(pytorch-深度学习系列)pytorch实现线性回归
pytorch实现线性回归
1. 实现线性回归前的准备
线性回归输出是一个连续值,因此适用于回归问题。回归问题在实际中很常见,如预测房屋价格、气温、销售额等连续值的问题。
与回归问题不同,分类问题中模型的最终输出是一个离散值。我们所说的图像分类、垃圾邮件识别、疾病检测等输出为离散值的问题都属于分类问题的范畴。softmax回归则适用于分类问题。
定义两个1000维的向量
import torch
from time import time
a = torch.ones(1000)
b = torch.ones(1000)
向量相加的一种方法是,将这两个向量按元素逐一做标量加法。如下:
start = time()
c = torch.zeros(1000)
for i in range(1000):
c[i] = a[i] + b[i]
print(time() - start)
输出:
0.02039504051208496
向量相加的另一种方法是,将这两个向量直接做矢量加法。
start = time()
d = a + b
print(time() - start) # 0.0008330345153808594
结果很明显,后者比前者更省时。因此,我们应该尽可能采用矢量计算,以提升计算效率。
定义一个房价预测问题,实例化应用场景:

我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。

在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。它在评估索引为 i 的样本误差的表达式为:

误差越小表示预测价格与真实价格越相近,且当二者相等时误差为0
我们用训练数据集中所有样本误差的平均来衡量模型预测的质量:

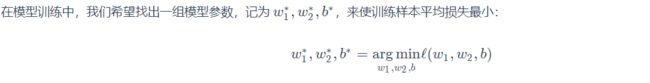
2. 线性回归的pytorch实现
导入所需的包或模块,其中的matplotlib包可用于作图,且设置成嵌入显示。
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt # matplotlib包可用于作图,且设置成嵌入显示
import numpy as np
import random
生成一个数据集:
num_inputs = 2 #特征数量
num_examples = 1000 # 数据数量,即样本数量
true_w = [2, -3.4] # 线性回归模型真实权重
true_b = 4.2 # 偏差
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
# y=k*x+b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32) # 噪声项,服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰
features的每一行是一个长度为2的向量,而labels的每一行是一个长度为1的向量(标量)
通过生成第二个特征features[:, 1]和标签 labels 的散点图,可以更直观地观察两者间的线性关系。
def use_svg_display():
# 用矢量图显示
display.set_matplotlib_formats('svg') # 设置图类型为svg图
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
set_figsize()
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1) # 注意这里将tensor转化为numpy

在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break # 读取一个batch
输出:
tensor([[-1.4239, -1.3788],
[ 0.0275, 1.3550],
[ 0.7616, -1.1384],
[ 0.2967, -0.1162],
[ 0.0822, 2.0826],
[-0.6343, -0.7222],
[ 0.4282, 0.0235],
[ 1.4056, 0.3506],
[-0.6496, -0.5202],
[-0.3969, -0.9951]])
tensor([ 6.0394, -0.3365, 9.5882, 5.1810, -2.7355, 5.3873, 4.9827, 5.7962,
4.6727, 6.7921])
我们将模型参数权重初始化成均值为0、标准差为0.01的正态随机数,偏差则初始化成0。
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们要让它们的requires_grad=True:
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
定义模型:
def linreg(X, w, b): # 矢量表达式
return torch.mm(X, w) + b
def squared_loss(y_hat, y): # 损失函数
# 注意这里返回的是向量, 另外, pytorch里的MSELoss并没有除以 2
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def sgd(params, lr, batch_size): # 优化算法:小批量随机梯度下降算法
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的是param.data
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch),然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
训练模型:
lr = 0.03 # 学习率
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期
# 在每一个迭代周期中,会使用训练数据集中所有样本一次(假设样本数能够被批量大小整除)。X
# 和y分别是小批量样本的特征和标签
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum() # l是有关小批量X和y的损失
l.backward() # 小批量的损失对模型参数求梯度
sgd([w, b], lr, batch_size) # 使用小批量随机梯度下降迭代模型参数
# 不要忘了梯度清零
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
epoch 1, loss 0.021578
epoch 2, loss 0.000096
epoch 3, loss 0.000050
输出学到的参数和用来生成训练集的真实参数:
print(true_w, '\n', w)
print(true_b, '\n', b)
[2, -3.4]
tensor([[ 1.9998],
[-3.3998]], requires_grad=True)
4.2
tensor([4.2001], requires_grad=True)