解
在本文我将应用这些内容,并结合实际的例子,来讲解如何用PyTorch完成Kaggle上的经典比赛:Dogs vs. Cats。
完整项目。
数据集下载
目录
1. 比赛介绍
2. 文件组织架构
3. 关于__init__.py
4. 数据加载
5. 模型定义
6. 工具函数
7. 配置文件
8. main.py
9. 使用
10. 争议
1. 比赛介绍
Dogs vs. Cats是一个传统的二分类问题,其训练集包含25000张图片,均放置在同一文件夹下,命名格式为

2. 文件组织架构
首先来看程序文件的组织结构:
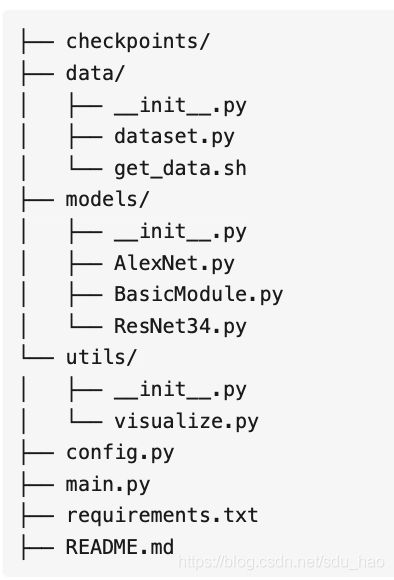
其中:
1)checkpoints/: 用于保存训练好的模型,可使程序在异常退出后仍能重新载入模型,恢复训练
2)data/:数据相关操作,包括数据预处理、dataset实现等
3)models/:模型定义,可以有多个模型,例如上面的AlexNet和ResNet34,一个模型对应一个文件
4)utils/:可能用到的工具函数,在本次实验中主要是封装了可视化工具
5)config.py:配置文件,所有可配置的变量都集中在此,并提供默认值
6)main.py:主文件,训练和测试程序的入口,可通过不同的命令来指定不同的操作和参数
7)requirements.txt:程序依赖的第三方库
8)README.md:提供程序的必要说明
3. 关于__init__.py
可以看到,几乎每个文件夹下都有__init__.py,一个目录如果包含了__init__.py 文件,那么它就变成了一个包(package)。__init__.py可以为空,也可以定义包的属性和方法,但其必须存在,其它程序才能从这个目录中导入相应的模块或函数。例如在data/文件夹下有__init__.py,则在main.py 中就可以
from data.dataset import Dogcat而如果在data/__init__.py中写入:
from .dataset import Dogcat则在main.py中就可以直接写为:
from data import Dogcat或者:
import data;
dataset = data.Dogcat相比于from data.dataset import DogCat更加便捷。
4. 数据加载
数据的相关处理主要保存在data/dataset.py中。关于数据加载的相关操作,其基本原理就是使用Dataset进行数据集的封装,再使用Dataloader实现数据并行加载。
Kaggle提供的数据包括训练集和测试集,而我们在实际使用中,还需专门从训练集中取出一部分作为验证集。对于这三类数据集,其相应操作也不太一样,而如果专门写三个Dataset,则稍显复杂和冗余,因此这里通过加一些判断来区分。对于训练集,我们希望做一些数据增强处理,如随机裁剪、随机翻转、加噪声等,而验证集和测试集则不需要。下面看dataset.py的代码:
import os
from PIL import Image
from torch.utils.data import Dataset
import numpy as np
from torchvision import transforms as T
class DogCat(Dataset):
def __init__(self, root, transforms=None, train=True, test=False):
'''
目标:获取所有图片路径,并根据训练、验证、测试划分数据
root:所有图片的存储路径
'''
self.test = test
imgs = [os.path.join(root, img) for img in os.listdir(root)] #得到所有图片的绝对路径
# 训练集和验证集的文件命名不一样
# test1: data/test1/8973.jpg
# train: data/train/cat.10004.jpg
if self.test: #测试集
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2].split('/')[-1])) #得到序号 如8973
else:
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2])) #得到序号 如10004
imgs_num = len(imgs) #数据量
# shuffle imgs
np.random.seed(100)
imgs = np.random.permutation(imgs) #打乱数据
# 将原始训练机划分训练、验证集,验证:训练 = 3:7
if self.test:
self.imgs = imgs
elif train:
self.imgs = imgs[:int(0.7 * imgs_num)]
else:
self.imgs = imgs[int(0.7 * imgs_num):]
if transforms is None:
# 数据转换操作,测试验证和训练的数据转换有所区别
#每个通道的均值和标准差
normalize = T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# 测试集和验证集不用数据增强
if self.test or not train:
self.transforms = T.Compose([
T.Scale(224),
T.CenterCrop(224),
T.ToTensor(),
normalize
])
# 训练集需要数据增强
else:
self.transforms = T.Compose([
T.Scale(256),
T.RandomSizedCrop(224),
T.RandomHorizontalFlip(),
T.ToTensor(),
normalize
])
def __getitem__(self, index):
'''
返回一张图片的数据
对于测试集,没有label,返回图片id,如1000.jpg返回1000
'''
img_path = self.imgs[index]
if self.test:
label = int(self.imgs[index].split('.')[-2].split('/')[-1])
else:
label = 1 if 'dog' in img_path.split('/')[-1] else 0 #dog 1 cat 0
data = Image.open(img_path) #读取数据
data = self.transforms(data) #数据转换
return data, label
def __len__(self):
'''
返回数据集中所有图片的个数
'''
return len(self.imgs)关于数据集使用的注意事项,在上一博客中已经提到,将文件读取等费时操作放在__getitem__函数中,利用多进程加速。避免一次性将所有图片都读进内存,不仅费时也会占用较大内存,而且不易进行数据增强等操作。另外在这里,我们将训练集中的30%作为验证集,可用来检查模型的训练效果,避免过拟合。
在使用时,我们可通过dataloader加载数据。
train_dataset = DogCat(opt.train_data_root, train=True)
trainloader = DataLoader(train_dataset,
batch_size = opt.batch_size,
shuffle = True,
num_workers = opt.num_workers)
for ii, (data, label) in enumerate(trainloader):
train()
5. 模型定义
模型的定义主要保存在models/目录下,其中BasicModule是对nn.Module的简易封装,提供快速加载和保存模型的接口。
import torch.nn as nn
import time
import torch
class BasicModule(nn.Module):
'''
封装了nn.Module,主要提供save和load两个方法
'''
def __init__(self,opt=None):
super(BasicModule,self).__init__()
self.model_name = str(type(self)) # 模型的默认名字
def load(self, path):
'''
可加载指定路径的模型
'''
self.load_state_dict(torch.load(path))
def save(self, name=None):
'''
保存模型,默认使用“模型名字+时间”作为文件名,
如AlexNet_0710_23:57:29.pth
'''
if name is None:
prefix = 'checkpoints/' + self.model_name + '_'
name = time.strftime(prefix + '%m%d_%H:%M:%S.pth')
torch.save(self.state_dict(), name)
return name在实际使用中,直接调用model.save()及model.load(opt.load_path)即可,我们已经对保存和加载做了封装。
其它自定义模型一般继承BasicModule,然后实现自己的模型。其中AlexNet.py实现了AlexNet,ResNet34实现了ResNet34。在models/__init__py中,代码如下:
from .AlexNet import AlexNet
from .ResNet34 import ResNet34这样在主函数中就可以写成:
from models import AlexNet或:
import models
model = models.AlexNet()或:
import models
model = getattr(models, 'AlexNet')()其中最后一种写法最为关键,这意味着我们可以通过字符串直接指定使用的模型,而不必使用判断语句,也不必在每次新增加模型后都修改代码。新增模型后只需要在models/__init__.py中加上
from .new_module import NewModule其它关于模型定义的注意事项,在上一章中已详细讲解,这里就不再赘述,总结起来就是:
1)尽量使用nn.Sequential(比如AlexNet)
2)将经常使用的结构封装成子Module(比如GoogLeNet的Inception结构,ResNet的Residual Block结构)
3)将重复且有规律性的结构,用函数生成(比如VGG的多种变体,ResNet多种变体都是由多个重复卷积层组成)
感兴趣的 读者可以看看在`models/resnet34.py`如何用不到80行的代码(包括空行和注释)实现resnet34。当然这些模型在torchvision中有实现,而且还提供了预训练的权重,读者可以很方便的使用:
import torchvision as tv
resnet34 = tv.models.resnet34(pretrained=True)
6. 工具函数
在项目中,我们可能会用到一些helper方法,这些方法可以统一放在utils/文件夹下,需要使用时再引入。在本例中主要是封装了可视化工具visdom的一些操作,其代码如下,在本次实验中只会用到plot方法,用来统计损失信息。
# coding:utf8
import visdom
import time
import numpy as np
class Visualizer(object):
'''
封装了visdom的基本操作,但是你仍然可以通过`self.vis.function`
或者`self.function`调用原生的visdom接口
比如
self.text('hello visdom')
self.histogram(torch.randn(1000))
self.line(torch.arange(0, 10),torch.arange(1, 11))
'''
def __init__(self, env='default', **kwargs):
self.vis = visdom.Visdom(env=env, **kwargs)
# 画的第几个数,相当于横坐标
# 比如(’loss',23) 即loss的第23个点
self.index = {}
self.log_text = ''
def reinit(self, env='default', **kwargs):
'''
修改visdom的配置
'''
self.vis = visdom.Visdom(env=env, **kwargs)
return self
def plot_many(self, d):
'''
一次plot多个
@params d: dict (name, value) i.e. ('loss', 0.11)
'''
for k, v in d.iteritems():
self.plot(k, v)
def img_many(self, d):
for k, v in d.iteritems():
self.img(k, v)
def plot(self, name, y, **kwargs):
'''
self.plot('loss', 1.00)
'''
x = self.index.get(name, 0)
self.vis.line(Y=np.array([y]), X=np.array([x]),
win=unicode(name),
opts=dict(title=name),
update=None if x == 0 else 'append',
**kwargs
)
self.index[name] = x + 1
def img(self, name, img_, **kwargs):
'''
self.img('input_img', t.Tensor(64, 64))
self.img('input_imgs', t.Tensor(3, 64, 64))
self.img('input_imgs', t.Tensor(100, 1, 64, 64))
self.img('input_imgs', t.Tensor(100, 3, 64, 64), nrows=10)
'''
self.vis.images(img_.cpu().numpy(),
win=unicode(name),
opts=dict(title=name),
**kwargs
)
def log(self, info, win='log_text'):
'''
self.log({'loss':1, 'lr':0.0001})
'''
self.log_text += ('[{time}] {info}
'.format(
time=time.strftime('%m%d_%H%M%S'), \
info=info))
self.vis.text(self.log_text, win)
def __getattr__(self, name):
'''
self.function 等价于self.vis.function
自定义的plot,image,log,plot_many等除外
'''
return getattr(self.vis, name)
7. 配置文件
在模型定义、数据处理和训练等过程都有很多变量,这些变量应提供默认值,并统一放置在配置文件中,这样在后期调试、修改代码或迁移程序时会比较方便,在这里我们将所有可配置项放在config.py中。
class DefaultConfig(object):
env = 'default' # visdom 环境
model = 'AlexNet' # 使用的模型,名字必须与models/__init__.py中的名字一致
train_data_root = './data/train/' # 训练集存放路径
test_data_root = './data/test1' # 测试集存放路径
load_model_path = 'checkpoints/model.pth' # 加载预训练的模型的路径,为None代表不加载
batch_size = 128 # batch size
use_gpu = True # use GPU or not
num_workers = 4 # how many workers for loading data
print_freq = 20 # print info every N batch
debug_file = '/tmp/debug' # if os.path.exists(debug_file): enter ipdb
result_file = 'result.csv'
max_epoch = 10
lr = 0.1 # initial learning rate
lr_decay = 0.95 # when val_loss increase, lr = lr*lr_decay
weight_decay = 1e-4 # 损失函数可配置的参数主要包括:
1)数据集参数(文件路径、batch_size等)
2)训练参数(学习率、训练epoch等)
3)模型参数
这样我们在程序中就可以这样使用:
import models
from config import DefaultConfig
opt = DefaultConfig()
lr = opt.lr
model = getattr(models, opt.model)
dataset = DogCat(opt.train_data_root)这些都只是默认参数(如果后续不在命令行指定的话,就是用默认参数),在这里还提供了更新函数,根据字典更新配置参数。
def parse(self, kwargs):
'''
根据字典kwargs 更新 config参数
'''
# 更新配置参数
for k, v in kwargs.iteritems():
if not hasattr(self, k):
# 警告还是报错,取决于你个人的喜好
warnings.warn("Warning: opt has not attribut %s" %k)
setattr(self, k, v)
# 打印配置信息
print('user config:')
for k, v in self.__class__.__dict__.iteritems():
if not k.startswith('__'):
print(k, getattr(self, k))这样我们在实际使用时,并不需要每次都修改config.py,只需要通过命令行传入所需参数,覆盖默认配置即可。
opt = DefaultConfig()
new_config = {'lr':0.1,'use_gpu':False}
opt.parse(new_config)
opt.lr == 0.1
8. main.py
在讲解主程序main.py之前,我们先来看看2017年3月谷歌开源的一个命令行工具fire ,通过pip install fire即可安装。下面来看看fire的基础用法,假设example.py文件内容如下:
import fire
def add(x, y):
return x + y
def mul(**kwargs):
a = kwargs['a']
b = kwargs['b']
return a * b
if __name__ == '__main__':
fire.Fire()那么我们可以使用:
python example.py add 1 2 # 执行add(1, 2)
python example.py mul --a=1 --b=2 # 执行mul(a=1, b=2),kwargs={'a':1, 'b':2}
python example.py add --x=1 --y=2 # 执行add(x=1, y=2)可见,只要在程序中运行fire.Fire(),即可使用命令行参数python file
在主程序main.py中,主要包含四个函数,其中三个需要命令行执行,main.py的代码组织结构如下:
def train(**kwargs):
'''
训练
'''
pass
def val(model, dataloader):
'''
计算模型在验证集上的准确率等信息,用以辅助训练
'''
pass
def test(**kwargs):
'''
测试(inference)
'''
pass
def help():
'''
打印帮助的信息
'''
print('help')
if __name__=='__main__':
import fire
fire.Fire()根据fire的使用方法,可通过python main.py
- 训练
训练的主要步骤如下:
1)定义网络
2)定义数据
3)定义损失函数和优化器
4)计算重要指标
-
5)开始训练
6)训练网络
7)可视化各种指标
8)计算在验证集上的指标
训练函数的代码如下:
def train(**kwargs):
# 根据命令行参数更新配置
opt.parse(kwargs)
vis = Visualizer(opt.env)
# step1: 模型
model = getattr(models, opt.model)()
if opt.load_model_path:
model.load(opt.load_model_path)
if opt.use_gpu: model.cuda()
# step2: 数据
train_data = DogCat(opt.train_data_root ,train=True)
val_data = DogCat(opt.train_data_root ,train=False)
train_dataloader = DataLoader(train_data ,opt.batch_size,
shuffle=True,
num_workers=opt.num_workers)
val_dataloader = DataLoader(val_data ,opt.batch_size,
shuffle=False,
num_workers=opt.num_workers)
# step3: 目标函数和优化器
criterion = torch.nn.CrossEntropyLoss()
lr = opt.lr
optimizer = torch.optim.Adam(model.parameters(),
lr = lr,
weight_decay = opt.weight_decay)
# step4: 统计指标:平滑处理之后的损失,还有混淆矩阵
loss_meter = meter.AverageValueMeter()
confusion_matrix = meter.ConfusionMeter(2)
previous_loss = 1e100
# 训练
for epoch in range(opt.max_epoch):
loss_meter.reset()
confusion_matrix.reset()
for ii ,(data ,label) in enumerate(train_dataloader):
# 训练模型
input = Variable(data)
target = Variable(label)
if opt.use_gpu:
input = input.cuda()
target = target.cuda()
optimizer.zero_grad()
score = model(input)
loss = criterion(score ,target)
loss.backward()
optimizer.step()
# 更新统计指标以及可视化
loss_meter.add(loss.data[0])
confusion_matrix.add(score.data, target.data)
if i i %opt.print_fre q= =opt.print_fre q -1:
vis.plot('loss', loss_meter.value()[0])
# 如果需要的话,进入debug模式
if os.path.exists(opt.debug_file):
import ipdb;
ipdb.set_trace()
model.save()
# 计算验证集上的指标及可视化
val_cm ,val_accuracy = val(model ,val_dataloader)
vis.plot('val_accuracy' ,val_accuracy)
vis.log("epoch:{epoch},lr:{lr},loss:{loss},train_cm:{train_cm},val_cm:{val_cm}"
.format(
epoch = epoch,
loss = loss_meter.value()[0],
val_cm = str(val_cm.value()),
train_cm=str(confusion_matrix.value()),
lr=lr))
# 如果损失不再下降,则降低学习率
if loss_meter.value()[0] > previous_loss:
lr = lr * opt.lr_decay
for param_group in optimizer.param_groups:
param_group['lr'] = lr
previous_loss = loss_meter.value()[0]这里用到了PyTorchNet里面的一个工具: meter。meter提供了一些轻量级的工具,用于帮助用户快速统计训练过程中的一些指标。AverageValueMeter能够计算所有数的平均值和标准差,这里用来统计一个epoch中损失的平均值。confusionmeter用来统计分类问题中的分类情况,是一个比准确率更详细的统计指标。例如对于下表,共有50张狗的图片,其中有35张被正确分类成了狗,还有15张被误判成猫;共有100张猫的图片,其中有91张被正确判为了猫,剩下9张被误判成狗。相比于准确率等统计信息,混淆矩阵更能体现分类的结果,尤其是在样本比例不均衡的情况下。

- 验证
验证相对来说比较简单,但要注意需将模型置于验证模式(model.eval()),验证完成后还需要将其置回为训练模式(model.train()),这两句代码会影响BatchNorm和Dropout等层的运行模式。代码如下。
def val(model, dataloader):
'''
计算模型在验证集上的准确率等信息
'''
# 把模型设为验证模式
model.eval()
confusion_matrix = meter.ConfusionMeter(2)
for ii, data in enumerate(dataloader):
input, label = data
val_input = Variable(input, volatile=True)
val_label = Variable(label.long(), volatile=True)
if opt.use_gpu:
val_input = val_input.cuda()
val_label = val_label.cuda()
score = model(val_input)
confusion_matrix.add(score.data.squeeze(), label.long())
# 把模型恢复为训练模式
model.train()
cm_value = confusion_matrix.value()
accuracy = 100. * (cm_value[0][0] + cm_value[1][1]) / \
(cm_value.sum())
return confusion_matrix, accuracy- 测试
测试时,需要计算每个样本属于狗的概率,并将结果保存成csv文件。测试的代码与验证比较相似,但需要自己加载模型和数据。
def test(**kwargs):
opt.parse(kwargs)
# 模型
model = getattr(models, opt.model)().eval()
if opt.load_model_path:
model.load(opt.load_model_path)
if opt.use_gpu: model.cuda()
# 数据
train_data = DogCat(opt.test_data_root, test=True)
test_dataloader = DataLoader(train_data, \
batch_size=opt.batch_size, \
shuffle=False, \
num_workers=opt.num_workers)
results = []
for ii, (data, path) in enumerate(test_dataloader):
input = torch.autograd.Variable(data, volatile=True)
if opt.use_gpu: input = input.cuda()
score = model(input)
probability = torch.nn.functional.softmax \
(score)[:, 1].data.tolist() #是狗的概率
batch_results = [(path_, probability_) \
for path_, probability_ in zip(path, probability)]
results += batch_results
write_csv(results, opt.result_file)
return results- 帮助函数
为了方便他人使用, 程序中还应当提供一个帮助函数,用于说明函数是如何使用。程序的命令行接口中有众多参数,如果手动用字符串表示不仅复杂,而且后期修改config文件时,还需要修改对应的帮助信息,十分不便。这里使用了Python标准库中的inspect方法,可以自动获取config的源代码。help的代码如下:
def help():
'''
打印帮助的信息: python file.py help
'''
print('''
usage : python {0} [--args=value,]
:= train | test | help
example:
python {0} train --env='env0701' --lr=0.01
python {0} test --dataset='path/to/dataset/root/'
python {0} help
avai able
args: '''.format(__file__))
from inspect import getsource
source = (getsource(opt.__class__))
print(source) 当用户执行python main.py help的时候,会打印如下帮助信息:

9. 使用
正如help函数的打印信息所述,可以通过命令行参数指定变量名.下面是三个使用例子,fire会将包含-的命令行参数自动转层下划线_,也会将非数值的值转成字符串。所以--train-data-root=data/train和--train_data_root='data/train'是等价的
# 训练模型
python main.py train
--train-data-root=data/train/
--load-model-path='checkpoints/resnet34_16:53:00.pth'
--lr=0.005
--batch-size=32
--model='ResNet34'
--max-epoch = 20
# 测试模型
python main.py test
--test-data-root=data/test1
--load-model-path='checkpoints/resnet34_00:23:05.pth'
--batch-size=128
--model='ResNet34'
--num-workers=12
# 打印帮助信息
python main.py help
10. 争议
以上的程序设计规范带有作者强烈的个人喜好,并不想作为一个标准,而是作为一个提议和一种参考。上述设计在很多地方还有待商榷,例如对于训练过程是否应该封装成一个trainer对象,或者直接封装到BaiscModule的train方法之中。对命令行参数的处理也有不少值得讨论之处。因此不要将本文中的观点作为一个必须遵守的规范,而应该看作一个参考。
本章中的设计可能会引起不少争议,其中比较值得商榷的部分主要有以下几个方面:
第一个是命令行参数的设置。目前大多数程序都是使用Python标准库中的argparse来处理命令行参数,也有些使用比较轻量级的click。这种处理相对来说对命令行的支持更完备,但根据作者的经验来看,这种做法不够直观,并且代码量相对来说也较多。比如argparse,每次增加一个命令行参数,都必须写如下代码
parser.add_argument('-save-interval', type=int,\
default=500,
help='how many steps to wait before saving [default:500]')在我眼中,这种实现方式远不如一个专门的config.py来的直观和易用。尤其是对于使用 Jupyter notebook或IPython等交互式调试的用户来说,argparse较难使用。
第二个是模型训练的方式。有不少人喜欢将模型的训练过程集成于模型的定义之中,代码结构如下所示:
class MyModel(nn.Module):
def __init__(self,opt):
self.dataloader = Dataloader(opt)
self.optimizer = optim.Adam(self.parameters(),lr=0.001)
self.lr = opt.lr
self.model = make_model()
def forward(self,input):
pass
def train_(self):
# 训练模型
for epoch in range(opt.max_epoch)
for ii,data in enumerate(self.dataloader):
self.train_step(data)
model.save()
def train_step(self):
pass抑或是专门设计一个Trainer对象,形如:
import heapq
from torch.autograd import Variable
class Trainer(object):
def __init__(self, model=None, criterion=None, optimizer=None, dataset=None):
self.model = model
self.criterion = criterion
self.optimizer = optimizer
self.dataset = dataset
self.iterations = 0
def run(self, epochs=1):
for i in range(1, epochs + 1):
self.train()
def train(self):
for i, data in enumerate(self.dataset, self.iterations + 1):
batch_input, batch_target = data
self.call_plugins('batch', i, batch_input, batch_target)
input_var = Variable(batch_input)
target_var = Variable(batch_target)
plugin_data = [None, None]
def closure():
batch_output = self.model(input_var)
loss = self.criterion(batch_output, target_var)
loss.backward()
if plugin_data[0] is None:
plugin_data[0] = batch_output.data
plugin_data[1] = loss.data
return loss
self.optimizer.zero_grad()
self.optimizer.step(closure)
self.iterations += i还有一些人喜欢模仿keras和scikit-learn的设计,设计一个fit接口。
对读者来说,这些处理方式很难说哪个更好或更差,找到最适合自己的方法才是最好的。