FFC-SE: Fast Fourier Convolution for Speech Enhancement
[arXiv:2204.03042v1]
Motivation
谱图相位的直接估计是一个挑战。为此,提出各种解决办法。这些方法包括解耦幅度和相位估计,以及使用单独的网络进行波形合成。然而,这些方法倾向于使用大型神经网络,需要大量的计算资源。从而发现这些网络的局部感受野是相位预测的限制因素之一,阻碍了模型参数的有效利用。本文观察到,非局部神经算子可以显著促进相位估计,导致更小的模型尺寸,同时获得更好的质量。因此,提出了一种新的基于快速傅里叶卷积(FFC)算子的神经网络结构,用于语音增强问题。
Method
A Fast fourier convolution
快速傅里叶卷积(FFC)是一种神经算子,它允许在神经网络中执行非局部推理和生成。FFC首先是channel-wise 快速傅里叶变换,然后是point-wise卷积和傅里叶反变换,因此它在涉及到傅里叶变换的维度上全局影响输入张量。FFC将频道分为本地和全局分支机构。局部分支使用传统的卷积进行特征图的局部更新。全局分支对特征图进行傅里叶变换并在影响全局上下文的频谱域内进行更新。本研究中,只对特征图(对应于STFT谱图)的频率维进行傅里叶变换(见图1)。具体来说,用三个步骤实现FFC层的全局分支:


1、对输入特征图进行跨频率维的实一维快速傅里叶变换,并跨通道维连接频谱的实部和虚部:![]()
2、在频域应用卷积块(使用1 × 1卷积核):

3、应用傅里叶反变换:
![]()
式中,C、F、T分别为信道数、频率对应维、时间对应维。全局分支和本地分支通过激活的总和相互交互,如图2所示。
B FFC-AE
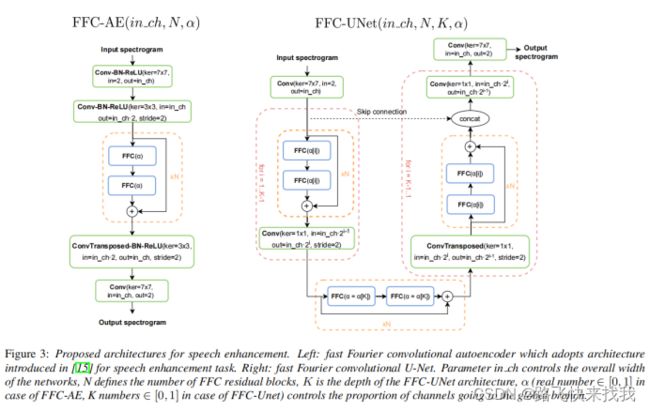
该编码器对输入频谱图进行采样,采样范围是时间和频率维度的两倍。编码器后面是一系列的残差块,每个残差块由两个顺序的快速傅里叶卷积模块组成。残差块的输出通过转置卷积进行上采样,用于预测去噪后频谱图的实部和虚部。
C FFC-UNet
将FFC层合并到U-Net架构中。在U-Net结构的每一层,利用几个剩余的FFC块与卷积上采样或下采样。研究发现参数α(进入快速傅里叶卷积全局分支的通道的比率)依赖于使用FFC的U-Net级别是有益的。
D loss
通过短时傅里叶反变换将预测的短时傅里叶变换谱图转换成波形。采用多鉴别器对抗训练框架对时域模型进行训练。它由三种loss组成,即LS-GAN损耗![]() 、特征匹配loss
、特征匹配loss ![]() 和mel-谱图损耗
和mel-谱图损耗![]() :
:
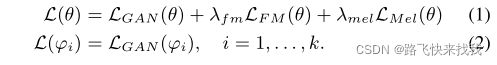
其中L(θ)表示参数为θ时生成器的loss,L(ϕi)表示参数ϕi时第i个鉴别器的loss(所有鉴别器都相同)。所有实验均设λfm = 2,λmel = 45, k = 3。
实验步骤
1)数据集1:VoiceBank-DEMAND
Train set: 28 个说话人,具有4个信噪比(15,10,5和0dB),包含11572个话语。
Test set:2个说话人,具有4个信噪比(17.5,12.5,7.5,2.5 dB),包含824个话语。
2)数据集2:Deep Noise Suppression (DNS) challenge
Train set: 使用提供的代码和默认配置合成100小时的训练数据。唯一的改进是在合成过程中不使用人工混响。
Test set:在两种测试集上进行了测试。第一个(DNS-INDOMAIN)是从合成的100小时训练数据中随机选取并排除的保留数据。第二个(DNS-BLIND)是来自DNS存储库的标准盲测测试集。
实验结果
vanilla U-Net表示的是完全卷积U-Net模型。
FFC-AE(abl.)表示的是和FFC-AE相同的模型,区别在于全局分支上的所有傅里叶卷积都被普通卷积取代。

可以看到,在Voicebank-DEMAND上,模型显著优于MOS的所有基线,并在客观指标上给出了具有竞争力的结果。在DNS基准测试上,模型比所有竞争对手考虑DNS-INDOMAIN测试集的质量更好,并且在DNS-BLIND测试集上与FullSubNet (DNS Challenge 2021中排名第一的模型之一)在MOS方面具有竞争力。

相位估计测试了FFC-AE模型在LJ-Speech数据集上估计给定幅度谱图的能力,并与具有普通卷积的类似架构进行了比较。这些模型被训练来预测相位(正弦和余弦),并提供了全幅度的光谱图。可以看到,FFC-AE明显优于FFC-AE(abl.)和vanilla U-Net,同时有更少的参数。
总结
将快速傅里叶卷积算子用于语音增强问题。观察到,在语音增强质量、相位估计和参数效率方面,建立在快速傅里叶卷积上的神经体系结构显著优于基于普通卷积的体系结构。总的来说,所提出的架构在语音降噪基准上提供了最先进的结果。
提出未来展望:考虑将结果扩展到实时流场景。相信快速傅里叶卷积的成功可以转化为其他语音处理任务,如语音转换和神经语音编码。
2022.4.15